

Introduktion till Data Mining
Här i den här artikeln kommer vi att lära oss om introduktionen till Data mining eftersom människor har gruvdrat från jorden från århundraden för att få alla typer av värdefulla material. Ibland upptäcks saker och ting under jordbruket som ingen förväntade sig hitta i första hand. Till exempel 1898, under utgrävningen av en grav för att hitta mumier i Saqqara, Egypten, hittades en träföremål som exakt liknade ett flygplan. Det är daterat tillbaka till 200 f.Kr., ungefär 2200 år sedan! Men vilken möjlig information kan vi få från en stor uppsättning data? Och även om vi börjar bryta den, finns det några chanser att få oväntade resultat från datauppsättningen? Innan det går vi in på vad som exakt är Data Mining.
Vad är Data Mining?
- Det är i princip utvinning av viktig information / kunskap från en stor uppsättning data.
- Tänk på data som en stor mark / stenig yta. Vi vet inte vad som finns inne i det, vi vet inte om det finns något användbart under klipporna.
- I den här introduktionen till Data mining letar vi efter dold information men utan någon aning om vilken typ av information vi vill hitta och vad vi planerar att använda den en gång hittar vi den.
- Precis som i konceptet traditionell gruvdrift, finns det också inom Data mining olika tekniker och verktyg, som varierar beroende på vilken typ av data vi bryter, så vi har klargjort att vad som är data mining genom detta ämne för introduktion till Data mining.
Exempel på Data Mining
Vi har lärt oss introduktionen till data mining i avsnittet ovan och fortsätter nu med exemplen på data mining, som listas nedan:
- Så det finns en mobilnätoperatör. De konsulterar en datavetare för att gräva i operatörens samtalsposter. Inga specifika mål ges till Data Miner.
- Ett kvantitativt mål att hitta minst 2 nya mönster på en månad ges.
- När datorminearbetaren börjar gräva i uppgifterna finner han ett mönster att det är mindre internationella samtal på onsdag jämfört med andra dagar.
- Denna information delas med ledningen och de tar upp planen att sänka de internationella samtalskurserna på onsdagar och starta en kampanj.
- Samtalspriserna ökar, kunderna är nöjda med lågt samtalspris, fler kunder registrerar sig och företaget tjänar mer pengar! Vinn-vinn situation!
Med tanke på ovanstående exempel, låt oss nu undersöka de olika stegen som är involverade i datainsamling.
Steg involverade i Data Mining
Vi har lärt oss introduktionen till data mining i ovanstående avsnitt och går nu vidare med de steg som är involverade i data mining, som listas nedan: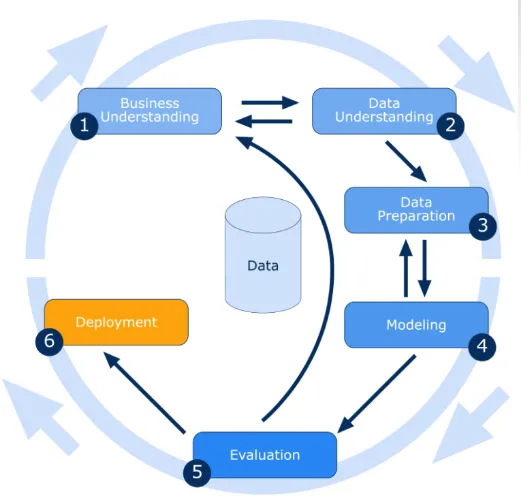
-
Affärsförståelse
I den här introduktionen till data mining kommer vi att förstå alla aspekter av affärsmålen och behoven. Den nuvarande situationen bedöms genom att hitta resurser, antaganden och andra viktiga faktorer. Följaktligen upprättande av en bra introduktion till plan för datakommunikation för att uppnå både affärs- och datalagringsmål.
-
Dataförståelse
Ursprungligen samlas uppgifterna från alla tillgängliga källor. Sedan väljer vi den bästa datauppsättningen där vi kan extrahera de data som kan vara mer fördelaktiga.
-
Förberedelse av data
När datauppsättningen har identifierats väljs den, rengörs, konstrueras och formateras i önskad form.
-
Datamodellering
Det är en process för ombyggnad av givna data enligt användarens krav. en eller flera modeller kan skapas i den förberedda datamängden och slutligen måste modellerna utvärderas noggrant med berörda parter för att se till att skapade modeller uppfyller affärsinitiativ.
-
Utvärdering
Det här är en av de mest nödvändiga processerna inom Data mining. Det inkluderar att gå igenom alla aspekter av processen för att kontrollera eventuella fel eller dataläckage i processen. Dessutom kan nya affärskrav höjas på grund av de nya upptäckta mönstren.
-
Spridning
Det betyder att helt enkelt presentera kunskapen på ett sådant sätt att intressenterna kan använda den när de vill ha den. I vårt exempel ovan konstaterades att internationella samtal var mindre på onsdagar, så denna information presenterades för intressenterna som i sin tur använde denna information till sin fördel och ökade deras vinster.
Tekniker som används vid dataanläggning
I avsnittet ovan har vi lärt oss om introduktionen till data mining nu fortsätter vi med de tekniker som används i data mining som listas nedan:
-
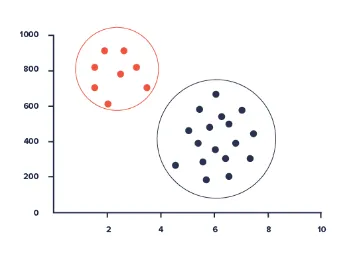
Klusteranalys
Cluster Analys gör det möjligt att identifiera en given användargrupp enligt vanliga funktioner i en databas. Dessa funktioner kan inkludera ålder, geografisk plats, utbildningsnivå och så vidare.
-
Anomali upptäckt
Det används för att bestämma när något märkbart skiljer sig från det vanliga mönstret. Det används för att eliminera eventuella inkonsekvenser i databasen eller avvikelser vid källan.

