
Introduktion till Bagging and Boosting
Bagging and Boosting är de två populära Ensemble Methods. Så innan vi förstår Bagging and Boosting, låt oss ha en uppfattning om vad som är ensemble Learning. Det är tekniken att använda flera inlärningsalgoritmer för att träna modeller med samma datasats för att få en förutsägelse i maskininlärning. Efter att ha fått förutsägelsen från varje modell kommer vi att använda modellgenomsnittstekniker som viktat genomsnitt, varians eller max röstning för att få den slutliga förutsägelsen. Denna metod syftar till att få bättre förutsägelser än den enskilda modellen. Detta resulterar i bättre noggrannhet för att undvika övermontering och minskar förspänning och samvarians. Två populära ensemblemetoder är:
- Bagging (Bootstrap Aggregating)
- öka
Säckväv:
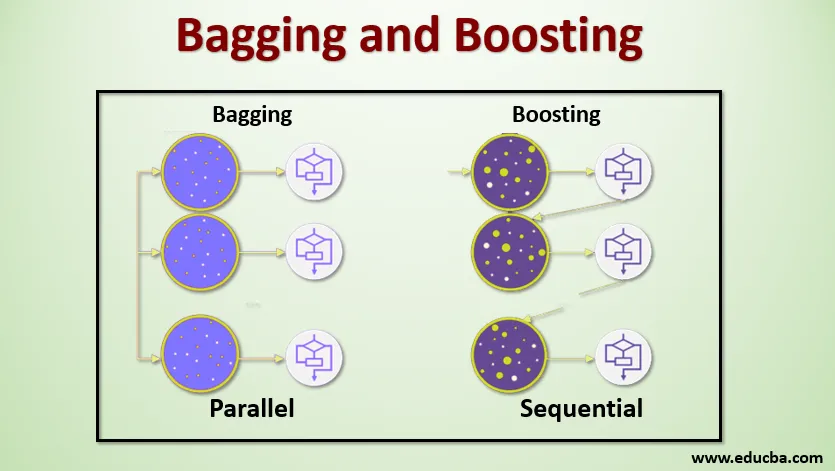
Bagging, även känd som Bootstrap Aggregating, används för att förbättra noggrannheten och gör modellen mer generaliserad genom att minska variationen, dvs genom att undvika övermontering. I detta tar vi flera delmängder av träningsdatasättet. För varje delmängd tar vi en modell med samma inlärningsalgoritmer som beslutsträd, logistisk regression etc. för att förutsäga utgången för samma uppsättning testdata. När vi har en förutsägelse från varje modell använder vi en modellgenomsnittsteknik för att få den slutliga förutsägelsen. En av de berömda teknikerna som används i Bagging är Random Forest . I den slumpmässiga skogen använder vi flera beslutsträd.
Öka :
Boosting används främst för att minska förspänningen och variansen i en övervakad inlärningsteknik. Det hänvisar till familjen till en algoritm som konverterar svaga elever (baselever) till starka elever. Den svaga eleven är klassificerare som bara är korrekta i liten utsträckning med den faktiska klassificeringen, medan de starka eleverna är klassificerare som är väl korrelerade med den faktiska klassificeringen. Få berömda tekniker för Boosting är AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Så nu vet vi vad bagging och boosting är och vilka är deras roller i Machine Learning.
Arbeta med bagging och boosting
Låt oss nu förstå hur bagging och boosting fungerar:
Säckväv
För att förstå hur Bagging fungerar, antar vi att vi har ett N-antal modeller och en Dataset D. Där m är antalet data och n är antalet funktioner i varje data. Och vi ska göra binär klassificering. Först kommer vi att dela upp datasatsen. För tillfället kommer vi bara dela upp detta datasätt i utbildnings- och testuppsättningar. Låt oss kalla utbildningsdataset som var det totala antalet träningsexempel är.
