
Översikt över AWS RedShift
AWS erbjuder många funktioner som underlättar för oss. I det här ämnet kommer vi att lära oss om Vad är AWS Redshift och några av teknikerna i AWS Redshift som ges nedan: -
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
En av de viktigaste tjänsterna som tillhandahålls av AWS och vi kommer att ta itu med är Amazon RedShift. Så vad är denna RedShift, vad används den för, det är de grundläggande frågorna som kommer över vårt sinne när vi läser detta. så låt oss kontrollera i detalj vad rödförskjutning är och vad den används till. RedShift är en företagsnivå, petabyte-skala och helt hanterad datalagringstjänst.
Så, vad är ett datavarehus? Svaret för är bosatt på egen hand om vi vet vad ett lager är allmänna villkor, i allmänhet är ett lager ett ställe där råvaror eller tillverkade varor kan lagras innan de distribueras för försäljning, samma gäller för Data också datavaruhus är en plats för att samla in, lagra och hantera data från olika källor och ge relevant och meningsfull affärsinsikter. Så Amazon tillhandahåller ett lagringsverktyg på företagsnivå där vi kan bearbeta och hantera data med REDSHIFT. Räckvidden för dessa datasätt varierar från 100s gigabyte till en petabyte.
Skäl för att använda AWS RedShift
Så vi stöter ofta på en allmän fråga som var innan detta AWS-verktyg var detta lager, var gjorde vi all denna databehandling, lagring och tillverkning. Så tidigare när data belastningen var ganska normal använder vi fysiska servrar, databaser som användes för att hålla reda på data och där bearbetning, men eftersom det var en exponentiell ökning i storleken på datafrågan och hanteringen av data blev en tuff uppgift eftersom frågor började ta lång tid som väntat.
Så här kom vi över behovet av amazon redshift som var mycket snabbare med mycket hög prestanda och skalbarhet för lagring och tillverkning av data. Det kom med massiv lagringskapacitet och transparent prissättning och säkras från olika dataintrång. Att stödja SQL-gränssnitt och olika drivrutiner ODBC / JDBC är det ganska lätt att använda och väl slås samman med andra Amazon-tjänster.
Arbeta med AWS RedShift
Låt oss nu se arkitekturschemat för Redshift och försöker förstå hur RedShift faktiskt fungerar -
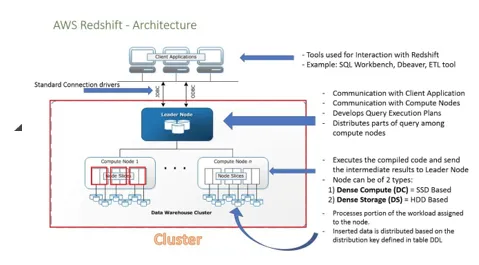
- Följande diagram visar hur Amazon RedShift fungerar. Låt oss kontrollera det i detalj: -
- För anslutning till klientapplikationen har vi flera drivrutiner som ansluter till Redshift.
- Inom Redshift kan vi skapa mer än ett kluster och varje kluster kan vara värd för flera databaser.
- Noderna är indelade i skivor som varje skiva har data.
- Från de tillgängliga noderna om vi har mer än en nod väljs som Leader som kommer att vara den viktigaste källan för klienten att kommunicera för. Klientapplikationen pratar bara med ledarnoden, ledarnoden ansvarar för att ta emot frågor och kommando från klientprogrammet.
- När ledarnoden börjar få de frågor som klienten utfört börjar det att analysera frågan och bygga en plan för att den ska köras på andra datornoder. När processen har distribuerats till de berörda noderna väntar den på slutresultatet från noderna innan den returneras till klienten.
- Vi kan lägga till antalet noder och också kan öka minnet när en mängd data ökar.
- Beräkningsnoderna har ett separat nätverk som klienten inte har åtkomst för att göra det också säkert.
- Det finns två typer av noder: Tät lagringsnod och täta datornoder, lagringskapaciteten kan variera från 160 GB till 16 TB
Så här såg vi den grundläggande arkitekturen för hur REDSHIFT fungerar. Låt oss nu gå till hur vi använder för Aws Redshift.