-
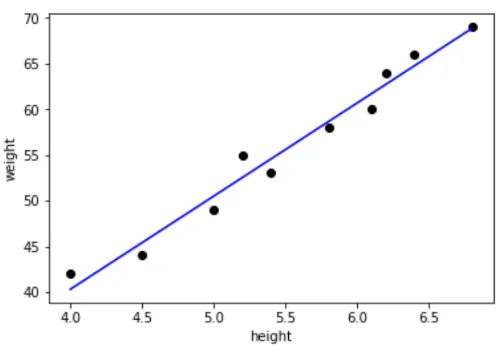
Regressionsanalys
Denna teknik används för att göra förutsägelser baserade på förhållanden inom datauppsättningen. Till exempel kan man förutsäga lagerhastigheten för en viss produkt genom att analysera tidigare hastighet och även ta hänsyn till de olika faktorerna som bestämmer lagerhastigheten. Eller som visas nedan, om vi har uppgifterna om olika personers höjd och vikt, och med tanke på någon av höjder eller vikt kan vi bestämma det andra värdet.
-
Klassificering
Detta handlar om de saker som har etiketter på den. Observera vid klusterdetektering, sakerna hade inte en etikett i och genom att använda data mining var vi tvungna att märka och forma till kluster, men i klassificering finns det information som finns som lätt kan klassificeras med hjälp av en algoritm. Ett exempel är skräppostfilter via e-post. Spamfiltret har både relevanta och skräppostmeddelanden (träningsdata). Skillnaderna mellan dem båda identifieras så att de kan klassificera framtida e-postmeddelanden korrekt.

- Associerande lärande
Det används för att analysera vilka saker som tenderar att inträffa tillsammans antingen i par eller större grupper. Till exempel människor som tenderar att köpa citroner, köpa apelsiner också, människor som tenderar att köpa bröd, köpa mjölk också och så vidare. Så inköpen som gjorts av alla kunder analyseras och de saker som sker tillsammans placeras i närheten för att öka försäljningen. Så mjölk placeras nära bröd, citroner placeras bredvid apelsiner och så vidare.

Är Data Mining etiskt?
Så jag planerar att resa till Goa med en vän, jag söker på internet efter bra ställen att besöka i Goa. Nästa gång jag öppnar internet hittar jag annonser om olika hotell i Goa för vistelse.
-
Bra sak?
Ja, internet har hjälpt mig att förenkla min resa. När allt kommer omkring, om jag bestämmer mig för att besöka Goa, skulle jag behöva sova någonstans och en annons som visar mig ett hotell är mycket mer användbar än en annons som visar mig slumpmässiga kläder att köpa.
-
Dålig sak?
ja! Varför skulle ett datagruvföretag som jag aldrig har hört förut veta vart jag ska på semester. Tänk om jag inte har berättat någon om denna resa, men här vet internet plötsligt att jag åker dit. Sanningen är att affärsmodellen för datalagringsföretaget beror på detta. De samlar in dessa uppgifter via kakor och skript, sedan säljer de dem till annonsörer som i sin tur försöker sälja mig något annat (i detta fall ett hotellrum).
Så det kan vara bra eller dåligt beroende på hur vi tittar på det. Vi kan också stänga av cookies eller gå inkognito i ovanstående fall. Men vad som än är fallet är en sak säker. Data mining är här för att stanna.
Rekommenderade artiklar
Detta har varit en guide till Introduktion till data mining. Här diskuterar vi dess betydelse, tekniker och steg involverade i introduktionen till data mining med ett exempel för att förstå bättre. Du kan också titta på följande artiklar för att lära dig mer -
- Intervju för datainriktning
- Predictive Analytics vs Data Mining
- Introduktion till datavetenskap
- Vad är regressionsanalys?