
Introduktion till datavetenskapens livscykel
Data Science Lifecycle handlar om att använda maskininlärning och andra analysmetoder för att producera insikter och förutsägelser från data för att uppnå ett affärsmål. Hela processen involverar flera steg som rengöring av data, förberedelser, modellering, modellutvärdering, etc. Det är en lång process och kan ta flera månader att slutföra. Så det är mycket viktigt att ha en allmän struktur att följa för alla problem som finns. Den globalt erkända strukturen för att lösa alla analytiska problem kallas som Cross Industry Standard Process for Data Mining eller CRISP-DM-ramverk.
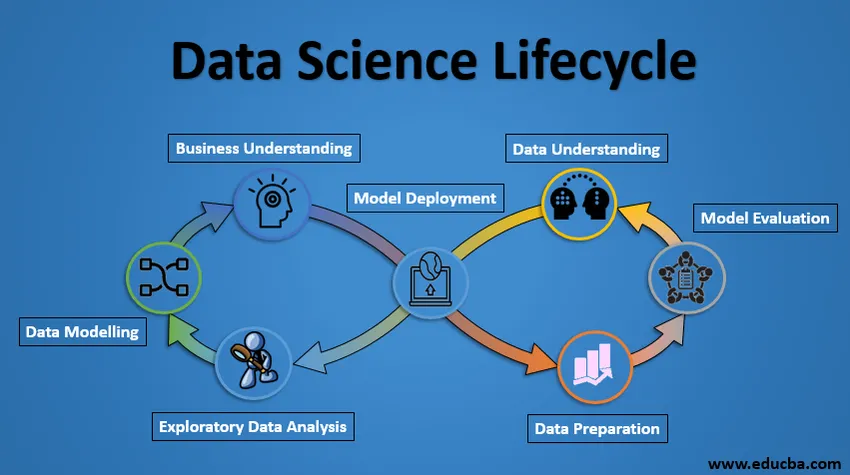
Livscykel för datavetenskap
Nedan visas projektets livscykel för datavetenskap.
1. Affärsförståelse
Hela cykeln kretsar kring affärsmålet. Vad kommer du att lösa om du inte har ett exakt problem? Det är oerhört viktigt att förstå affärsmålet tydligt eftersom det kommer att vara ditt slutmål för analysen. Efter korrekt förståelse kan vi bara ställa in det specifika målet för analys som är synkroniserat med affärsmålet. Du måste veta om klienten vill minska kreditförlusten, eller om de vill förutsäga priset på en vara etc.
2. Dataförståelse
Efter affärsförståelse är nästa steg dataförståelse. Detta innebär att alla tillgängliga data samlas in. Här måste du arbeta nära med företagsteamet eftersom de faktiskt är medvetna om vilka data som finns, vilka data som kan användas för detta affärsproblem och annan information. Detta steg innebär att beskriva uppgifterna, deras struktur, deras relevans, deras datatyp. Utforska data med hjälp av grafiska diagram. I grund och botten, extrahera all information som du kan få om uppgifterna genom att bara utforska uppgifterna.
3. Förberedelse av data
Därefter kommer dataförberedelsestadiet. Detta inkluderar steg som att välja relevant data, integrera informationen genom att slå samman datasätten, rengöra dem, behandla de saknade värdena genom att antingen ta bort dem eller beräkna dem, behandla felaktiga data genom att ta bort dem, kolla också om utdelare använder ruta tomter och hantera dem . Konstruera ny data, hämta nya funktioner från befintliga. Formatera data i önskad struktur, ta bort oönskade kolumner och funktioner. Datapreparation är det mest tidskrävande men ändå utan tvekan det viktigaste steget i hela livscykeln. Din modell kommer att vara lika bra som dina data.
4. Förklarande dataanalys
Detta steg innebär att du får en idé om lösningen och faktorer som påverkar den, innan du bygger själva modellen. Fördelning av data inom olika variabler av en funktion utforskas grafiskt med stapeldiagram, förhållanden mellan olika funktioner fångas genom grafiska representationer som spridningsdiagram och värmekartor. Många andra datavisualiseringstekniker används i stor utsträckning för att utforska varje funktion individuellt och genom att kombinera dem med andra funktioner.
5. Datamodellering
Datamodellering är hjärtat i dataanalys. En modell tar de förberedda data som inmatning och ger den önskade utgången. Detta steg inkluderar att välja lämplig typ av modell, vare sig problemet är ett klassificeringsproblem, eller ett regressionsproblem eller ett klusterproblem. Efter att vi har valt modellfamiljen, bland de olika algoritmerna bland den familjen, måste vi noggrant välja algoritmerna för att implementera och implementera dem. Vi måste ställa in hyperparametrarna för varje modell för att uppnå önskad prestanda. Vi måste också se till att det finns en korrekt balans mellan prestanda och generaliserbarhet. Vi vill inte att modellen ska lära sig uppgifterna och prestera dåligt med ny data.
6. Utvärdering av modeller
Här utvärderas modellen för att kontrollera om den är redo att användas. Modellen testas på en osynlig data, utvärderas på en noggrant genomtänkt uppsättning utvärderingsmätvärden. Vi måste också se till att modellen överensstämmer med verkligheten. Om vi inte uppnår ett tillfredsställande resultat i utvärderingen, måste vi ändra hela modelleringsprocessen tills den önskade nivån av mätvärden har uppnåtts. Varje datavetenskaplig lösning, en maskininlärningsmodell, precis som en människa, bör utvecklas, borde kunna förbättra sig själv med nya data, anpassa sig till en ny utvärderingsmetrik. Vi kan bygga flera modeller för ett visst fenomen, men många av dem kan vara ofullkomliga. Modellutvärdering hjälper oss att välja och bygga en perfekt modell.
7. Model Deployment
Modellen efter en rigorös utvärdering distribueras slutligen i önskat format och kanal. Detta är det sista steget i datavetenskapens livscykel. Varje steg i datavetenskapens livscykel som förklaras ovan bör arbetas noggrant. Om något steg utförs felaktigt kommer det följaktligen att påverka nästa steg och hela ansträngningen går till spill. Om data till exempel inte samlas in korrekt förlorar du information och du kommer inte att bygga en perfekt modell. Om data inte rengörs ordentligt fungerar modellen inte. Om modellen inte utvärderas korrekt kommer den att misslyckas i den verkliga världen. Från affärsförståelse till modellinstallation bör varje steg ges uppmärksamhet, tid och ansträngning.
Rekommenderade artiklar
Detta är en guide till datavetenskapens livscykel. Här diskuterar vi en översikt över datavetenskapens livscykel och stegen som utgör en datavetenskaplig livscykel. Du kan också gå igenom våra relaterade artiklar för att lära dig mer -
- Introduktion till datavetenskapliga algoritmer
- Data Science vs Software Engineering | Topp 8 användbara jämförelser
- Skillnadstyper datavetenskapstekniker
- Datavetenskapliga färdigheter med typer