

Introduktion till Apache Flume
Apache Flume är Data Ingestion Framework som skriver händelsebaserad data till Hadoop Distribuerat filsystem. Det är ett känt faktum att Hadoop bearbetar Big data, en fråga uppstår hur data som genereras från olika webbservrar överförs till Hadoop File System? Svaret är Apache Flume. Flume är utformad för hög volymdata till Hadoop av händelsebaserad data.
Överväg ett scenario där antalet webbservrar genererar loggfiler och dessa loggfiler måste sändas till Hadoop-filsystemet. Flume samlar filerna som händelser och tar dem in i Hadoop. Även om Flume används för att sända till Hadoop, finns det ingen rigid regel att destinationen måste vara Hadoop. Flume kan skriva till andra ramverk som Hbase eller Solr.
Flume Architecture
I allmänhet består Apache Flume-arkitekturen av följande komponenter:
- Flume källa
- Flume Channel
- Flume Sink
- Flume Agent
- Flume Event
Låt oss ta en kort titt på varje Flume-komponent
1. Flumkälla
En Flume Source finns på datageneratorer som Face Book eller Twitter. Källa samlar in data från generatorn och överför dessa data till Flume Channel i form av Flume Events. Flume stöder olika typer av källor som Avro Flume Source - ansluter till Avro-porten och tar emot händelser från Avro extern klient, Thrift Flume Source-ansluter till Thrift-porten och tar emot händelser från externa Thrift-klientströmmar, Spooling Directory Source och Kafka Flume Source.
2. Flume Channel
En mellanlager som buffrar händelser som skickats av Flume Source tills de konsumeras av Sink kallas Flume Channel. Channel fungerar som en mellanbro mellan Source och Sink. Flume-kanaler är transaktionerliga till sin natur.
Flume ger stöd för filkanalen och minneskanalen. Filkanalen är hållbar i sin natur vilket innebär att när data har skrivits för att kanal kommer de inte att gå förlorade, även om agenten startar om. I minnet lagras kanalhändelser i minnet, så det är inte hållbart men väldigt snabbt.
3. Flume Sink
En Flume Sink finns på databaser som HDFS, HBase. Flume sink förbrukar händelser från Channel och lagrar dem till Destination butiker som HDFS. Det finns ingen sådan regel att tvättstället ska leverera händelser till Store, istället kan vi konfigurera det på ett sådant sätt att ett sjunker kan leverera händelser till en annan agent. Flume stöder olika sänkor som HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
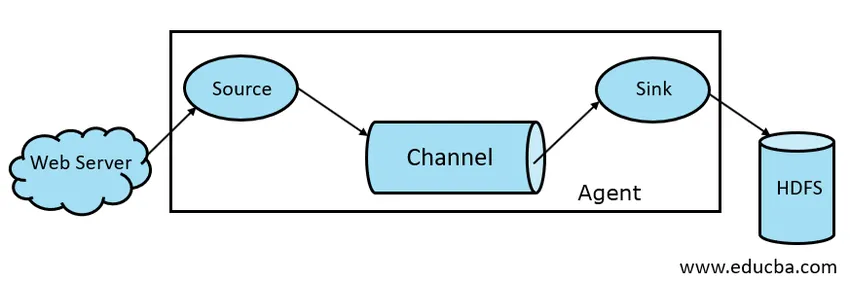
Fig 1.1 Grundläggande flumearkitektur
4. Flume Agent
En Flume-agent är en långvarig Java-process som körs på Source - Channel - Sink Combination. Flume kan ha mer än ett medel. Vi kan betrakta Flume som en samling anslutna Flume-agenter som distribueras i naturen.
5. Flume-händelse
En händelse är den dataenhet som transporteras i Flume . Allmän representation av Data Object i Flume kallas Event. Händelsen består av en nyttolast av en byte-grupp med valfri rubriker.
Working of Flume
En Flume-agent är en java-process som består av Source - Channel - Sink i sin enklaste form. Källa samlar in data från datagenerator i form av händelser och levererar dem till Channel. En källa kan levereras till flera kanaler enligt krav. Fan out är processen där en enda källa kommer att skriva till flera kanaler så att de kan leverera till flera sänkor.
En händelse är den basenhet för data som överförs i Flume. Kanalen buffrar data tills det intas av Sink. Sink samlar in data från Channel och levererar dem till centraliserad datalagring som HDFS eller Sink kan vidarebefordra att händelser till en annan Flume-agent enligt krav.
Flume stöder transaktioner. För att uppnå tillförlitlighet använder Flume separata transaktioner från källa till kanal och från kanal till sänk. Om händelser inte levereras, rullas transaktionen tillbaka och levereras senare.
För att förstå hur Flume fungerar, låt oss ta ett exempel på Flume-konfiguration där källan spolar katalogen och sink är Hdfs. I det här exemplet är Flume-agenten i den enklaste formen, det vill säga topology med enkel källa - kanal - diskbänk som är konfigurerad med en javaegenskapsfil.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
I ovanstående konfigurationsexempel är agent basen med vilken vi definierar andra egenskaper. source1 och sink1 och channel1 är namnen på källa respektive sink och channel samt deras typer och platser nämns också i enlighet därmed.
Fördelar med Apache Flume
- Flume är skalbar, pålitlig och feltolerant. Dessa egenskaper diskuteras i detalj nedan
- Skalbar - Flume är skalbar horisontellt, dvs vi kan lägga till nya noder enligt vårt krav
- Pålitlig - Apache Flume har stöd för transaktioner och ser till att ingen data går förlorad i processen med dataöverföring. Det har olika transaktioner från källa till kanal och från kanal till källa.
- Flume kan anpassas och ger stöd för olika källor och sänkor som Kafka, Avro, spooling directory, Thrift etc
- I Flume kan en källa överföra data till flera kanaler och dessa kanaler i sin tur kommer att överföra data till flera sänkor, så att enskild källa kan sända data till flera sänkor. Denna mekanism kallas Fan ut. Flume stöder också för Fan ut.
- Flume tillhandahåller det stadiga flödet av dataöverföring, dvs om dataläsningshastigheten ökar och datahastigheten också ökar.
- Även om Flume generellt skriver data till centraliserad lagring som HDFS eller Hbase, kan vi konfigurera Flume enligt vårt krav så att Sink kan skriva data till en annan agent. Detta visar Flume flexibilitet
- Apache Flume är öppen källkod.
Slutsats
I denna Flume-artikel diskuteras komponenter i Flume och bearbetning av Flume i detalj. Flume är en flexibel, pålitlig och skalbar plattform för att överföra data till en centraliserad butik som HDFS. Dess förmåga att integrera med olika applikationer som Kafka, Hdfs, Thrift gör det till ett genomförbart alternativ för intag av data.
Rekommenderade artiklar
Detta har varit en guide till Apache Flume. Här diskuterar vi arkitektur, arbete och fördelar med Apache Flume. Du kan också titta på följande artiklar för att lära dig mer -
- Vad är Apache Flink?
- Skillnaden mellan Apache Kafka vs Flume
- Big Data Arkitektur
- Hadoop Tools
- Lär dig de olika JavaScript-händelserna