

Introduktion till beslutsträd i dataanläggning
I dagens värld av "Big Data" betyder termen "Data Mining" att vi måste undersöka stora datamängder och utföra "gruvdrift" på data och ta fram den viktiga juicen eller essensen i vad datan vill säga. En mycket analog situation är kolbrytningen där olika verktyg krävs för att bryta kolet som ligger begravt djupt under marken. Av de verktyg som finns i Data mining är "Decision Tree" ett av dem. Därför är data mining i sig ett stort fält där de närmaste paragraferna vi djupt dyker in i beslutsträdets “verktyg” i Data Mining.
Algoritm av beslutsträd i dataanläggning
Ett beslutsträd är en övervakad inlärningsmetod där vi tränar de data som finns när vi redan vet vad målvariabeln faktiskt är. Som namnet antyder har denna algoritm en trädtyp av struktur. Låt oss först titta på den teoretiska aspekten av beslutsträdet och sedan titta på samma i en grafisk strategi. I beslutsträdet delar algoritmen datasättet i delmängder utifrån det viktigaste eller viktigaste attributet. Det viktigaste attributet anges i rotnoden och det är där delningen sker för hela datasatsen som finns i rotnoden. Den här delningen är känd som beslutsnoder. Om det inte går att dela mer är den noden benämnd som en bladnod.
För att stoppa algoritmen för att nå ett överväldigande steg används ett stoppkriterium. Ett av stoppkriterierna är det minsta antalet observationer i noden innan delningen sker. När man använder beslutsträdet vid uppdelningen av datasättet måste man vara försiktig så att många noder bara kan ha bullriga data. För att tillgodose en överliggande eller bullriga dataproblem använder vi tekniker som kallas Data beskärning. Dataskärning är inget annat än en algoritm för att klassificera data från delmängden vilket gör sig svårt att lära sig från en given modell.
Decision Tree-algoritmen släpptes som ID3 (Iterative Dichotomiser) av maskinforskaren J. Ross Quinlan. Senare släpptes C4.5 som efterträdare för ID3. Både ID3 och C4.5 är en girig strategi. Låt oss nu undersöka ett flödesschema för beslutsträdets algoritm.
För vår pseudokodförståelse, skulle vi ta "n" datapunkter som alla har "k" -attribut. Under flödesschemat tas hänsyn till "Information Gain" som villkoret för en splittring.
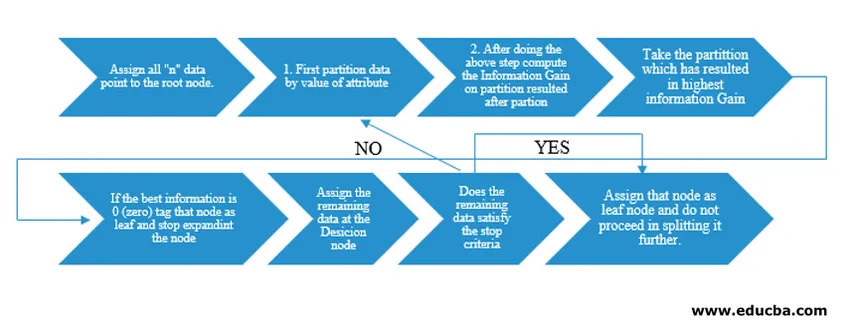
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
I stället för Information Gain (IG) kan vi också använda Gini-index som kriterier för en splittring. För att förstå skillnaden mellan dessa två kriterier i lekmann termer kan vi tänka på denna informationsförstärkning som skillnad i entropi före splittringen och efter splittringen (delad på grundval av alla tillgängliga funktioner).
Entropi är som slumpmässighet och vi skulle nå en punkt efter splittringen för att ha lägst slumpmässighetstillstånd. Därför måste informationsvinster vara störst för den funktion vi vill dela. Annars om vi vill välja att dela ut på basis av Gini-index, skulle vi hitta Gini-index för olika attribut och med samma kan vi ta reda på viktat Gini-index för olika split och använda det med högre Gini-index för att dela upp datasättet.
Viktiga villkor för beslutsträd vid dataanläggning
Här är några av de viktiga villkoren för ett beslutsträd i dataintergivning som anges nedan:
- Root Node: Detta är den första noden där delningen sker.
- Leaf Node: Detta är den nod efter vilken det inte finns mer gren.
- Beslutsnod: Noden som bildas efter delning av data från en tidigare nod är känd som en beslutsnod.
- Gren: Underavsnitt av ett träd som innehåller information om efterdyningarna efter splittringen vid beslutsnoden.
- Beskärning: När det finns ett borttagande av undernoder för en beslutsnod för att tillgodose en överliggande eller bullriga data kallas beskärning. Det tros också vara motsatsen till splittring.
Tillämpning av beslutsträd vid dataanläggning
Decision Tree har ett flödesschema-typ av arkitektur inbyggt med typen av algoritm. Den har i huvudsak ett "If X then Y else Z" -mönster medan splittringen är gjord. Denna typ av mönster används för att förstå mänsklig intuition inom det programmatiska området. Därför kan man i stor utsträckning använda detta i olika kategoriseringsproblem.
- Denna algoritm kan användas i stor utsträckning i fältet där objektivfunktionen är relaterad med avseende på analysen som har gjorts.
- När det finns många handlingsplaner tillgängliga.
- Utvärderad analys.
- Förstå den betydande uppsättningen funktioner för hela datasatsen och "mina" de få funktionerna från en lista med hundratals funktioner i big data.
- Att välja den bästa flygningen för att resa till en destination.
- Beslutsprocess baserad på olika omständigheter.
- Churn-analys.
- Sentimentanalys.
Fördelarna med beslutsträdet
Här är några fördelar med beslutsträdet som förklaras nedan:
- Enkel förståelse: Hur beslutsträdet visas i sina grafiska former gör det lätt att förstå för en person med en icke-analytisk bakgrund. Speciellt för personer i ledarskap som vill titta på vilka funktioner som är viktiga bara genom att titta på beslutsträdet kan ta fram sin hypotes.
- Data Exploration: Som diskuterat är att få betydande variabler en central funktionalitet i beslutsträdet och använda samma, kan man räkna ut under datautforskning om man bestämmer vilken variabel som skulle behöva särskild uppmärksamhet under data mining och modelleringsfasen.
- Det är mycket litet mänskligt ingripande under datapreparationssteget och som en följd av den tidskrävande tidpunkten under data minskas rengöringen.
- Beslutsträdet kan hantera såväl kategoriska som numeriska variabler och även tillgodose klassificeringsproblem i flera klasser.
- Som en del av antagandet har beslutsträd inget antagande från en rumslig fördelnings- och klassificeringsstruktur.
Slutsats
Slutligen, för att avsluta beslutsträd, sätter man in en helt annan klass av icke-linearitet och tillgodoser lösningar på problem med icke-linearitet. Denna algoritm är det bästa valet att efterlikna ett beslutsnivå och tänka på människor och framställa den i en matematisk-grafisk form. Det tar en ovanifrån och ner metod för att bestämma resultat från nya osynliga data och följer principen om klyftan och erövring.
Rekommenderade artiklar
Detta är en guide till beslutsträd i dataanläggning. Här diskuterar vi algoritmen, betydelsen och tillämpningen av beslutsträd i datainsamling tillsammans med dess fördelar. Du kan också titta på följande artiklar för att lära dig mer -
- Data Science Machine Learning
- Typer av dataanalysstekniker
- Beslutsträd i R
- Vad är dataanläggning?
- Guide till olika metoder för dataanalys