

Karriär i Hadoop - Introduktion
Hadoop är inte bara ett ramverk i Big Data-världen. Det har ett brett ekosystem med ett paraply med relaterad teknik. Av samma anledning är en karriär i Hadoop lovande. Om du har en god förståelse för Hadoop-grunderna kommer det att vara en grund för stor karriär i Hadoop.
Utbildning till karriär i Hadoop
Liksom många nya datateknologier kräver Hadoop inte någon specifik utbildningsbakgrund som sådan. Cirka hälften av Hadoop-utvecklare är från icke-datavetenskapliga bakgrunder som statistik eller fysik. Så det är uppenbart att bakgrunden inte är ett hinder för att komma in i Hadoops värld förutsatt att du är redo att lära dig grunder. Det finns bra online-kurser som täcker Hadoop - den från eduCBA är det bästa exemplet - master-apache-Hadoop
Vidare, om du vill gå djupare in i ett specifikt område inom Hadoop-klusterhantering eller datamodellering i Hive-material om varje specifikt ämne som finns tillgängliga som onlinekurser och läroböcker. För det mesta kommer Hadoop-kluster att installeras i en molnleverantör som AWS eller Azure. Så bekanta dig med alla molnförsäljare du väljer kommer att hjälpa mycket. Hadoop-tjänst från AWS kallas EMR.
Populär specialisering inkluderar:
- Spark - Skalbar databehandlingsmotor i minnet
- HBase - Ingen SQL-databas ovanpå HDFS
- Beam - Streaming databearbetning av första metoden
- Pig - Data transformation (ETL) skript
- Hive - Datalagring
- Mahout, Spark MLlib - skalbar maskininlärning på Hadoop
- Apache Drill - SQL-motor på Hadoop
- Flume, Sqoop - Data Ingesting Services
- Solr & Lucene - Sökning och indexering
Karriärväg i Hadoop
Enligt resultaten från Stack Overflow Survey 2017 är Hadoop ledande inom det mest populära och mest älskade ramverket i Big Data-rymden (Survey Link). Detta är möjligt endast för att människor från olika IT-perspektiv fann Hadoop en potentiell karriärväg och vill byta.
Oavsett vad som är din nuvarande roll IT-roll kommer det att finnas en lätt anpassningsbar växling till en karriär i Hadoop-världen. Några populära exempel -
- Programvaruutvecklare (programmerare) -> Hadoop Data Developer som hanterar olika Hadoop-abstraktions-SDK: er och hämtar värde från data.
- Data Analyst -> Så du är skicklig i SQL. Stor möjlighet i Hadoop att arbeta på SQL-motorer som Hive eller Impala
- Business Analyst -> Organisationer som försöker bli mer lönsamma med massivt insamlade data och roll för en affärsanalytiker är avgörande i detta.
- ETL Developer -> Om du arbetar som en traditionell ETL-utvecklare kan du enkelt byta till Hadoop ETL med hjälp av verktyg som Spark.
- Testare -> Det finns en stor efterfrågan på testare i Hadoop-världen. Genom att förstå grunderna i Hadoop och dataprofilering kan alla testare byta till denna roll.
- BI / DW-yrken -> Kan enkelt byta till Hadoop Data-arkivering till Datamodellering.
- Senior IT-proffs -> Med en djup förståelse av domänen och befintliga utmaningar i datavärlden, kan en senior professional bli konsulter genom att få kunskap om hur Hadoop försöker lösa dessa utmaningar.
- Det finns generiska roller som Data Engineers eller Big Data Engineering som ansvarar för att implementera lösningen mestadels ovanför Cloud-leverantörer. Genom att få kunskap om molnens datakomponenter kommer detta att vara en lovande roll.
Jobb positioner
Hadoop ekosystem erbjuder en mängd olika karriärvägar
- MapReduce Developer - Detta är i grunden en Java-utvecklarroll som också förstår hur Hadoop-system fungerar internt. Det finns en abstraktion som Hive eller Pig tillgängliga fortfarande MapReduce-jobb är nödvändiga för högpresterande system. MapReduce-utvecklare är den som förstår ett system in och ut och betalat riktigt högt.
- Hadoop-administratörer - Det här är personer som ansvarar för att hålla Hadoop-klustret friskt och prestera. Detta kan inkludera typiska administratörsuppgifter som vanliga systemhälsokontroller, men en majoritet av de uppgifter som behövs för att förstå Hadoop-systemarkitektur.
- Devops - Distribuera nya systemkomponenter och andra utvecklingsrelaterade förändringar i Hadoop-klustret. Ansvaret för denna roll varierar mycket och beror på organisationens kultur.
