

Skillnaden mellan Apache Hive och Apache HBase -
Apache Hive-berättelsen börjar år 2007 då icke Java-programmerare måste kämpa när han använder Hadoop MapReduce. Forskare och utvecklare förutspådde att morgondagen är en era av Big Data. Redan olika dataformat som strukturerade, semistrukturerade och ostrukturerade staplade upp. Till och med Facebook kämpade med den större mängden databehandling. Forskare på Facebook introducerade Apache Hive för databehandling i Hadoop Cluster. Facebook var det första företaget som kom med Apache Hive.
Apache HBase-berättelsen börjar 2006 när den San Francisco-baserade uppstarten Powerset försökte bygga en naturlig sökmotor för webben. HBase är en implementering av Googles Bigtable. Har vi någonsin insett varför det fanns behov av att komma med ännu en lagringsarkitektur? Relational Database Management System har funnits sedan början av 1970-talet. Det finns många användningsfall där relationella databaser är perfekt men för vissa specifika problem passar inte relationsmodellen särskilt bra.
Låt mig förklara mer om Apache Hive och Apache HBase.
Skillnader mellan Apache Hive och Apache HBase
Apache Hive är ett Apache-öppet källkodsprojekt som byggs ovanpå Hadoop för att fråga, sammanfatta och analysera stora datamängder med ett SQL-liknande gränssnitt. Apache Hive tillhandahåller ett SQL-liknande språk som kallas HiveQL, som transparent konverterar frågor till MapReduce för exekvering på stora datasätt lagrade i Hadoop Distribuerat filsystem (HDFS). Apache Hive är en Hadoop-klusterkomponent som normalt distribueras av dataanalytiker. Apache-bikupa används för batchbehandling av stora ETL-jobb. Apache Hive stöder också batch SQL-frågor på mycket stora datasätt. Apache Hive ökar schemat designflexibilitet och även dataserialisering och deserialisering. Apache Hive stöder inte OLTP (Online Transaction Processing) eftersom hive inte stöder frågor i realtid och radnivåuppdateringar.
Apache HBase är en open source NoSQL-databas som ger realtids-, läs- och skrivåtkomst till stora datasätt. NoSQL är en icke-relationell databas. Apache HBase är distribuerad kolumnorienterad databas som körs ovanpå Hadoop Distribuerat filsystem (HDFS). Så HBase ger fördelarna med NoSQL till Hadoop. Apache HBase tillhandahåller slumpmässiga åtkomstfunktioner för data som finns i HDFS. Den utnyttjar feltoleransen från HDFS. Användaren kan lagra data i HDFS antingen direkt eller genom HBase.
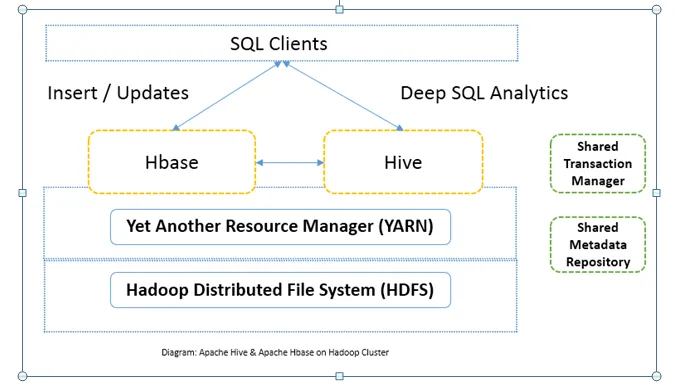
Jämförelse mellan huvud och huvud mellan Apache Hive vs Apache HBase (Infographics)
Nedan visas topp 12 skillnaden mellan Apache Hive och Apache HBase

Viktiga skillnader - Apache Hive vs Apache HBase
Nedan finns listor med punkter som beskriver de viktigaste skillnaderna mellan Apache Hive och Apache HBase:
- Apache HBase är en databas medan Apache Hive är en databasmotor.
- Apache Hive används främst för batchbehandling (OLAP) medan Apache HBase främst används för transaktionsbearbetning (OLTP).
- Apache Hive kör de flesta SQL-frågor medan Apache HBase inte tillåter SQL-frågor direkt.
- Apache Hive stöder inte postnivåoperationer som uppdatering, infogning och radering medan Apache HBase stöder postnivåoperationer som uppdatering, infogning och radering.
- Apache Hive körs ovanpå MapReduce medan Apache HBase körs ovanpå Hadoop Distribuerat filsystem (HDFS).
Apache Hive frågar filerna genom att definiera en virtuell tabell och köra HQL-frågor ovanpå den. Det är en process där filer praktiskt taget är anslutna till en tabell som struktur och användaren kan köra Hive Query Language (HQL) och dessa frågor konverteras till MapReduce Job by Hive. Användaren behöver inte skriva MapReduce-jobb, HQL-frågor konverteras internt till burkfiler och dessa burkfiler kommer att implementeras på datasätt.
I Apache HBase delas tabeller upp i regioner och betjänas av regionens servrar. Ytterligare regioner delas vertikalt av kolumnfamiljer i butiker och butiker sparas som filer i HDFS.
När du ska använda Apache Hive:
- Krav på datalagring
- Analytiska frågor
- Dataanalys som känner till SQL
När du ska använda Apache HBase:
- Snabb och interaktiv databehandling
- Frågor i realtid
- Snabba uppslag
- Behandling på serversidan
- Slumpmässig läs / skrivåtkomst till Big Data
- Applikationens skalbarhet
Apache Hive kan användas för att beräkna trender och loggar på e-handelswebbplatsen för viss varaktighet, region eller tidszon. Den kan användas för att behandla batchfråga över historiska data, medan Apache HBase kan användas av Facebook eller LinkedIn för meddelanden och analys i realtid. Det kan också användas för att räkna likes.
Apache Hive vs Apache HBase jämförelsetabell
Jag diskuterar stora artefakter och skiljer mellan Apache Hive och Apache HBase.
| Apache Hive | Apache HBase | |
| