
Introduktion till Poisson Regression i R
Poisson-regression är en typ av regression som liknar multipel linjär regression förutom att svaret eller den beroende variabeln (Y) är en räknarvariabel. Den beroende variabeln följer Poisson-distributionen. Prediktorn eller oberoende variabler kan vara kontinuerliga eller kategoriska. På ett sätt liknar det Logistic Regression som också har en diskret svarsvariabel. Förhandsförståelse för Poisson-distributionen och dess matematiska form är mycket viktigt för att utnyttja den för förutsägelse. I R kan Poisson-regression implementeras på ett mycket effektivt sätt. R erbjuder en omfattande uppsättning funktioner för dess implementering.
Implementering av Poisson Regression
Vi kommer nu att förstå hur modellen tillämpas. Följande avsnitt ger en steg-för-steg-procedur för samma. För denna demonstration överväger vi "gala" -datasättet från "fjärran" -paketet. Det avser artens mångfald på Galapagosöarna. Det finns totalt 7 variabler i datasatsen. Vi använder Poisson-regression för att definiera ett förhållande mellan antalet växtarter (arter) med andra variabler i datasatsen.
1. Ladda först "fjärran" -paketet. I det fall paketet inte finns, ladda ner det med funktionen install.packages ().
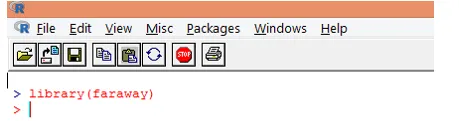
2. När paketet har laddats laddar du "gala" -datasättet i R med hjälp av data () -funktionen som visas nedan.
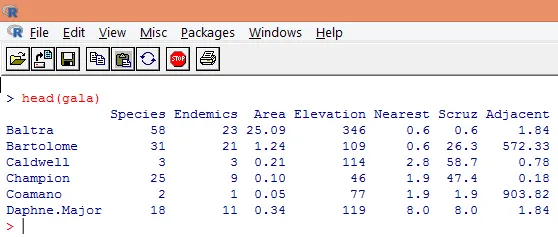
3. De laddade uppgifterna ska visualiseras för att studera variabeln och kontrollera om det finns några avvikelser. Vi kan visualisera antingen hela informationen eller bara de första raderna av dem med hjälp av funktionen huvud () som visas på skärmbilden nedan.
4. För att få mer inblick i datasatsen kan vi använda hjälpfunktioner i R enligt nedan. Det genererar R-dokumentationen som visas på skärmdumpen efter skärmbilden nedan.


5. Om vi studerar datasatsen som nämnts i de föregående stegen, kan vi finna att arter är en svarsvariabel. Vi studerar nu en grundläggande sammanfattning av prediktorvariablerna.
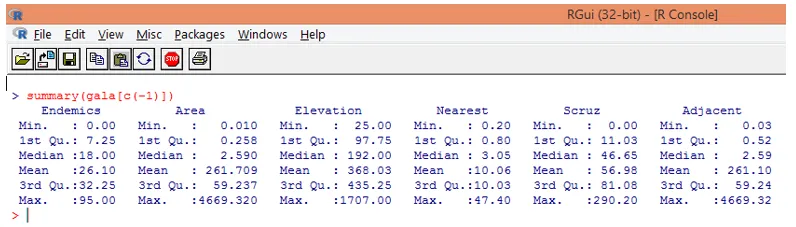
Observera, som vi kan se ovan, vi har uteslutit variabeln Arter. Sammanfattningsfunktionen ger oss grundläggande insikter. Observera bara medianvärdena för var och en av dessa variabler, och vi kan upptäcka att det finns en enorm skillnad, i termer av värderingsintervallet, mellan den första halvan och den andra halvan, t.ex. för områdets variabla medianvärde är 2, 59, men det maximala värdet är 4669.320.
6. Nu när vi är klar med grundläggande analys genererar vi ett histogram för arter för att kontrollera om variabeln följer Poisson-distributionen. Detta illustreras nedan.