Ta ett urval av poster från träningsuppsättningen och använd den för att träna den första modellen säg m1. För nästa modell, prova m2 träningsuppsättningen och ta ytterligare ett prov från träningsuppsättningen. Vi kommer att göra samma sak för N-antalet modeller. Eftersom vi resamplar utbildningsdatasättet och tar proverna ur det utan att ta bort något från datasatsen, kan det vara möjligt att vi har två eller flera träningsdataposter som är vanliga i flera prover. Denna teknik för att återampla träningsdatasättet och tillhandahålla provet till modellen kallas Row Sampling with Replacement. Anta att vi har tränat varje modell och nu vill vi se prognosen på testdata. Eftersom vi arbetar med binär klassificering kan utgången vara antingen 0 eller 1. Testdatan skickas till varje modell, och vi får en förutsägelse från varje modell. Låt oss säga att av N-modellerna mer än N / 2-modeller förutspådde att det skulle vara 1, Därför Genom att använda modellgenomsnittstekniken som maximal röst, kan vi säga att den förutsagda utgången för testdata är 1.
öka
Genom att öka tar vi poster från datasatsen och skickar den till baselever i följd, här kan baselever vara vilken modell som helst. Anta att vi har ett antal poster i datasatsen. Sedan skickar vi några poster för att basera eleven BL1 och utbilda den. När BL1 har tränats skickar vi alla poster från datasatsen och ser hur Base-eleven fungerar. För alla poster som är klassificerade felaktigt av baselever, tar vi dem bara och skickar den till andra baselever säger BL2 och samtidigt passerar vi felaktiga poster klassificerade av BL2 för att träna BL3. Detta kommer att fortsätta såvida inte och tills vi anger något specifikt antal baselevermodeller vi behöver. Slutligen kombinerar vi utgången från dessa baselever och skapar en stark elev, som ett resultat förbättras modellens förutsägelseskraft. Ok. Så nu vet vi hur Bagging and Boosting fungerar.
Fördelar och nackdelar med Bagging och Boosting
Nedan ges de bästa fördelarna och nackdelarna.
Fördelar med Bagging
- Den största fördelen med påsar är att flera svaga elever kan arbeta bättre än en enda stark elev.
- Det ger stabilitet och ökar noggrannheten för maskininlärningsalgoritmen som används vid statistisk klassificering och regression.
- Det hjälper till att minska variansen, dvs det undviker överanpassning.
Nackdelar med Bagging
- Det kan leda till hög förspänning om den inte modelleras korrekt och därmed kan leda till undermontering.
- Eftersom vi måste använda flera modeller blir det beräkningsbart dyrt och kanske inte lämpligt i olika användningsfall.
Fördelar med Boosting
- Det är en av de mest framgångsrika teknikerna för att lösa klassificeringsproblemen i två klass.
- Det är bra på att hantera de saknade uppgifterna.
Nackdelar med att öka
- Boosting är svårt att implementera i realtid på grund av den ökade komplexiteten hos algoritmen.
- Hög flexibilitet för denna teknik resulterar i ett flertal parametrar än som har en direkt effekt på modellens beteende.
Slutsats
Den viktigaste takeawayen är att Bagging and Boosting är ett maskininlärningsparadigm där vi använder flera modeller för att lösa samma problem och få en bättre prestation. I den här artikeln har jag gett en grundläggande översikt över Bagging and Boosting. I de kommande artiklarna kommer du att lära känna de olika teknikerna som används i båda. Slutligen avslutar jag med att påminna er om att Bagging and Boosting är en av de mest använda teknikerna för lärande av ensemble. Den verkliga konsten att förbättra prestandan ligger i din förståelse för när du ska använda vilken modell och hur du ställer in hyperparametrarna.
Rekommenderade artiklar
Detta är en guide till Bagging and Boosting. Här diskuterar vi introduktionen till bagging and Boosting och det fungerar tillsammans med fördelar och nackdelar. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Introduktion till Ensembeltekniker
- Kategorier av maskininlärningsalgoritmer
- Gradient Boosting Algoritm med provkod
- Vad är den boostande algoritmen?
- Hur man skapar beslutsträd?