

Introduktion till Data Engineer Intervju Frågor och svar
Datateknik är en term där alla är medvetna om det och är ganska populära inom Big Data-området. Datateknik hänvisar till datainfrastruktur eller dataarkitektur. Rå data som genereras från olika källor såsom sociala medier, mobiltelefoner, www (internet), måste omvandlas, rengöras, profileras och aggregeras för affärsbehov. Denna rådata benämns också som Dark Data. Övningen med att designa, arkivera och implementera dataprocesssystemet hjälper till att konvertera data till en bit lämplig information eller uppsättning data, sådan information eller uppsättning data benämns Data Engineering.
Nedan finns en lista över de viktigaste frågorna och svaren på Data Engineer 2019:
Om du letar efter ett jobb som är relaterat till Data Engineer måste du förbereda dig för intervjufrågorna om Data Engineer från 2019. Även om alla intervjufrågor från Data Engineer är olika och omfattningen av ett jobb också är annorlunda, kan vi hjälpa dig med de bästa intervjufrågorna om Data Engineer med svar, vilket hjälper dig att ta språng och få din framgång i din Data Engineer Interview.
1. Vad är datateknik?
Svar:
Datateknik är en term som är ganska populär inom Big Data-fältet och hänvisar främst till datainfrastruktur eller dataarkitektur.
Uppgifterna som genereras av många källor som sociala medier, mobiltelefoner, www (internet) är rådata. Det måste transformeras, rengöras, profileras och aggregeras för affärsbehov. Vi kan kalla denna råa data som Dark Data som vi kommer att lysa ljuset på för att göra dessa Dark Data användbara. Övningen med att designa, arkivera och implementera dataprocesssystemet som hjälper till att göra data konverterade till användbar information kallas Data Engineering.
2. Förklara det dagliga arbetet hos en dataingenjör?
Svar:
Dataingenjörs dagliga jobb består av:
a. hantering av datatillsyn i organisationen
b. hantering och underhåll av källsystem för data och iscensättningsområden
c. gör ETL eller ELT och datatransformation
d. förenkla rensning av data och förbättring av dataduplicering och -byggnad
e. gör ad-hoc dataförfrågan byggande och extraktion
Se visualisering nedan som informerar om vad en datatekniker arbetar med: - 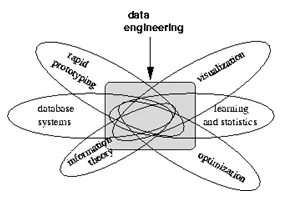
3. Har du erfarenhet av datamodellering?
Svar:
Man kan säga att han / hon har arbetat med ett projekt för en finans- / sjukförsäkringsklient där de har använt ETL-verktyg som Informatica / Talend / Pentaho etc. för att transformera och bearbeta data som hämtas från en MySQL / RDS / SQL-databas och skickar lämna ut denna information till leverantörer som kan hjälpa till att öka sina intäkter. Man kan visa under hög nivå arkitektur av datamodell. Det består av en primär nyckel, enhet, attribut, relation, begränsningar etc.
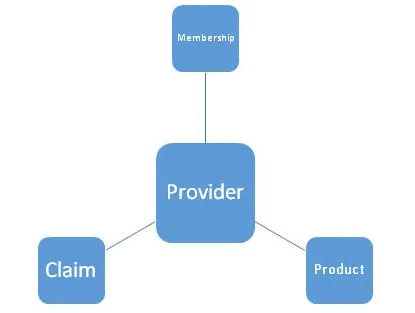
4. Vilka är olika typer av designscheman i Datamodellering? Förklara med ett exempel?
Svar:
Det finns två typer av scheman i datamodellering:
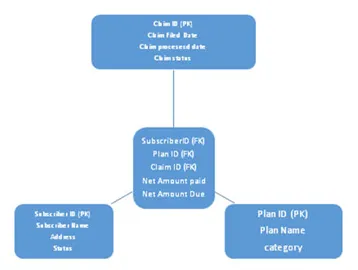
a. Star Schema
Detta schema är uppdelat i två, ett är faktabord och ett annat är dimensionstabell där alla dimensionstabeller är anslutna till en faktabord. Faktumtabellen för utländsk nyckel refererar till de primära nycklarna som finns i dimensionstabeller. Se nedan arkitektur av stjärnschema:
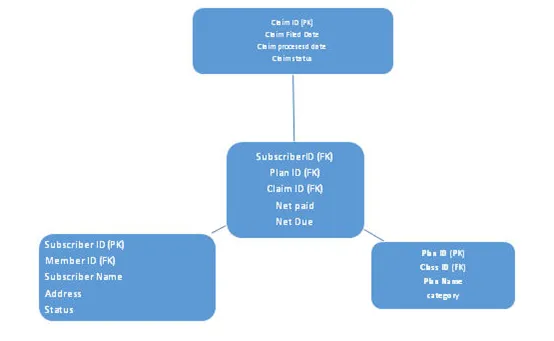
b. Snowflake Schema
I detta schema ökas normaliseringsnivån, här kommer faktabellen att förbli densamma som för stjärnschema, här normaliseras dimensionstabeller. På grund av många lager av dimensionstabeller ser det ut som en snöflinga, alltså namnet snöflingaschema. Se arkitektur nedan: -
