

Skillnaden mellan Big Data och Apache Hadoop
Allt finns på Internet. Internet har mycket data. Därför är allt Big Data. Vet du att 2, 5 Quintillion Bytes-data skapas varje dag och staplas upp som Big Data? Våra dagliga aktiviteter som kommentarer, gillar, inlägg etc. på sociala medier som Facebook, LinkedIn, Twitter och Instagram lägger till som Big Data. Det antas att år 2020 kommer nästan 1, 7 megabyte data att skapas varje sekund för varje person på jorden. Du kan föreställa dig och överväga hur mycket data som genereras förutsatt att varje enskild person på jorden. Idag är vi anslutna och delar våra liv online. De flesta av oss är anslutna online. Vi bor i ett smart hem och använder smarta fordon och alla är anslutna till våra smarta telefoner. Föreställer du dig någonsin hur dessa enheter blir smart? Jag vill ge dig väldigt enkelt svar, det är på grund av att analysera den mycket stora mängden data, dvs Big Data. Inom fem år kommer det att finnas över 50 miljarder smarta anslutna enheter i världen, alla utvecklade för att samla in, analysera och dela data för att göra våra liv bekvämare.
Följande är introduktionerna av Big Data vs Apache Hadoop
Introduktion av term Big Data
Vad är Big Data? Vilken storlek på data anses vara stor och benämns Big Data? Vi har många relativa antaganden för termen Big Data. Det är möjligt att mängden data säger 50 terabyte kan betraktas som big data för uppstart, men det kanske inte är Big Data för företag som Google och Facebook. Det beror på att de har infrastruktur för att lagra och bearbeta den mängden data. Jag skulle vilja definiera termen Big Data som:
- Big Data är datamängden precis bortom teknologins förmåga att lagra, hantera och bearbeta effektivt.
- Big Data är data vars skala, mångfald och komplexitet kräver ny arkitektur, tekniker, algoritmer och analyser för att hantera dem och utvinna värde och dold kunskap från den.
- Big data är högvolym och hög hastighet och stor variation av informationstillgångar som kräver kostnadseffektiva, innovativa former av informationsbehandling som möjliggör förbättrad insikt, beslutsfattande och processautomation.
- Big Data avser teknologier och initiativ som involverar data som är för olika, snabbt förändrade eller massiva för att konventionell teknik, färdigheter och infrastruktur ska kunna hantera effektivt. Sagt på annat sätt är volymen, hastigheten eller variationen av data för stor.
3 V av Big Data
- Volym: Volym avser mängden / mängden som data skapas som Varje timme förser Wal-Mart-kundernas transaktioner företaget med cirka 2, 5 petabyte data.
- Hastighet: Hastighet hänvisar till hur snabbt data rör sig som Facebook-användare skickar i genomsnitt 31, 25 miljoner meddelanden och tittar på 2, 77 miljoner videor varje minut varje dag över internet.
- Variation: Variety hänvisar till olika dataformat som skapas som strukturerade, semistrukturerade och ostrukturerade data. Som att skicka e-postmeddelanden med bilagan på Gmail är ostrukturerad data medan publicering av kommentarer med vissa externa länkar också benämns ostrukturerad data. Dela bilder, ljudklipp, videoklipp är en ostrukturerad form av data.
Att lagra och bearbeta denna enorma volym, hastighet och olika data är ett stort problem. Vi måste tänka på annan teknik än RDBMS för Big Data. Det beror på att RDBMS kan lagra och bearbeta endast strukturerad data. Så här kommer Apache Hadoop som en räddning.
Vi presenterar Term Apache Hadoop
Apache Hadoop är en öppen källkodsram för att lagra data och köra applikationer på kluster av hårdvara. Apache Hadoop är ett mjukvaroram som möjliggör distribuerad bearbetning av stora datamängder över kluster av datorer med enkla programmeringsmodeller. Den är utformad för att skala upp från enkla servrar till tusentals maskiner, var och en erbjuder lokal beräkning och lagring. Apache Hadoop är ett ramverk för lagring och behandling av Big Data. Apache Hadoop kan lagra och bearbeta alla dataformat som strukturerade, semistrukturerade och ostrukturerade data. Apache Hadoop är öppen källkods- och råvaruhårdvara som har revolutionerat IT-industrin. Det är lättillgängligt för alla nivåer av företag. De behöver inte investera mer för att skapa Hadoop-kluster och på olika infrastrukturer. Så låt oss se den användbara skillnaden mellan Big Data och Apache Hadoop i detalj i det här inlägget.
Apache Hadoop ramverk
Apache Hadoop-ramverket är uppdelat i två delar:
- Hadoop Distribuerat filsystem (HDFS): Det här lagret ansvarar för lagring av data.
- MapReduce: Det här lagret ansvarar för att bearbeta data på Hadoop Cluster.
Hadoop Framework är indelat i master- och slavarkitektur. Hadoop Distribution File System (HDFS) lager Namn Nod är huvudkomponent medan datanoden är slavkomponent medan i MapReduce lager är Job Tracker huvudkomponent medan task tracker är slavkomponent. Nedan visas diagrammet för Apache Hadoop ramverk.
Varför är Apache Hadoop viktigt?
- Möjlighet att snabbt lagra och behandla enorma mängder av alla slags data
- Datorstyrka: Hadoops distribuerade datormodell bearbetar big data snabbt. Ju fler datornoder du använder, desto mer processorkraft har du.
- Feltolerans: Data- och applikationsbehandling är skyddad mot maskinvarufel. Om en nod går ner, omdirigeras jobb automatiskt till andra noder för att se till att den distribuerade beräkningen inte misslyckas. Flera kopior av all data lagras automatiskt.
- Flexibilitet: Du kan lagra så mycket data du vill och bestämma hur du ska använda den senare. Det inkluderar ostrukturerade data som text, bilder och videor.
- Låg kostnad: Öppen källkodsram är gratis och använder varuhårdvara för att lagra stora mängder data.
- Skalbarhet: Du kan enkelt växa ditt system för att hantera mer data helt enkelt genom att lägga till noder. Lite administration krävs
Jämförelse mellan huvuddata och Apache Hadoop (Infographics)
Nedan visas topp 4-jämförelsen mellan Big Data vs Apache Hadoop
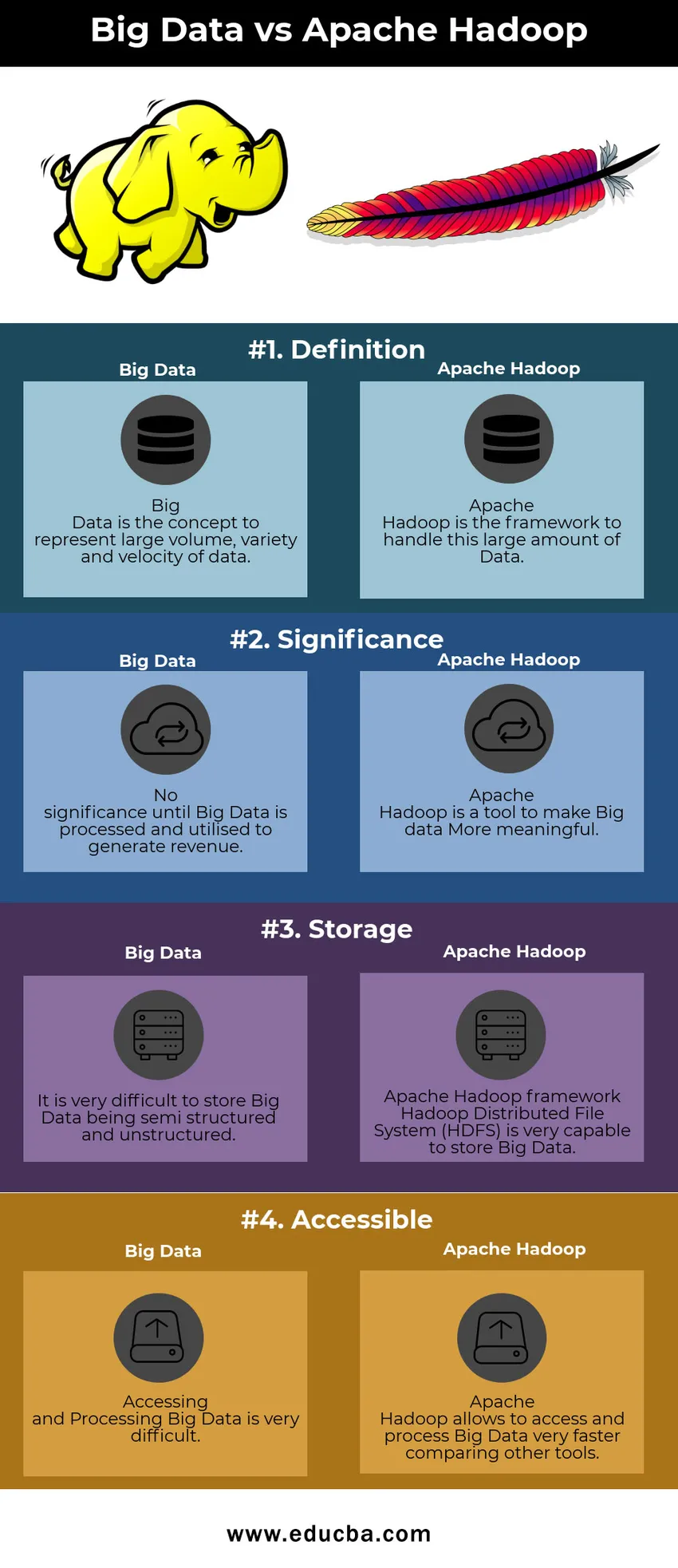
Big Data vs Apache Hadoop jämförelsetabell
Jag diskuterar stora artefakter och skiljer mellan Big Data vs Apache Hadoop
| Big Data | Apache Hadoop | |
| Definition | Big Data är konceptet för att representera stor volym, variation och hastighet på data | Apache Hadoop är ramverket för att hantera denna stora mängd data |
| Betydelse | Ingen betydelse förrän Big Data bearbetas och används för att generera intäkter | Apache Hadoop är ett verktyg för att göra Big data mer meningsfullt |
| Lagring | Det är mycket svårt att lagra Big Data som halvstrukturerad och ostrukturerad | Apache Hadoop-ramverket Hadoop Distribution File System (HDFS) är mycket kapabelt att lagra Big Data |
| Tillgänglig | Det är mycket svårt att komma åt och bearbeta Big Data | Apache Hadoop tillåter åtkomst och bearbetning av Big Data mycket snabbare jämför andra verktyg |
Slutsats - Big Data vs Apache Hadoop
Du kan inte jämföra Big Data och Apache Hadoop. Det beror på att Big Data är ett problem medan Apache Hadoop är lösning. Eftersom datamängden ökar exponentiellt i alla sektorer, så det är mycket svårt att lagra och bearbeta data från ett enda system. Så för att bearbeta denna stora mängd data behöver vi distribuerad bearbetning och lagring av data. Därför kommer Apache Hadoop med lösningen att lagra och bearbeta en mycket stor mängd data. Slutligen kommer jag att dra slutsatsen att Big Data är en stor mängd komplexa data medan Apache Hadoop är en mekanism för att lagra och bearbeta Big Data mycket effektivt och smidigt.
Rekommenderad artikel
Detta har varit en guide till Big Data vs Apache Hadoop, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. den här artikeln består av all användbar skillnad mellan Big Data och Apache Hadoop. Du kan också titta på följande artiklar för att lära dig mer -
- Big Data vs Data Science - Hur skiljer de sig?
- Topp 5 Big Data-trender som företag kommer att behöva behärska
- Hadoop vs Apache Spark - Intressanta saker du behöver veta
- Apache Hadoop vs Apache Spark | Topp 10 jämförelser du måste känna till!