Ovanstående kod genererar ett histogram för variabla arter tillsammans med en densitetskurva överlagrad över den.
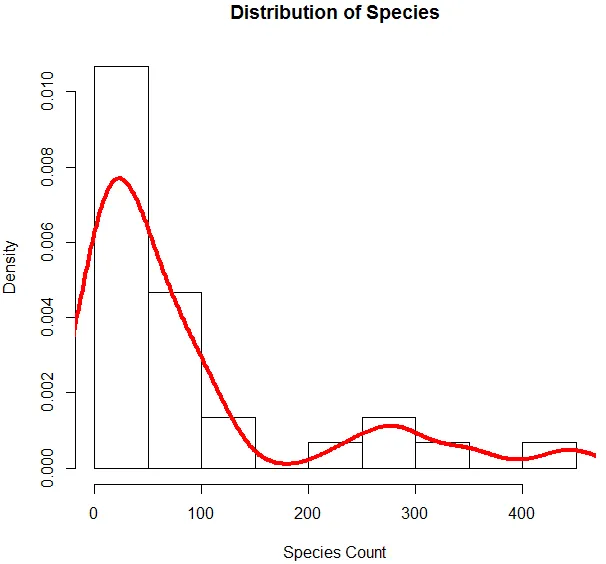
Ovanstående visualisering visar att arter följer en Poisson-distribution, eftersom uppgifterna är rätt skevade. Vi kan generera en boxplot också för att få mer inblick i distributionsmönstret som visas nedan.
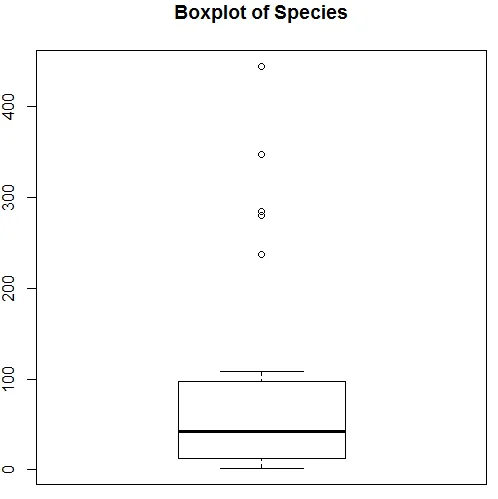
7. Efter att ha gjort med den preliminära analysen kommer vi nu att tillämpa Poisson-regression som visas nedan
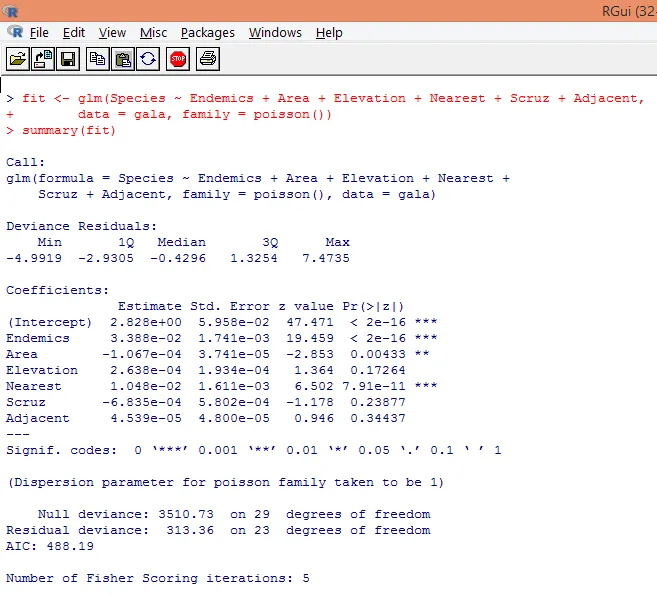
Baserat på ovanstående analys finner vi att variabler Endemics, Area and Nearest är betydelsefulla och endast deras inkludering är tillräcklig för att bygga rätt Poisson-regressionsmodell.