5. Vilket ETL-verktyg använder du och hur detta bäst jämförs med andra?
Svar:
Man kan säga att han / hon har använt Informatica som ETL-verktyg på grund av många poäng, först och främst är att enligt Gartner Magic Quadrant för Data Integration Tools Informatica är positionerad som ledare för 10: e året i rad. Det är lätt att använda och lära sig och har funktioner för att ansluta till en annan mängd källdata och datatyper, återanvändbara komponenter och funktioner som gör den mest favorit för ETL-utvecklare. Det har också en egen schemaläggare som är en annan fördel, där andra ETL-verktyg måste använda en extern schemaläggare för att schemalägga jobben.
6. Vilka tekniker / programmeringsspråk ska man ha / lära sig att vara en dataingenjör?
Svar:
Matematik (linjär algebra och sannolikhet)
Statistik (sammanfattande statistik)
Maskininlärningstekniker
R- och SAS-språk
SQL-databaser, Hive QL
Python (mestadels används)
Bortsett från dessa bör man ha problemlösning, analytisk och arkitektonisk kunskap om databasen.
7. Vilka är några vanliga problem som dataingenjörer står inför?
Svar:
1. Integrering i realtid / Kontinuerlig integration
2. Att lagra en enorm mängd data är en fråga, informationen från dessa uppgifter är en annan fråga.
3. Vilka verktyg som kan användas som ger bästa prestanda, lagring, effektivitet och resultat.
4. Har lagringsskalan? Anta hur man vet att det för behandling av hela uppsättningen av data hur lång tid det kommer att ta?
5. Med tanke på processorer och RAM-konfiguration
6. Hur hanteras fel, är feltolerans där eller inte?
8. Hur skiljer sig Data-arkitekten från Data Engineer?
Svar:
Data Architect är personen för att hantera data, särskilt när man har att göra med olika antal olika datakällor. Man bör ha djupgående kunskap om hur en databas fungerar, hur data relaterar till affärsproblem och hur förändringarna kommer att störa organisationens dataanvändning och sedan kommer dataarkitekt att manipulera / omvandla dataarkitekturen enligt dem.
Dataarkitektens huvudansvar arbetar med datalagring, utveckling av dataarkitektur eller företagets datahub / lager.
Medan en datatekniker hjälper till med att installera datalagerlösningar, datamodellering, utveckling och testning av databasarkitektur.
9. Beskriv en tid då du hittade ett nytt användningsfall för befintlig databas som hade en positiv inverkan på verksamheten?
Svar:
Medan SQL kommer att sakna nedanstående funktioner i en epok av Big Data:
a. RDBMS är schemanorienterad DB så det är bättre för strukturerad data inte för semistrukturerad eller ostrukturerad data.
b. Kan inte behandla oförutsägbara och ostrukturerade data.
c. Det är inte horisontellt skalbart, dvs. parallellkörning och lagring är inte möjligt i SQL.
d. Det lider av prestandaproblem när ett antal användare ökar.
e. Det används främst för transaktionsbearbetning online.
För att övervinna dessa nackdelar kan vi använda NoSQL DB, dvs inte bara SQL.
Så i projektet kan man använda olika typer av NoSQL DB som Cassandra, Mongo DB, Graph DB, HBase etc.
10. Har du erfarenhet av att arbeta i en molnberäkningsmiljö? Vilka fördelar ser du fungera i en?
Svar:
Man kan säga ja Cloud Computing Environment är redo att flytta miljö för produktion, utveckling och testning utan att tänka på att integrera många instanser / Linux / fönster-servrar tillsammans. Det finns olika molntjänstjänster på en marknad som AWS (Amazon webbtjänster), Azure (Microsoft), GCP (Google Cloud Platform). Molntjänstjänster tillhandahåller funktioner nedan som flexibilitet, dvs miljö kommer att skalas upp enligt krav, katastrofåterhämtning genom att ta säkerhetskopior och stillbilder, Arbeta var som helst med VPN, säker miljö och miljövänlig eftersom den fungerar på hårdvaruhårdvara, dvs. datorer för allmänt bruk som har låg kostnad.
Slutsats
I ovanstående blogg har vi behållit de mest ställda intervjufrågorna om Data Engineer och hur man kan svara på detta genom att ge funktionspoäng.
Rekommenderad artikel:
Detta har varit en omfattande guide till intervjufrågor och svar på datatekniker så att kandidaten enkelt kan slå samman dessa dataingenjörsintervjufrågor. den här artikeln består av alla toppfrågor och svar på Data Engineer-intervjuer. Du kan också titta på följande artiklar för att lära dig mer -
- Viktigaste Azure Paas vs Iaas
- Big Data intervjufrågor
- 5 viktigaste intervjufrågor för Elasticsearch
- PIG-intervjufrågor och svar
- Topp 5 mest värdefulla intervjufrågor för datavetenskap