
Text Mining Introduktion
Textbrytning - I dagens sammanhang är text det vanligaste sättet genom vilket information utbyts. Men att förstå innebörden från texten är inte något lätt jobb alls. Vi behöver ett bra affärsintelligensverktyg som hjälper dig att förstå informationen på ett enkelt sätt.
Vad är Text Mining
Text Mining kallas också Text Analytics. Det är processen att förstå information från en uppsättning texter. Text Mining är utformad för att hjälpa företaget ta reda på värdefull kunskap från textbaserat innehåll. Innehållet kan vara i form av orddokument, e-post eller inlägg på sociala medier.
Text Mining är användning av automatiserade metoder för att förstå kunskapen som finns i textdokumenten.
Text Mining kan också användas för att få datorn att förstå strukturerade eller ostrukturerade data. Kvalitativa data eller ostrukturerade data är data som inte kan mätas i antal. Dessa data innehåller vanligtvis information som färg, textur och text. Kvantitativa data eller strukturerade data är data som enkelt kan mätas.
Textbrytning är ett tvärvetenskapligt fält som inkluderar informationshämtning, data mining, maskininlärning, statistik och andra. Text Mining är ett litet annorlunda fält från datahantering.
Fördelar med textbrytning
Det finns många fördelar med att använda Text Mining. De listas nedan
- Det sparar tid och resurser och fungerar effektivt än människors hjärnor.
- Det hjälper till att spåra åsikter över tiden
- Text Mining hjälper till att sammanfatta dokumenten
- Textanalys hjälper till att extrahera koncept från text och presentera det på ett enklare sätt
- Texten som indexeras med Text mining kan användas i prediktiv analys
- Du kan ansluta alla ordförråd för att använda terminologin i ditt intresseområde
Användning av textbrytning
- Namnen på olika enheter och relationer mellan texten kan lätt hittas med olika tekniker.
- Det hjälper till att extrahera mönster från stor mängd ostrukturerad data
- Systematisk granskning av litteratur - Det kan gå till djupgående forskning om text, ta reda på viktiga teman och belysa de upprepade termerna eller texten och de populära ämnena under en tidsperiod.
- Test av hypotes - Genom textbrytning kan en viss hypotes testas för att se om dokumentet bekräftar eller förnekar hypotesen. Vanligtvis testas en etablerad tro över dokumentet först.
Utveckla lösningar på affärsproblem effektivt. Lär dig att definiera, analysera och dokumentera affärskrav. Undersök affärsaktiviteter för att göra dem mer effektiva.
Betydelsen av textbrytning
- Textbrytning möjliggör bättre och smart beslutsfattande
- Det hjälper till att lösa problem med kunskapsupptäckt inom olika affärsområden
- Genom textbrytning kan du enkelt visualisera data på många sätt som html-tabeller, diagram, grafer och andra
- Det är ett fantastiskt produktivitetsverktyg. Det ger bättre resultat snabbare än något annat verktyg.
- Text mining-verktyg används av både stora och småskaliga organisationer som är kunskapsdrivna organisationer.
Tillämpningar av Text Mining
-
Analysera svar från öppen undersökning
Frågor om öppen undersökning hjälper respondenterna att ge sin åsikt eller åsikt utan några begränsningar. Detta hjälper dig att veta mer om kundernas åsikter än att förlita sig på strukturerade frågeformulär. Textbrytning kan användas för att analysera sådan information i form av text.
-
Automatisk behandling av meddelanden, e-post
Text Mining används också främst för att klassificera texten. Text Mining kan användas för att filtrera onödig e-post med hjälp av vissa ord eller fraser. Sådana e-postmeddelanden släpper automatiskt sådana e-postmeddelanden till skräppost. Ett sådant automatiskt system för klassificering och filtrering av utvalda e-postmeddelanden och skickning av den motsvarande avdelningen görs med Text Mining-systemet. Text Mining kommer också att skicka en varning till e-postanvändaren att ta bort e-postmeddelanden med sådana kränkande ord eller innehåll.
-
Analysera garanti eller försäkringskrav
I de flesta affärsorganisationer samlas information främst i form av text. Till exempel på ett sjukhus kan patientintervjuerna berättas kort i textform och rapporterna är också i form av text. Dessa anteckningar samlas nu elektroniskt så att de enkelt kan överföras till algoritmer för textbrytning. Dessa poster kan sedan användas för att diagnostisera den faktiska situationen.
