

Introduktion till Data mining
Detta är en metod för utvinning av data som används för att placera dataelement i deras liknande grupper. Cluster är proceduren för att dela dataobjekt i underklasser. Klusterkvalitet beror på metoden som vi använde. Clustering kallas också datasegmentering eftersom stora datagrupper är indelade efter deras likhet.
Vad är kluster i datakommunikation?
Clustering är gruppering av specifika objekt baserat på deras egenskaper och deras likheter. Vad beträffar data mining, delar denna metod de data som är bäst lämpade för den önskade analysen med hjälp av en speciell kopplingsalgoritm. Denna analys tillåter ett objekt att inte vara en del eller strikt del av ett kluster, vilket kallas den hårda partitioneringen av denna typ. Men släta partitioner antyder att varje objekt i samma grad tillhör ett kluster. Mer specifika uppdelningar kan skapas som objekt av flera kluster, ett enda kluster kan tvingas delta eller till och med hierarkiska träd kan konstrueras i grupprelationer. Detta filsystem kan placeras på olika sätt baserat på olika modeller. Dessa distinkta algoritmer gäller för varje modell och skiljer deras egenskaper såväl som deras resultat. En bra klusteralgoritm kan identifiera klustret oberoende av klusterform. Det finns tre grundläggande steg för klusteralgoritm som visas som nedan
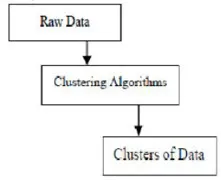
Clustering-algoritmer vid dataanläggning
Beroende på de nyligen beskrivna klustermodellerna kan många kluster användas för att dela information i en uppsättning data. Det bör sägas att varje metod har sina egna fördelar och nackdelar. Valet av en algoritm beror på egenskaperna och typen av datauppsättning.
Clustering Methods for Data Mining kan visas som nedan
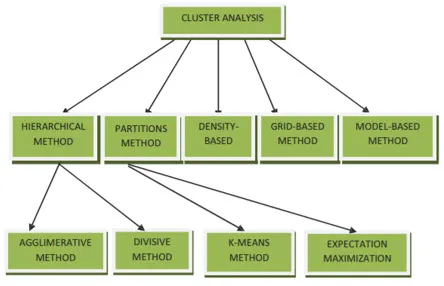
- Partitionsbaserad metod
- Densitetsbaserad metod
- Centroid-baserad metod
- Hierarkisk metod
- Rasterbaserad metod
- Modellbaserad metod
1. Partitionsbaserad metod
Partitionsalgoritmen delar upp data i många delmängder.
Låt oss anta att partitionsalgoritmen bygger upp en partition av data eftersom k och n är att objekt finns i databasen. Därför kommer varje partition att representeras som k ≤ n.
Detta ger en uppfattning om att klassificeringen av uppgifterna är i k-grupper, som kan visas nedan
Figur 1 visar originalpunkter i kluster

Figur 2 visar partitionskluster efter tillämpning av en algoritm
Detta indikerar att varje grupp har minst ett objekt, liksom varje objekt, måste tillhöra exakt en grupp.
2. Densitetsbaserad metod
Dessa algoritmer producerar kluster på en bestämd plats baserat på den höga tätheten för datasatsdeltagare. Den samlar vissa intervallbegrepp för gruppmedlemmar i kluster till en standardnivå för densitet. Sådana processer kan fungera mindre när det gäller att upptäcka gruppens ytor.
3. Centroid-baserad metod
Nästan varje kluster refereras av en vektor med värden i denna typ av os-grupperingsteknik. I jämförelse med andra kluster är varje objekt en del av klustret med en minsta skillnad i värde. Antalet kluster bör fördefinieras, och detta är det största algoritmproblemet av denna typ. Denna metod är närmast identifieringsämnet och används ofta för optimeringsproblem.
4. Hierarkisk metod
Metoden skapar en hierarkisk sönderdelning av en given uppsättning dataobjekt. Baserat på hur den hierarkiska nedbrytningen bildas kan vi klassificera hierarkiska metoder. Denna metod ges enligt följande
- Agglomerativ strategi
- Divisive Approach
Agglomerativ strategi är också känd som Button-up Approach. Här börjar vi med varje objekt som utgör en separat grupp. Det fortsätter att smälta föremål eller grupper nära varandra
Divisive Approach kallas också Top-Down Approach. Vi börjar med alla objekt i samma kluster. Denna metod är stel, dvs den kan aldrig ångras när en fusion eller delning är klar
5. Rasterbaserad metod
Rasterbaserade metoder fungerar i objektutrymmet istället för att dela upp data i ett rutnät. Rutnätet är uppdelat baserat på dataens egenskaper. Genom att använda denna metod är icke-numeriska data lätt att hantera. Datainordning påverkar inte delningen av nätet. En viktig fördel med en nätbaserad modell det ger snabbare körhastighet.
Fördelarna med hierarkisk klustering är följande
- Det är tillämpligt på alla attributtyper.
- Det ger flexibilitet relaterat till graden av granularitet.
6. Modellbaserad metod
Denna metod använder en hypotesiserad modell baserad på sannolikhetsfördelning. Genom att klustera densitetsfunktionen lokaliserar denna metod klusterna. Det återspeglar datapunkternas rumsliga fördelning.
Tillämpning av kluster i Data Mining
Clustering kan hjälpa på många områden som biologi, växter och djur klassificerade efter deras egenskaper såväl som inom marknadsföring. Clustering kommer att hjälpa till att identifiera kunder i en viss kundrekord med liknande beteende. I många applikationer, som marknadsundersökningar, mönsterigenkänning, data och bildbehandling, används klusteranalysen i stort antal. Clustering kan också hjälpa annonsörer i deras kundbas att hitta olika grupper. Och deras kundgrupper kan definieras genom köpmönster. I biologin används den för bestämning av växt- och djurtaxonomier, för kategorisering av gener med liknande funktionalitet och för insikt i populationens inneboende strukturer. I en jordobservationsdatabas gör kluster det också lättare att hitta områden med liknande användning i marken. Det hjälper till att identifiera grupper av hus och lägenheter efter hus, typ och värde. Clustering av dokument på webben är också användbart för att upptäcka information. Klusteranalysen är ett verktyg för att få insikt i distributionen av data för att observera egenskaperna hos varje kluster som en data mining-funktion.
Slutsats
Clustering är viktigt vid datainsamling och dess analys. I den här artikeln har vi sett hur kluster kan göras genom att tillämpa olika klusteralgoritmer och dess tillämpning i verkligheten.
Rekommenderad artikel
Detta har varit en guide till What is Clustering in Data Mining. Här diskuterade vi begreppen, definitionen, funktioner, tillämpningen av Clustering i Data Mining. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Vad är databehandling?
- Hur blir man en analytiker?
- Vad är SQL-injektion?
- Definition av vad är SQL Server?
- Översikt över Data Mining Architecture
- Clustering in Machine Learning
- Hierarkisk klusteralgoritm
- Hierarkisk klustering Agglomerativ & delande kluster