

Vad är Big Data och Hadoop?
Data växer exponentiellt varje dag och med sådan växande data kommer behovet att använda dessa data. Liksom i äldre dagar brukade vi disketter för att lagra data och dataöverföring var också långsam men numera är dessa otillräckliga och molnlagring används eftersom vi har terabyte data. I dagens värld har vi sociala medier som bidrar högst i datatillväxt. Det består av människors beteende, tankesätt och flera andra aspekter. Det sägs att varje minut som 300 timmar video laddas upp på YouTube, över 20 miljoner bilder laddas upp på Facebook och många andra. Dessutom finns det ingen korrekt struktur för de data som laddas upp, vilket är den största utmaningen för att bearbeta dessa data.
Eftersom enorma data genereras med hög hastighet kunde traditionella RDBMS-system inte hantera en så snabb tillväxt. Dessutom kan de inte heller hantera ostrukturerade data. Det blev mycket svårt att hantera en så enorm mängd heterogen data som växer snabbt och att bearbeta dessa data med hög bearbetningshastighet. Således kom ett behov av ett sådant system som kan hantera stora datasätt effektivt. För att lösa scenariot kom Hadoop därför till. HDFS är komponenten i Hadoop som hanterade lagringsproblem i det stora datasättet genom att använda distribuerad lagring medan YARN är den komponent som hanterade behandlingsproblemet som reducerar behandlingstiden drastiskt.
Hadoop är en öppen källkodsram för lagring och bearbetning av stora datauppsättningar med hjälp av ett distribuerat stort kluster av varuhårdvara. Det utvecklades av Doug Cutting och Michael J. Cafarella och licensierats under Apache. Det är skriven med Java och har utvecklats baserat på papper skrivet av Google på MapReduce-systemet och det tillämpar begrepp för funktionell programmering. Det är pålitligt, ekonomiskt flexibelt och skalbart.
Kärnkomponenterna i Hadoop
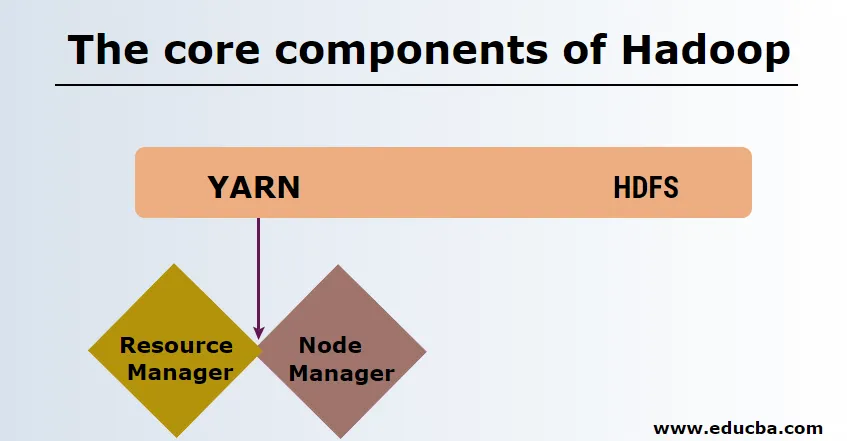
Kärnkomponenterna i Hadoop är följande
-
HDFS
HDFS eller Hadoop Distribuerat filsystem har Namenode och datanod. Namenode är huvudnoden som kör masterdemon och hanterar datanoderna och håller reda på alla operationer. Datanoder är de slavar där data faktiskt lagras.
-
GARN
YARN består av två huvudkomponenter:
1. ResourceManager: Den körs på huvudnoden och hanterar alla resurser och schemaläggar alla applikationer. Den har Scheduler & ApplicationManager.
2. NodeManager: Den körs på varje slavnod och är ansvarig för att hantera containrar och övervaka resursanvändning.
Flera komponenter i Hadoop
Det finns flera komponenter i Hadoop som grisen, bikupa, sqoop, flume, mahout, oozie, zookeeper, HBase, etc.
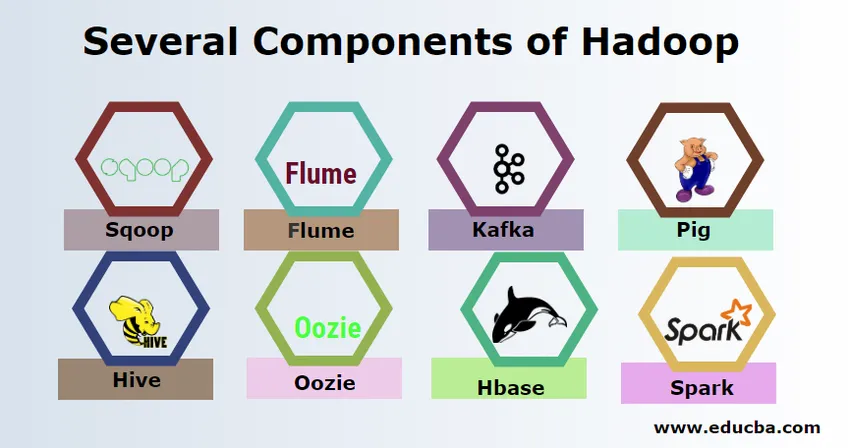
- Sqoop - Det används för att importera och exportera data från RDBMS till Hadoop och vice versa.