- Datautvecklare - Databehandling ovanpå Hadoop. Detta är en av de mest populära rollerna i Hadoop-ekosystemet. Personer med SQL eller analytisk bakgrund passar bäst för dessa roller. Arbeta oftast med en abstraktion på hög nivå av Hadoop som Hive eller Pig.
- Datasäkerhetsadministratör - Data är de mest värdefulla tillgångarna och att säkra dem är viktigast. Säkerhetsadministratörer säkerställer industristandardpolicyer och bästa praxis för att skydda data, med en förståelsebegränsning av ett system
- Datavisualisator - Hantera nästa generations visualiseringsverktyg som möjliggör dynamisk dataskivning och aggregering med datacaching i minnet
- ETL Developer - Transformera data för förbättring av datakvalitet eller enligt affärslogik med hjälp av Hadoop ekosystemverktyg. ETL-processen kan strömma eller vara batch.
- Systemarkitekt - Design högpresterande system med hänsyn till datatillgänglighet och hållbarhet på ett kostnadseffektivt sätt. Beror mycket på maskinvaruföretag.
- Dataarkitekt - Bortsett från traditionell logisk / fysisk design av data, kommer en hel del saker som kolumnkodning, denormalisering, partitioneringsdesign etc. att ansvara för dataarkitekt.
Rekommenderade kurser
- Online XML- och Java-utbildning
- Node.JS-kurser
- Silverlight Training Course
- Ember.JS-programmet
Lön
En genomsnittslön för en mjukvaruutvecklare i USA är 90 956 dollar per år medan den genomsnittliga lönen för Hadoop-utvecklaren är ett sätt högre - 118 234 dollar per år (Per reynd.se - ja.se)
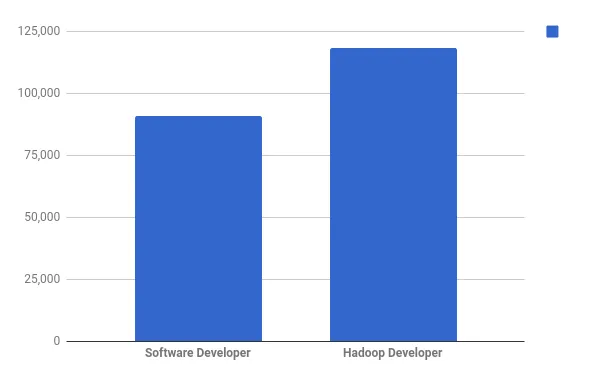
Lön till Hadoop-utvecklare i toppföretag i USA (Ref: riktigt.se)
| Äpple | 147.573 dollar per år |
| Wipro | 110.553 $ per år |
| HERO.jobs | 158 715 dollar per år |
| MBCAA | $ 133.422 per år |
| Ventures Unlimited Inc | 130 000 dollar per år |
| Nityo Infotech Services Pvt. Ltd. | 128 633 dollar per år |
| POLSTJÄRNAN | 126 370 dollar per år |
| PRI-teknik | 121.396 dollar per år |
| NITYO INFOTECH | 116 909 dollar per år |
| HortonWorks, Inc | 110 710 dollar per år |
Karriärutsikt
Hadoop-ekosystemet avviker mycket för att möta förändringar i affärsbehov. Eftersom data som genereras ökar exponentiellt och fler och fler organisationer blir datadrivna kommer Hadoop-systemet bara att öka.
Några av de anmärkningsvärda trenderna:
- Växla från batchbehandling till strömmande första databehandlingsmetod med Spark and Beam
- Mer realtidsmaskininlärningsmodell tillämpas på realtidsdata med hjälp av Spark ML
- Avkopplade SQL-motorer från datalagring som Presto ovanpå S3 för ad-hoc-analys ovanpå datasjön.
- Columnar MPP-databaser som AWS Redshift för snabb datatillgång
Eftersom en grundläggande aspekt av Big Data-behandling ligger på feltoleranta distribuerade och horisontellt skalbara system, som är väl implementerat av Hadoop, kommer Hadoop att fortsätta som ett ledande ekosystem för databehandling.
Rekommenderad artikel
Detta har varit en guide till Karriär i Hadoop. Här har vi diskuterat Introduktion, utbildning, karriärväg i Hadoop, lön och karriärutsikter i Hadoop. Du kan också titta på följande artikel för att lära dig mer -
- Azure Paas vs Iaas och deras användbara fördelar
- Ta reda på skillnaderna mellan Java vs Node JS
- Bästa expertråd för karriärer i Mainframe
- Karriärer inom SQL
- Användbara karriärer som programvaruingenjör
- Hadoop Administrator | Färdigheter och karriärväg