

Introduktion till RDBMS-intervjufrågor och svar
Så om du förbereder dig för en jobbintervju i RDBMS. Jag är säker på att du vill veta de vanligaste RDBMS-intervjufrågorna från 2019 och svar som hjälper dig att knäcka RDBMS-intervjun med lätthet. Nedan är listan över de bästa RDBMS-intervjuerna och svaren till din undsättning.
Därför tenderar vi att lägga till topp 2019 RDBMS intervjufrågor som ställs mestadels i en intervju
1. Vad är olika funktioner i en RDBMS?
Svar:
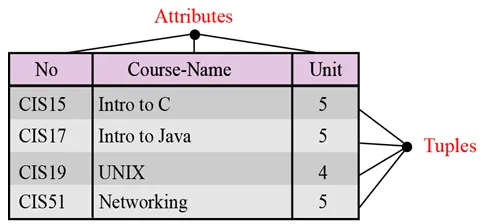
Namn. Varje relation i en relationsdatabas bör ha ett namn som är unikt bland alla andra relationer.
Attribut. Varje kolumn i en relation kallas ett attribut.
Tupler. Varje rad i en relation kallas en tupel. En tupel definierar en samling attributvärden.
2.Explain ER-modell?
Svar:
ER-modellen är en enhet för enhetsrelationer. ER-modellen bygger på en verklig värld som består av enheter och relationsobjekt. Enheter illustreras i en databas med en uppsättning attribut.
3. Definiera objektorienterad modell?
Svar:
Objektorienterad modell bygger på samlingar av objekt. Ett objekt rymmer värden som lagras i instansvariabler inuti objektet. Objekt med samma typ av värden och exakt samma metoder grupperas i klasser.
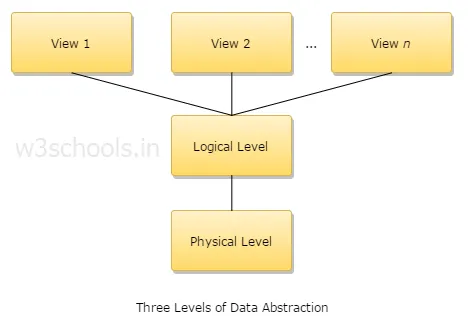
4. Förklara tre nivåer av dataabstraktion?
Svar:
1. Fysisk nivå: Detta är den lägsta abstraktionsnivån och den beskriver hur data lagras.
2. Logisk nivå: Nästa abstraktionsnivå är logisk, den beskriver vilken typ av data som lagras i en databas och vad som är förhållandet mellan dessa data.
3. Visningsnivå: Den högsta abstraktionsnivån och den beskriver den enda hela databasen.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5. Vad är olika Codds 12 regler för relationsdatabas?
Svar:
Codds 12 regler är en uppsättning av tretton regler (numrerade noll till tolv) föreslagna av Edgar F. Codd.
Codds regler: -
Regel 0: Systemet måste kvalificera sig som relationellt, som en databas och även som ett styrsystem.
Regel 1: Informationsregeln: Varje information i databasen ska representeras unikt, främst namnvärden i kolumnpositioner i en annan rad i en tabell.
Regel 2: Den garanterade åtkomstregeln: Alla uppgifter måste vara ingressiva. Det säger att varje skalvärde i databasen måste vara korrekt / logiskt adresserbar.
Regel 3: Systematisk behandling av nollvärden: DBMS måste tillåta varje tupel att förbli noll.
Regel 4: Aktiv online-katalog (databasens struktur) baserad på relationsmodellen: Systemet måste stödja en online, relationell etc. struktur som är ingressiv för tillåtna användare med hjälp av deras vanliga fråga.
Regel 5: Den omfattande underversionen av data: Systemet måste hjälpa minst ett relationellt språk som:
1.Har en linjär syntax
2. Vilken kan användas både interaktivt och inom applikationsprogram,
3.Det stöder data definition operationer (DDL), data manipulation operations (DML), säkerhets- och integritetsbegränsningar och transaktionshanteringsoperationer (börja, begå och återuppspelning).
Regel 6: Uppdateringsregeln för vyer : Alla vyer som teoretiskt förbättras måste uppgraderas av systemet.
Regel 7: Infoga, uppdatera och radera på hög nivå: Systemet måste stödja operatörer för att infoga, uppdatera och radera.