Använda AWS RedShift -
För att arbeta med AWS Redshift måste vi utföra några grundläggande steg som nämns nedan: -
1) Logga in på AWS och skapa ett konto där borta. (Om inte)
2) Gå till Amazon Redshift-konsolen från följande länk: -
https://console.aws.amazon.com/redshift/
3) Nu måste vi skapa en I AM-roll som vi behöver för att navigera till länken nedan: -
https://console.aws.amazon.com/iam/
- Gå till roller
- Välj att skapa roller.
- Välj Redshift i AWS-tjänsten
- Välj Redshift - Anpassningsbar och sedan Nästa: Behörigheter under välj ditt användningsfall.
- Ställ in tillståndsgränsen
- Skriv ett namn för din roll
- Granska och skapa roll.
4) Nu måste vi skapa ett kluster genom att välja en regionmeny där i konsolen.
- Välj regionen där klustret skapas.
- Klicka på Starta.
- Vi måste fylla i flera detaljer som databasnamn, lösenord och kontrollera knappen Fortsätt
- När klustret är synligt ska du kontrollera det i listan och granska statusinformationen.
- När vi har klusteret är nästa sak vi behöver göra att ställa in säkerhetsgruppen, här måste vi ställa in ingångsreglerna protokollkälla och intervall.
- Kontrollera den nödvändiga konfigurationen och anslut till Redshift Cluster.
5) När vi är klar med alla klusterrelaterade konfigurationer måste vi ansluta nu till vår Redshift nu. Vi kan ansluta till denna Redshift direkt eller via SSL. För att ansluta den direkt måste vi ha JDBC / ODBC-drivrutiner som vi måste ställa in den över konfigurationssidan för klustret.
När dessa flera konfigurationer har utförts fint är vi redo att använda Redshift.
Fördelar med AWS RedShift -
Så varför kommer någon att använda AWS Redshift måste det ha någon fördel jämfört med andra tjänster som gör detta speciellt. Så låt oss nu kontrollera några av fördelarna med att använda Redshift.
- Hög hastighet : - Behandlingstiden för frågan är jämförelsevis snabbare än de andra databehandlingsverktygen och datavisualisering har en mycket tydlig bild.
- Bulkdatabehandling : - Var större datastorleken redshift har möjlighet att behandla enorma datamängder på god tid.
- Minimalt dataförlust : - Eftersom data distribueras över klustret och behandlas parallellt över nätverket finns det en minsta chans för dataförlust och noggrannhetsgraden för bearbetade data är bättre.
- Kostnadseffektivt : - Att vara kostnadseffektivt är det billigare än alla andra tillgängliga alternativ som gör det starkt över branschanvändningen. Eftersom prissättningen är mindre kan vi rymma över stora mängder data och kan behandla dem inom budgeten.
- SQL-gränssnitt : - Frågor som är baserade för Redshift är samma som för Postgres SQL som gör det lättare för SQL-utvecklare att spela med den.
- Säkerhet : - Data inuti Redshift är krypterade som är tillgängliga på flera platser i RedShift. Vi kan också definiera in- och utgående regel som gör datan mycket säker.
Det finns mycket fler fördelar med att ha redshift som ett bättre val för datalageret.
AWS RedShift-prissättning -
RedShift kommer med en fantastisk prislista som lockar utvecklare eller marknaden mot den. Eftersom det har en on-demand prissättningsfunktion kan vi använda den drygt en timme och antalet noder i vårt kluster. Spektrumprissättning hjälper oss att köra SQL Queries direkt mot alla våra data.
Vi kan skapa stora datalager med HDD till ett mycket lågt pris. För mer information om de exakta prisuppgifterna kan du hänvisa till dokumentet nedan av Amazon: -
https://aws.amazon.com/redshift/pricing/
Dokumentet ovan har alla detaljer om de olika priserna för AWS REDSHIFT.
Slutsats
Från ovanstående artikel som vi såg för Redshift måste vi nu ha en rättvisande uppfattning om vad faktiskt redshift är och dess användning. RedShift är så väldigt skalbar och lätt att använda antas mest av branschen med stöd av olika andra tekniker från Amazon som gör det mer kraftfullt. Så i världen full av data kommer Redshift med ett mycket bra paket med datalagring och bearbetning.
Rekommenderade artiklar
Detta är en guide till What is AWS RedShift. Här diskuterar vi arbetar, använder och fördelar med AWS RedShift. Du kan också titta på följande artikel för att lära dig mer -
- AWS Arkitektur
- Vad är AWS?
- Vad är Azure?
- Vad är AWS Lambda?
- AWS Storage Services