

Introduktion till AWS EMR
AWS EMR tillhandahåller många funktioner som underlättar för oss, några av teknologierna är:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
En av de viktigaste tjänsterna som tillhandahålls av AWS EMR och vi kommer att ta itu med är Amazon EMR.
EMR som ofta kallas Elastic Map Reduce kommer med ett enkelt och lättillgängligt sätt att hantera behandlingen av större bitar data. Föreställ dig ett big data-scenario där vi har en enorm mängd data och vi utför en uppsättning operationer över dem, säger ett Map-Reduce-jobb körs, en av de största problemen som Bigdata-applikationen står inför är att ställa in programmet, vi har ofta svårt att finjustera vårt program på ett sådant sätt att all tilldelad resurs förbrukas korrekt. På grund av denna ovanstående inställningsfaktor ökar tiden som tas för behandling gradvis. Elastic Map Minska tjänsten av Amazon, är en webbtjänst som ger en ram som hanterar alla dessa nödvändiga funktioner som behövs för Big data-behandling på ett kostnadseffektivt, snabbt och säkert sätt. Från klusterskapande till datadistribution över olika fall hanteras alla dessa saker enkelt under Amazon EMR. Tjänsterna här är on-demand betyder att vi kan styra siffrorna baserat på de data vi har som gör om det är kostnadseffektivt och skalbart.
Skäl för att använda AWS EMR
Så varför använder man AMR vad gör det bättre från andra. Vi stöter ofta på ett väldigt grundläggande problem där vi inte kan tilldela alla tillgängliga resurser över klustret till någon applikation, AMAZON EMR tar hand om dessa problem och baserar sig på storleken på data och efterfrågan på applikation som den allokerar nödvändig resurs. Genom att vara elastisk till sin natur kan vi ändra det i enlighet därmed. EMR har enormt applikationsstöd vare sig det Hadoop, Spark, HBase som gör det enklare för databehandling. Det stöder olika ETL-operationer snabbt och kostnadseffektivt. Det kan också användas för MLIB i Spark. Vi kan utföra olika maskininlärningsalgoritmer inuti den. Vare sig det är gruppdata eller realtidströmning av data EMR kan organisera och bearbeta båda typer av data.
Arbetar med AWS EMR
Låt oss nu se detta diagram över Amazon EMR-klustret och försöker förstå hur det faktiskt fungerar:
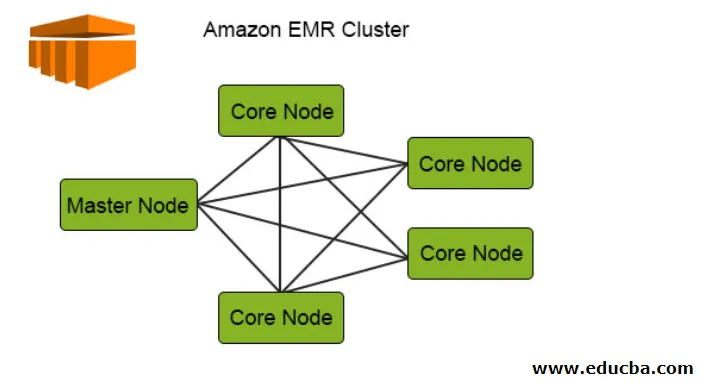
Följande diagram visar klusterfördelningen av EMR inuti. Låt oss kontrollera det i detalj:
1. Klusteren är den centrala komponenten i Amazon EMR-arkitekturen. De är en samling EC2-instanser som heter Noder. Varje nod har sina specifika roller inom klustret benämnd Node-typ och baserat på deras roller kan vi klassificera dem i tre typer:
- Master Node
- Kärnnod
- Uppgiftsnod
2. Huvudnoden som namnet antyder är masteren som är ansvarig för att hantera klustret, köra komponenterna och distribuera data över noderna för bearbetning. Det håller bara spår om allt är korrekt hanterat och fungerar bra och fungerar vid fel.
3. Kärnnoden har ansvaret för att köra uppgiften och lagra data i HDFS i klustret. Alla behandlingsdelar hanteras av kärnnoden och data efter det att behandlingen placeras på önskad HDFS-plats.
4. Uppgiftsnoden som är valfri har bara jobbet att köra uppgiften, detta lagrar inte data i HDFS.
5. När vi har skickat ett jobb har vi flera metoder för att välja hur arbetena ska slutföras. Att vara det från uppsägning av klustret efter avslutad jobb till ett långtgående kluster med EMR-konsol och CLI för att skicka steg vi har alla förmånen att göra det.
6. Vi kan direkt köra jobbet på EMR genom att ansluta det till huvudnoden genom de gränssnitt och tillgängliga verktyg som kör jobb direkt i klustret.