8. Vi bygger en modifierad Poisson-regressionsmodell med hänsyn till tre variabler, nämligen. Endemik, område och närmaste. Låt oss se vilka resultat vi får.
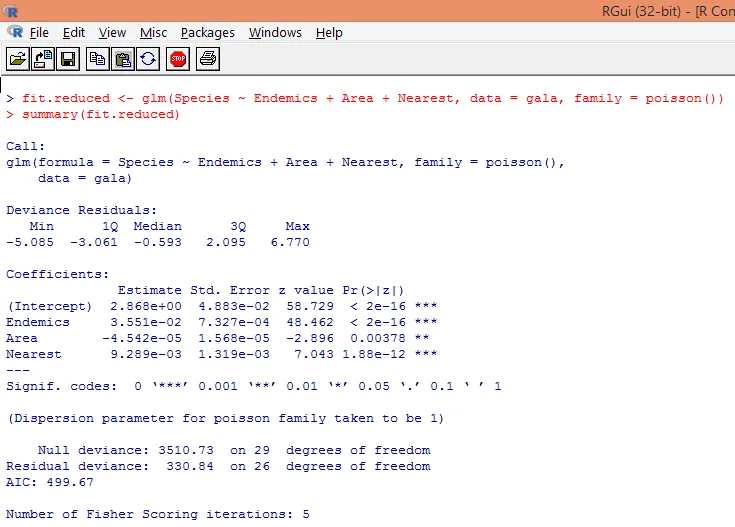
Utgången producerar avvikelser, regressionsparametrar och standardfel. Vi kan se att var och en av parametrarna är signifikant på p <0, 05 nivå.
9. Nästa steg är att tolka modellparametrarna. Modellkoefficienterna kan erhållas antingen genom att undersöka koefficienter i ovanstående utgång eller med hjälp av funktionen coef ().
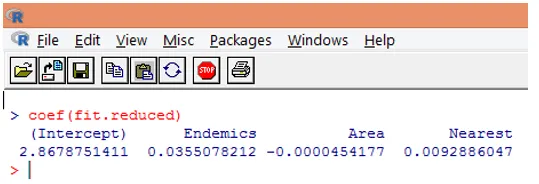
I Poisson-regression modelleras den beroende variabeln som loggen för den villkorade medelloggen (l). Regressionsparametern på 0, 0355 för Endemics indikerar att en enhetsökning i variabeln är associerad med en ökning av 0, 04 i det genomsnittliga antalet arter, som håller andra variabler konstant. Avlyssningen är ett loggmedelantal av arter när var och en av prediktorerna är lika med noll.
10. Det är emellertid mycket lättare att tolka regressionskoefficienterna i den ursprungliga skalan för den beroende variabeln (antal arter, snarare än lognumret för arter). Exponentiering av koefficienterna möjliggör en enkel tolkning. Detta görs enligt följande.
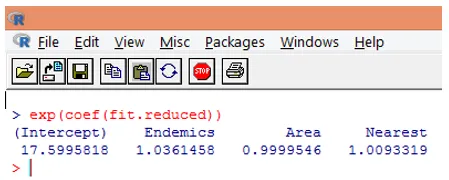
Från ovanstående fynd kan vi säga att en enhetsökning i Area multiplicerar det förväntade antalet arter med 0, 9999 och en enhetsökning i antalet endemiska arter representerade av Endemics multiplicerar antalet arter med 1.0361. Den viktigaste aspekten av Poisson-regression är att exponentierade parametrar har en multiplikativ snarare än en additiv effekt på svarsvariabeln.
11. Med hjälp av ovanstående steg erhöll vi en Poisson-regressionsmodell för att förutsäga antalet växtarter på Galapagosöarna. Det är dock mycket viktigt att kontrollera för överdispersion. I Poisson-regression är variansen och medlen lika.
Överdispersion inträffar när den observerade variationen av svarsvariabeln är större än vad som förutses av Poisson-fördelningen. Att analysera överdispersion blir viktigt eftersom det är vanligt med räknedata och kan påverka de slutliga resultaten negativt. I R kan överdispersion analyseras med ”qcc” -paketet. Analysen illustreras nedan.
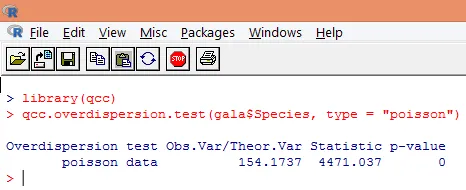
Ovanstående signifikanta test visar att p-värdet är mindre än 0, 05, vilket starkt antyder förekomsten av överdispersion. Vi försöker anpassa en modell med funktionen glm () genom att ersätta family = “Poisson” med family = “quasipoisson”. Detta illustreras nedan.
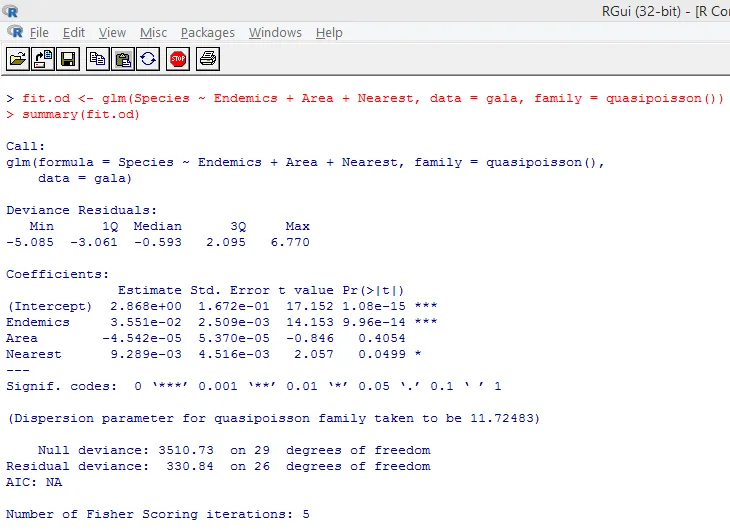
När vi studerar ovanstående resultat kan vi se att parameterns uppskattningar i quasi-Poisson-metoden är identiska med dem som produceras av Poisson-metoden, även om standardfel är olika för båda metoderna. I detta fall, för Area, är p-värdet dessutom större än 0, 05 vilket beror på större standardfel.
Betydelsen av Poisson Regression
- Poisson Regression i R är användbar för korrekta förutsägelser av den diskreta / räknarvariabeln.
- Det hjälper oss att identifiera de förklarande variabler som har en statistiskt signifikant effekt på svarsvariabeln.
- Poisson Regression i R är bäst lämpad för händelser av "sällsynt" natur eftersom de tenderar att följa en Poisson-distribution jämfört med vanliga händelser som vanligtvis följer en normal distribution.
- Den är lämplig för applikation i de fall svarsvariabeln är ett litet heltal.
- Det har breda tillämpningar, eftersom en förutsägelse av diskreta variabler är avgörande i många situationer. Inom medicin kan det användas för att förutsäga läkemedlets påverkan på hälsan. Det används starkt i överlevnadsanalys som död av biologiska organismer, misslyckande i mekaniska system etc.
Slutsats
Poisson-regression baseras på begreppet distribution av Poisson. Det är en annan kategori som tillhör uppsättningen regressionstekniker som kombinerar egenskaperna för såväl linjära som logistiska regressioner. Till skillnad från logistisk regression som endast genererar binär utgång, används den för att förutsäga en diskret variabel.
Rekommenderade artiklar
Detta är en guide till Poisson Regression i R. Här diskuterar vi introduktionen Implementing Poisson Regression and Importance of Poisson Regression. Du kan också gå igenom våra andra artiklar som föreslås för att lära dig mer–
- GLM i R
- Slumptalsgenerator i R
- Regressionsformel
- Logistisk regression i R
- Linjär regression vs logistisk regression | Topp skillnader