- Flume - Det används för att dra realtidsdata till Hadoop.
- Kafka - Det är ett meddelandesystem som används för att dirigera data i realtid till Hadoop.
- Pig - Det används som skriptspråk för databehandling.
- Hive - Det är ett datalagringsramverk som bygger på HDFS så att användare som är bekanta med SQL kan utföra frågor för att få informationen. Dessa frågor kallas HiveQL.
- Oozie - Det används för att schemalägga arbetsflödet för jobb som ska köras på specifika händelser eller tid.
- Hbase - Det är ingen SQL-databas som tillhandahålls som en del av Apache Hadoop.
- Spark - Det används för att utföra processer i minnet vilket är mycket snabbare än Hadoop kartminskning.
Hadoop-leverantörer
Det finns många företag som erbjuder Hadoop-distributioner. Nedan finns några bästa leverantörer för Hadoop:
- Cloudera
- Hortonworks
- MapR
Det finns få förutsättningar för att lära sig Hadoop. Tidigare erfarenhet av Java och skriptspråk är nödvändig. Även om Hadoop redan har sina egna programmeringsspråk på hög nivå som gris och bikupa som genererar backendkoden för vidare bearbetning, är det fortfarande möjligt att skapa ett eget kartminskningsprogram som alla programmeringsspråk som Ruby, Python, Perl och till och med C-programmering.
Bigdata och Hadoop är efterfrågade på dagens marknad. Detta kommer att öka mer de kommande dagarna. Många organisationer har redan flyttat in i Hadoop och de som inte har det kommer att flytta snart. Det finns en aktuell rapport om att stora företag har börjat investera i big data-analys. Big Data-marknadsföringsprognoser är alltid i uppåtgående trend och det är inte alls ett kortlivat tillstånd. Förutom alla dessa erbjuder jobb i Hadoop och big data alltid hög lön jämfört med andra tekniker.
Topp Big Data och Hadoop företag
Nedan finns några toppföretag som använder flest antal Hadoop-resurser.
- Yahoo
- Amazon
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Det finns många företag som använder big data-applikationer. Dessa är:
-
Nokia
Den använder Cloudera och Hadoop-komponenter som HDFS, HBase, Sqoop, Scribe för applikationen. Den använde användardata effektivt för att förstå och förbättra användarens upplevelse. Den använder databehandling och komplexa analyser för att bygga kartan med prediktiv trafik och skiktade höjdmodeller.
-
SAS
Det har samarbetat med Hadoop för att hjälpa datavetare att få bättre insikt genom att tillhandahålla en miljö som ger visuell och interaktiv upplevelse och därmed hjälper till att utforska nya trender. De analytiska programmen tar fram meningsfulla insikter från data och tekniken i minnet hjälper snabbare datatillgång.
Det finns också många andra företag som använder big data-plattformar för olika analyser. Det här är flygdataanalys av svartbox i flygbranschen, olika analyser på aktiemarknaden etc.
Fördelar med Haddop
Nedan är några av fördelarna med Hadoop
- Skalbar - Till skillnad från traditionell RDBMS är det en mycket skalbar plattform eftersom den kan lagra stora datasätt i distribuerade kluster över varuhårdvara som arbetar parallellt.
- Kostnadseffektivt - Kostnaden var för hög för RDBMS att lagra data som har lindrats i Hadoop.
- Snabbt och flexibelt - Det ger dig tillgång till data på ett snabbt sätt via det distribuerade filsystemet. Det erbjuder också att få affärsinblick från semistrukturerade och ostrukturerade data.
- Feltolerant - När data skickas till en nod replikeras samma data till andra noder som kan nås vid eventuella fel i den första noden.
Slutsats - vad är Big Data och Hadoop
Data växer kontinuerligt och därför kommer det alltid att finnas behov av big data och Hadoop för att ge mening med dessa data. Av detta skäl kommer professionella med Hadoop-färdigheter alltid att hitta gott om möjligheter under de kommande dagarna och kan vara en viktig tillgång för en organisation som ökar verksamheten och deras karriär.
Rekommenderade artiklar
Detta har varit en guide för vad som är Big Data och Hadoop. Här har vi diskuterat de grundläggande begreppen och komponenterna i Big Data och Hadoop. Du kan också titta på följande artikel för att lära dig mer -
- Exempel på Big Data Analytics
- Användningar av Hadoop
- Guide till datavisualisering
- Vad är Big data analytics?