

Introduktion till Python Pandas DataFrame
Flera utvidgningar för Python-biblioteket, Pandas, kan hittas online. En sådan är paneldata (pan) data (das). Det här ordet * Panel * antyder subtilt en 2-dimensionell datastruktur som finns i detta bibliotek, vilket ger sina användare enormt stöd. Den här strukturen kallas en DataFrame.
Det är i huvudsak en matris med rader och kolumner, som innehåller hela datasatsen, med mycket detaljerade alternativ för att indexera samma. DataFrame (DF), kan föreställas bildligt liknar ett excel-ark. Men det som gör det kraftfullt är hur enkelt analys- och transformationsoperationer kan utföras på data lagrade i en DataFrame.
Vad är exakt en Python Pandas DataFrame?
Pydata-sidan kan hänvisas till något av en officiell definition.
Om den förstås korrekt, nämner den DataFrame som en kolumnstruktur, som kan lagra alla pythonobjekt (inklusive ett DataFrame själv) som ett cellvärde. (En cell indexeras med en unik kombination av rad och kolumner)
DataFrames består av tre väsentliga komponenter: data, rader och kolumner.
- Data: Det hänvisar till de faktiska objekten / enheterna lagrade i en cell i DataFrame och värdena som representeras av dessa enheter. Ett objekt är av alla giltiga python-datatyper, antingen inbyggda eller användardefinierade.
- Rader: Referenser som används för att identifiera (eller indexera) en viss uppsättning observationer från den fullständiga informationen som lagras i en DataFrame kallas Raderna. Bara för att göra det tydligt representerar det de använda indexen och inte bara uppgifterna i en viss observation.
- Kolumner: Referenser som används för att identifiera (eller indexera) ett setattribut för alla observationer i en DataFrame. Liksom när det gäller rader hänvisar dessa till kolumnindex (eller kolumnrubriker) istället för bara data i kolumnen.
Så utan någon annan anledning, låt oss prova några sätt att skapa dessa oerhört kraftfulla strukturer.
Steg för att skapa Python Pandas DataFrames
En Python Pandas DataFrame kan skapas med följande kodimplementering,
1. Importera pandor
För att skapa DataFrames måste pandabiblioteket importeras (ingen överraskning här). Vi kommer att importera det med ett alias pd för att enkelt referera objekt under modulen.
Koda:
import pandas as pd
2. Skapa det första DataFrame-objektet
När biblioteket har importerats finns alla metoder, funktioner och konstruktörer tillgängliga i ditt arbetsområde. Så låt oss försöka skapa en vanilj DataFrame.
Koda:
import pandas as pd
df = pd.DataFrame()
print(df)
Produktion:
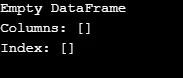
Som visas i utgången returnerar konstruktören en tom DataFrame.
Låt oss nu fokusera på att skapa DataFrames från data lagrade i några av de troliga representationerna.
- DataFrame från A Dictionary: Låt oss säga att vi har en ordlista som lagrar en lista över företag inom Software Domain och antalet år de har varit aktiva.
Koda:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Låt oss se representationen av det returnerade DataFrame-objektet genom att skriva ut det på konsolen.
Produktion:

Som kan ses behandlas varje nyckel i ordboken som en kolumn i DataFrame, och radindex genereras automatiskt med början från 0. Ganska enkelt va!
Låt oss nu säga att du ville ge det ett anpassat index istället för 0, 1, .. 4. Du behöver bara skicka önskad lista som en parameter till konstruktören och pandaer kommer att göra det nödvändiga.
Koda:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Produktion:
Företagets ålder
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Nu kan du ställa radindex till önskat värde.
- DataFrame från en CSV-fil: Låt oss skapa en CSV-fil som innehåller samma data som för vår ordlista. Låt oss kalla filen CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Filen kan laddas in i ett dataframe (förutsatt att den finns i den aktuella arbetskatalogen) enligt följande.
Koda:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Produktion:
Företagets ålder
0 Google 21
1 Amazon 23
2 Infosys 38
3 Direkt 22
Om du ställer in parameternamn , går förbi en lista med värden, tilldelas de dem som kolumnrubriker i samma ordning som de finns i listan. På liknande sätt kan radindex ställas in genom att skicka en lista till indexparametern, som visas i föregående avsnitt. Rubriken = Ingen indikerar saknade kolumnrubriker i datafilen.
Låt oss nu säga att kolumnnamnen var en del av datafilen. Sedan ställer du in rubrik = falskt gör det nödvändiga jobbet.
3. CompanyAgeWithHeader.csv
Företag, Ålder
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Koden kommer att ändras till
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Produktion:
Företagets ålder
0 Google 21
1 Amazon 23
2 Infosys 38
3 Direkt 22
- DataFrame från en Excel-fil: Ofta delas data i Excel- filer eftersom det förblir det mest populära verktyget som används av vanliga människor för Adhoc-spårning. Därför bör det inte ignoreras av vår diskussion.
Låt oss anta att data, samma som i CompanyAgeWithHeader.csv nu lagras i CompanyAgeWithHeader.xlsx, i ett ark med namnet Company Age. Samma DataFrame som ovan skapas med följande kod.
Koda:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Produktion:
Företagets ålder
0 Google 21
1 Amazon 23
2 Infosys 38
3 Direkt 22
Som du ser kan samma DataFrame skapas genom att mata in filnamnet och arknamnet.
Ytterligare läsning och nästa steg
De visade metoderna utgör en mycket liten delmängd i jämförelse med alla olika sätt DataFrames kan skapas. Dessa skapades med avsikt att komma igång. Du bör definitivt utforska referenserna och försöka utforska andra sätt, inklusive ansluta till en databas för att läsa data från direkt till en DataFrame.
Slutsats
Pandas DataFrame har visat sig vara en spelväxlare i världen av datavetenskap och dataanalys, samt är bekvämt för ad-hoc kortvariga projekt. Det kommer med en armé av verktyg som kan skära och tärja datauppsättningen med extrem enkelhet. Förhoppningsvis kommer detta att fungera som en springbrett i din resa framöver.
Rekommenderade artiklar
Detta är en guide till Python-Pandas DataFrame. Här diskuterar vi stegen för att skapa python-pandas dataframe tillsammans med dess kodimplementering. Du kan också titta på följande artiklar för att lära dig mer -
- Topp 15 funktioner i Python
- Olika typer av Python-uppsättningar
- Topp 4 typer av variabler i Python
- Topp 6 redaktörer för Python
- Matriser i datastruktur