7. Vi kan också köra våra data i olika steg med hjälp av EMR, allt vi behöver göra är att skicka in ett eller flera ordnade steg i EMR-klustret. Data lagras som en fil och behandlas på ett sekventiellt sätt. Genom att starta det från "Väntande tillstånd till slutfört tillstånd" kan vi spåra behandlingsstegen och hitta felen också att det är från 'Det gick inte att avbrytas'. Alla dessa steg kan lätt spåras tillbaka till detta.
8. När alla instanser har avslutats uppnås det slutförda tillståndet för klustret.
Arkitektur för AWS EMR
EMR: s arkitektur introducerar sig från startlagringsdelen till applikationsdelen.
- Det allra första lagret kommer med lagringslagret som innehåller olika filsystem som används i vårt kluster. Var det är från HDFS till EMRFS till lokalt filsystem, alla används för datalagring över hela applikationen. Cachning av mellanresultaten under MapReduce-bearbetning kan uppnås med hjälp av dessa tekniker som kommer med EMR.
- Det andra lagret levereras med Resurshantering för klustret, detta lager ansvarar för resurshantering för klustren och noderna över applikationen. Detta hjälper i grund och botten som hanteringsverktyg som hjälper dig att jämnt distribuera data över kluster och korrekt hantering. Standardresurshanteringsverktyget som EMR använder är YARN som introducerades i Apache Hadoop 2.0. Den hanterar centralt resurserna för flera databehandlingsramar. Den tar hand om all information som krävs för att klustret ska fungera väl, från nodhälsa till resursfördelning med minneshantering.
- Det tredje lagret kommer med databehandlingsramen, detta lager ansvarar för analysen och behandlingen av data. det finns många ramverk som stöds av EMR som spelar en viktig roll i parallell och effektiv databehandling. Några av de ramar som den stöder och vi är medvetna om är APACHE HADOOP, SPARK, SPARK STREAMING, etc.
- Det fjärde lagret levereras med applikationen och program som HIVE, PIG, streaming-bibliotek, ML-algoritmer som är användbara för bearbetning och hantering av stora datamängder.
Fördelar med AWS EMR
Låt oss nu kolla några av fördelarna med att använda EMR:
- Hög hastighet: Eftersom alla resurser utnyttjas korrekt är Behandlingstiden för frågan relativt snabbare än de andra databehandlingsverktygen har en mycket tydlig bild.
- Bulkdatabehandling: Var större, datastorleken EMR har kapacitet att behandla enorma datamängder på god tid.
- Minimalt dataförlust: Eftersom data distribueras över klustret och behandlas parallellt över nätverket finns det en minsta chans för dataförlust och väl är noggrannhetsgraden för de bearbetade data bättre.
- Kostnadseffektivt: Att vara kostnadseffektivt är det billigare än något annat tillgängligt alternativ som gör det starkt över branschens användning. Eftersom prissättningen är mindre kan vi rymma över stora mängder data och kan behandla dem inom budgeten.
- AWS Integrated: Det är integrerat med alla tjänster från AWS som gör det lättillgängligt under ett tak så att säkerhet, lagring, nätverk allt är integrerat på ett ställe.
- Säkerhet: Det kommer med en fantastisk säkerhetsgrupp för att kontrollera inkommande och utgående trafik, och användningen av IAM-roller gör det säkrare eftersom det finns olika behörigheter som gör data säkra.
- Övervakning och distribution: vi har lämpliga övervakningsverktyg för alla applikationer som körs över EMR-kluster som gör det öppet och enkelt att analysera. Det kommer också med en automatisk distributionsfunktion där applikationen konfigureras och distribueras automatiskt.
Det finns mycket fler fördelar med att ha EMR som ett bättre val av andra klusterberäkningsmetoder.
AWS EMR-prissättning
EMR kommer med en fantastisk prislista som lockar utvecklare eller marknaden mot den. Eftersom det har en on-demand prissättningsfunktion kan vi använda den drygt en timme och antalet noder i vårt kluster. Vi kan betala för en ränta per sekund för varje sekund vi använder med en minut som ett minimum. Vi kan också välja våra instanser som ska användas som reserverade instanser eller spotinstanser, där platsen är mycket kostnadsbesparande.
Vi kan beräkna den totala fakturan via en enkel månadskalkylator från länken nedan: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
För mer information om de exakta prisuppgifterna kan du hänvisa till dokumentet nedan av Amazon: -
https://aws.amazon.com/emr/pricing/
Slutsats
Från ovanstående artikel såg vi hur EMR kan användas för rättvis behandling av big data med alla resurser som används konventionellt.
Att ha EMR löser vårt grundläggande problem med databehandling och minskar mycket behandlingstiden med ett bra antal, eftersom det är kostnadseffektivt är det enkelt och bekvämt att använda.
Rekommenderad artikel
Detta har varit en guide till AWS EMR. Här diskuterar vi en introduktion till AWS EMR längs dess Working and the Architecture såväl som fördelarna. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- AWS-alternativ
- AWS-kommandon
- AWS-tjänster
- AWS intervjufrågor
- AWS Storage Services
- Topp 7 konkurrenter av AWS
- Lista över Amazon Web Services-funktioner