-
Undersöka konkurrenter genom att genomsöka sina webbplatser
Ett annat viktigt applikationsområde för Text Mining är att bearbeta innehållet på webbsidor i en viss domän. På detta sätt kommer textbrytningssystemet automatiskt att hitta en lista med termer som används på webbplatsen. På detta sätt kan man ta reda på de viktigaste termer som används på webbplatsen. På detta sätt kan man känna till kapaciteten om konkurrenterna som kan hjälpa dig att leverera affärer effektivt.
De andra applikationerna för Text Mining inkluderar följande
- Business Intelligence
- E Upptäckt
- Bioinformatik
- Dokumenthantering
- Nationell säkerhet eller intelligens fungerar
- Social Media Monitoring
Tekniker som används i textbrytning
Det finns fem grundläggande tekniker som används i Text Mining-systemet. De diskuteras i detalj nedan
-
Informationsutvinning
Detta används för att analysera den ostrukturerade texten genom att ta reda på de viktiga orden och hitta förhållandena mellan dem. I denna teknik används processen för mönstermatchning för att ta reda på ordningen i text. Det hjälper till att omvandla den ostrukturerade texten till strukturerad form. Informationsutvinningstekniken innefattar språkbearbetningsmoduler. Detta används mest där det finns stora mängder data. Processen för utvinning av information förklaras på bilden nedan.
-
kategorisering
Kategoriseringsteknik klassificerar textdokumentet under en eller flera kategorier. Det är baserat på exempel på input för att göra klassificeringen. Kategoriseringsprocessen inkluderar förbehandling, indexering, dimensionell reduktion och klassificering. Texten kan kategoriseras med hjälp av tekniker som Naive Bayesian klassificerare, beslutsträd, närmaste grannklassificering och supportförsäljningsmaskiner.
-
Clustering
Clustering-metoden används för att gruppera textdokument som har liknande innehåll. Den har partitioner som kallas kluster och varje partition kommer att ha ett antal dokument med liknande innehåll. Clustering ser till att inget dokument kommer att utelämnas från sökningen och att det härleder alla dokument som har liknande innehåll. K-medel är den ofta använda klusteringstekniken. Denna teknik jämför också varje kluster och hittar hur väl dokumentet är anslutna till varandra. Företag använder denna teknik för att skapa en databas med tusentals liknande dokument.
-
visualisering
Visualiseringsteknik används för att förenkla processen för att hitta relevant information. Denna teknik använder textflaggor för att representera dokument eller grupp av dokument och använder färger för att indikera kompaktheten. Visualiseringsteknik hjälper till att visa textinformation på ett mer attraktivt sätt. Bilden nedan representerar Visualiseringstekniken
-
Sammanfattning
Sammanfattningsteknik hjälper till att minska dokumentets längd och sammanfatta detaljerna i dokumenten i korthet. Det gör att dokumentet fungerar som läsning för användarna och förstår innehållet på en överblick. Sammanfattning ersätter hela uppsättningen av dokument. Det sammanfattar stort textdokument enkelt och snabbt. Människor tar mer tid att läsa och sedan sammanfatta dokumentet men denna teknik gör det mycket snabbt. Det hjälper till att lyfta fram viktiga punkter i ett dokument. Sammanfattningsprocessen representeras på bilden nedan.
Metoder och modeller som används vid textbrytning
Baserat på informationshämtningen har Text Mining fyra huvudmetoder
-
Termbaserad metod (TBM)
Term i ett dokument betyder ett ord som har semantisk betydelse. I denna metod analyseras hela uppsättningen av dokument utifrån term. En huvudsaklig nackdel med denna metod är problemet med synonym och polysemi. Synonym är där flera ord som har samma betydelse. Polysemi är där ett enda ord har fler betydelser.
-
Frasbaserad metod (PBM)
I denna metod analyseras dokumentet baserat på fraser som är mindre uppenbara för mer betydelse och mer diskriminerande. Nackdelarna med denna metod inkluderar
- De har sämre statistiska egenskaper till termer
- De har låg förekomst
- De har ett stort antal bullriga fraser
-
Konceptbaserad metod (CBM)
I denna metod analyseras dokumentet baserat på mening och dokumentnivå. I denna metod finns det tre huvudkomponenter. Den första komponenten undersöker meningarnas meningsfulla del. Den andra komponenten producerar en konceptuell ontologisk graf för att förklara strukturerna. Den tredje komponenten extraherar toppkoncept baserade på de två första komponenterna. Denna metod kan skilja mellan de viktiga och obetydliga orden.
