

Översikt över typer av kluster
Låt oss förstå vad som är kluster innan vi lär oss typer av kluster och varför är det så viktigt i maskininlärningsbranschen just nu.
Vad är Clustering? Clustering är en process där algoritmen delar upp datapunkterna i ett bestämt antal grupper baserat på principen att liknande datapunkter håller sig nära varandra och de faller i samma grupp.
Varför är det så viktigt nu? Låt oss förstå att genom att se exempel, finns det en online klädbutik och de vill förstå sina kunder bättre så att de kan göra sin annonsstrategi effektivare. Det är inte möjligt för dem att ha en unik typ av strategi för varje kund, istället för vad de kan göra är att dela upp kunderna i ett visst antal grupper (baserat på deras tidigare köp) och ha en separat strategi för separata grupper. Detta gör verksamheten mer effektiv, det är anledningen till att kluster är viktigt i branschen nu.
Typer av kluster
I stort sett klassificeras metoder för klusteringstekniker i två typer, de är hårda metoder och mjuka metoder. I metoden Hard clustering tillhör varje datapunkt eller observation endast ett kluster. I den mjuka klustermetoden kommer varje datapunkt inte helt att tillhöra ett kluster, istället kan det vara medlem i mer än ett kluster, det har en uppsättning medlemskapskoefficienter som motsvarar sannolikheten att vara i ett givet kluster.
För närvarande finns det olika typer av klusteringsmetoder som används. Här i den här artikeln låt oss se några av de viktiga som hierarkisk klustering, partitionering av kluster, fuzzy clustering, Density-baserad clustering och Distribution Model-baserad clustering. Låt oss nu diskutera var och en av dessa med ett exempel:
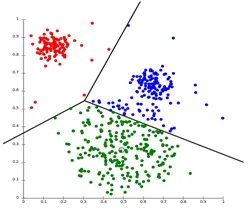
1. Partitionering Clustering
Partitionering Clustering är en typ av klusteringsteknik som delar upp datauppsättningen i ett bestämt antal grupper. (Till exempel värdet på K i KNN och det kommer att bestämmas innan vi tränar modellen). Det kan också kallas som en centroidbaserad metod. I detta tillvägagångssätt bildas klustercentrum (centroid) så att avståndet mellan datapunkter i det klustret är minimalt när det beräknas med andra klustercentroider. Ett mest populärt exempel på denna algoritm är KNN-algoritmen. Så här ser en partitionerings-klusteralgoritm ut
2. Hierarkisk klustering
Hierarkisk klustering är en typ av klusteringsteknik som delar upp datauppsättningen i ett antal kluster, där användaren inte anger antalet kluster som ska genereras innan modellen tränas. Denna typ av klusteringsteknik är också känd som anslutningsbaserade metoder. I den här metoden görs ingen enkel uppdelning av datamängden, medan den ger oss hierarkin för kluster som smälter samman med varandra efter ett visst avstånd. Efter att den hierarkiska klustringen har gjorts på datasatsen kommer resultatet att bli en trädbaserad representation av datapunkter (Dendogram), som är indelade i kluster. Så här ser en hierarkisk gruppering ut efter utbildning
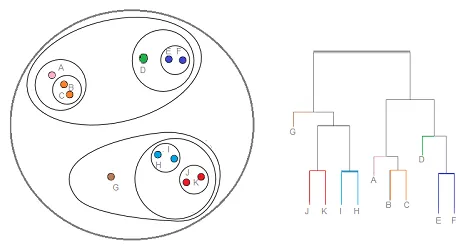
Källlänk: Hierarkisk klustering
Vid partitionering av kluster och hierarkisk kluster, en huvudskillnad vi kan märka är i partitionering av kluster, vi kommer att förhandsbestämma värdet på hur många kluster vi vill att datauppsättningen ska delas in i och vi förhandsdefinierar inte detta värde i hierarkisk kluster .