Regel 8: Fysisk datainständighet: Ändra den fysiska nivån (hur informationen lagras, med hjälp av matriser eller länkade listor etc.) får inte kräva någon ändring av en applikation.
Regel 9: Logisk datainständighet: Ändra den logiska nivån (tabeller, kolumner, rader etc.) får inte kräva någon ändring av en applikation.
Regel 10: Integritetsoberoende: Integritetsbegränsningar måste identifieras separat från applikationsprogram och lagras i katalogen.
Regel 11: Distributionens oberoende: Distributionen av delar av en databas till olika platser bör inte vara synlig för användare av databasen.
Regel 12: Nonsubversionsregeln: Om systemet tillhandahåller ett gränssnitt med låg nivå (dvs poster), kan det gränssnittet inte användas för att subvertera systemet.
6. Vad är normalisering? och vad som förklarar olika normaliseringsformer.
Svar:
Normalisering av databaser är en process för att organisera data för att minimera dataredundans. Vilket i sin tur säkerställer datakonsistens. Det finns många problem som är förknippade med dataredundans, t.ex. hårddiskavfall, datakonsekvens, DML-frågor (Data Manipulation Language) blir långsamma. Det finns olika normaliseringsformer: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Uppgifterna i varje kolumn ska vara flera atomiska antalet värden separerade med komma. Tabellen innehåller inga upprepande kolumngrupper. Identifiera varje post unikt med den primära nyckeln.
2. 2NF: - Tabellen ska matcha alla villkor för 1NF och flytta redundanta data till separat tabell. Dessutom skapar det en relation mellan dessa tabeller med hjälp av främmande nycklar.
3. 3NF: - för en 3NF-tabell ska uppfylla alla villkor för 1NF och 2NF. 3NF innehåller inte attribut som är delvis beroende av primärnyckel.
7. Definiera primärnyckel, utländsk nyckel, kandidatnyckel, supernyckel?
Svar:
Primär nyckel: primär nyckel är nyckeln som inte tillåter duplicerade värden och nollvärden. En primär nyckel kan definieras på kolumnnivå eller tabellnivå. Endast en primär nyckel per tabell är tillåten.
Utländsk nyckel: utländsk nyckel tillåter endast värden som finns i den refererade kolumnen. Det tillåter dubbla eller nollvärden. Det kan definieras som kolumnnivå eller tabellnivå. Den kan hänvisa till en kolumn med en unik / primär nyckel.
Kandidatnyckel: En kandidatnyckel är lägst supernyckel, det finns ingen korrekt undergrupp med kandidatnyckelattribut kan vara en supernyckel.
Supernyckel: En supernyckel är en uppsättning attribut för ett relationsschema på vilket alla attribut för schemat är delvis beroende. Inga två rader kan ha samma värde på supernyckelattribut.
8.Vad är en annan typ av index?
Svar:
Index är: -
Clustered index: - Det är det index där data fysiskt lagras på disken. Därför kan endast ett klusterindex skapas till en databastabell.
Icke-klusterat index: - Det definierar inte fysiska data men definierar en logisk ordning. Vanligtvis skapas B-träd eller B + -träd för detta ändamål.
9.Vad är fördelarna med RDBMS?
Svar:
• Kontrollera redundans.
• Integritet kan verkställas.
• Inkonsekvens kan undvikas.
• Data kan delas.
• Standard kan verkställas.
10. Namnge några delsystem i RDBMS?
Svar:
Input-output, Security, Language Processing, Storage Management, Logging and Recovery, Distribution Control, Transaction Control, Memory Management.
11. Vad är Buffer Manager?
Svar:
Buffer Manager lyckas samla in data från hårddisklagring till huvudminne och bestämma vilka data som ska finnas i cacheminnet för snabbare bearbetning.
Rekommenderad artikel
Detta har varit en guide till Lista över RDBMS-intervjufrågor och svar så att kandidaten lätt kan slå ned dessa RDBMS-intervjuerfrågor. Du kan också titta på följande artiklar för att lära dig mer -
- De viktigaste intervjufrågorna för Data Analytics
- 13 Fantastiska databas testa intervjufrågor och svar
- Topp 10 designmönsterintervjuer och svar
- 5 användbara SSIS-intervjufrågor och svar