-
Pattern Taxonomy Method (PTM)
I denna metod analyseras dokumentet utifrån mönstren. Mönster i ett dokument kan hittas med hjälp av data mining-tekniker som gruv för associeringsregel, sekventiell gruvbrytning, frekvent gruvdrift och sluten mönsterbrytning. Den här metoden använder två processer - mönsterutsättning och mönsterutveckling. Denna metod har visat sig fungera bättre än alla andra modeller eller metoder.
Hur fungerar Text Mining
Nu borde du ha förstått att textbrytning gör det möjligt att förstå texten bättre än allt annat. Text Mining-systemet gör ett ordutbyte från ostrukturerad data till numeriska värden. Textbrytning hjälper till att identifiera mönster och relationer som finns inom en stor mängd text. Textbrytning använder ofta beräkningsalgoritmer för att läsa och analysera textinformation. Utan textbrytning kommer det att vara svårt att förstå texten enkelt och snabbt. Text kan brytas på ett mer systematiskt och omfattande sätt och informationen om verksamheten kan fångas in automatiskt. Stegen i textbrytningsprocessen listas nedan.
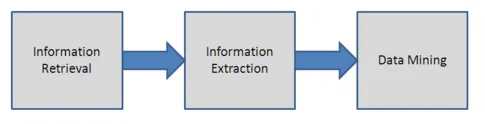
-
Steg 1: Informationssökning
Detta är det första steget i processen för data mining. Detta steg involverar hjälp av en sökmotor för att ta reda på insamlingen av text, även känd som corpus av texter som kan behöva en viss konvertering. Dessa texter bör också sammanföras i ett visst format som är användbart för användarna att förstå. Vanligtvis är XML standarden för textbrytning
-
Steg 2: Natural Language Processing
Detta steg gör att systemet kan utföra grammatisk analys av en mening för att läsa texten. Den analyserar också texten i strukturer.
-
Steg 3: Informationsutvinning
Detta är det andra steget för att identifiera innebörden av en viss textmarkering. I detta steg läggs en metadata till databasen om texten. Det handlar också om att lägga till namn eller platser i texten. Detta steg låter sökmotorn få informationen och ta reda på förhållandena mellan texterna med deras metadata.
-
Steg 4: Data Mining
Det sista steget är data mining med olika verktyg. Detta steg finner likheterna mellan informationen som har samma betydelse som annars är svår att hitta. Text Mining är ett verktyg som ökar forskningen och hjälper till att testa frågorna.
Text Mining innehåller följande lista över element
- Textkategorisering
- Textklustering
- Koncept / enhet utvinning
- Granulära taxonomier
- Sentimentanalys
- Dokumentöversikt
- Modellen för enhetsrelationer
Utmaningar med textbrytning
Den huvudsakliga utmaningen som Text Mining-systemet står inför är det naturliga språket. Det naturliga språket står inför problemet med tvetydighet. Tvetydighet betyder en term som har flera betydelser, en fras tolkas på olika sätt och som ett resultat erhålls olika betydelser.
En annan begränsning är att det använder semantisk analys när man använder informationsutvinningssystem. På grund av detta presenteras inte hela texten, bara en begränsad del av texten presenteras för användarna. Men i dag finns det behov av mer textförståelse.
Text Mining har också begränsningar med upphovsrättslagstiftningen. Det finns många begränsningar i textbrytning av ett dokument. De flesta gånger inkluderar det rättigheterna för upphovsrättsinnehavarna. De flesta av texterna hittas inte som open source och i sådana fall krävs tillstånd från respektive författare, förläggare och andra närstående.
En ytterligare begränsning är att textbrytning genererar inte nya fakta och det är inte en slutprocess.
Slutsats
Textbrytning eller textanalys är en blomstrande teknik men resultaten och analysens djup varierar fortfarande från företag till företag. En organisation kan använda textbrytning för att få kunskap om innehållsspecifika värden.