3. Densitetsbaserad kluster
I denna gruppering kommer teknikkluster att bildas genom segregering av olika densitetsregioner baserade på olika tätheter i dataplanen. Densitetsbaserad rumslig klustering och applikation med brus (DBSCAN) är den mest använda algoritmen i denna typ av teknik. Huvudtanken bakom denna algoritm är att det bör finnas ett minimumantal poäng som innehåller i närheten av en given radie för varje punkt i klustret. Hittills i ovan diskuterade klusteringstekniker, om du observerar noggrant kan vi märka en vanlig sak i alla tekniker som är formen på bildade kluster är antingen sfäriska eller ovala eller konkava formade. DBSCAN kan bilda kluster i olika former, den här typen av algoritm är bäst lämpad när datasättet innehåller brus eller outliers. Så här ser en densitetsbaserad rumslig klusteralgoritm ut efter träning.
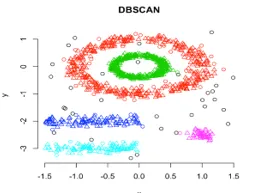
Källlänk: Density-Based Clustering
4. Distribution Model-Based Clustering
I denna typ av kluster bildas teknikkluster genom att identifiera med sannolikheten för att alla datapunkter i klustret kommer från samma distribution (Normal, Gaussian). Den mest populära algoritmen i denna typ av teknik är Expectation-Maximization (EM) clustering med Gaussian Mixture Models (GMM).
Normala klusteringstekniker som hierarkisk klustering och partitioneringskluster är inte baserade på formella modeller, KNN vid partitionering av kluster ger olika resultat med olika K-värden. Eftersom KNN och KMN anser medelvärde för klustercentret är det inte bäst lämpligt i vissa fall med Gaussiska blandningsmodeller antar vi att datapunkter är Gauss-distribuerade, på det här sättet har vi två parametrar för att beskriva formen på klusterens medelvärde och standardavvikelsen. På detta sätt tilldelas en Gauss-distribution för varje kluster, för att få de optimala värdena för dessa parametrar (medelvärde och standardavvikelse) används en optimeringsalgoritm som kallas Expectation Maximization. Så ser EM - GMM ut efter träning.
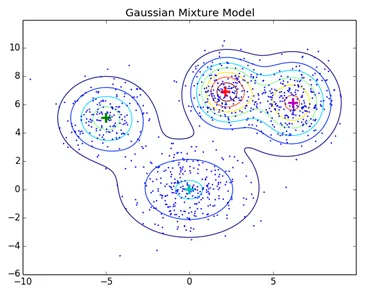
Källlänk: Distribution Model-Based Clustering
5. Fuzzy Clustering
Tillhör en gren av mjuka metodklusteringstekniker, medan alla ovannämnda klusteringstekniker tillhör hårda metodklusteringstekniker. I denna typ av klusteringsteknik pekar nära mitten, kanske en del av det andra klustret i högre grad än punkter i kanten av samma kluster. Sannolikheten för en punkt som tillhör ett givet kluster är ett värde som ligger mellan 0 till 1. Den mest populära algoritmen i denna typ av teknik är FCM (Fuzzy C-betyder algoritm) Här beräknas centroiden för ett kluster som medelvärdet av alla punkter, viktade av deras sannolikhet att tillhöra klustret.
Slutsats - Typer av kluster
Detta är några av de olika klusteringsteknikerna som för närvarande används och i den här artikeln har vi täckt en populär algoritm i varje klusteringsteknik. Vi måste välja vilken typ av teknik vi använder, baserat på vårt datasæt och krav som vi måste uppfylla.
Rekommenderade artiklar
Detta har varit en guide till typer av kluster. Här diskuterar vi olika typer av kluster med deras exempel. Du kan också titta på följande artiklar för att lära dig mer -
- Hierarkisk klusteralgoritm
- Clustering in Machine Learning
- Typer av maskininlärningsalgoritmer
- Typer av dataanalysstekniker
- Hur använder och tar jag bort hierarkin i Tableau?
- Komplett guide till typer av dataanalys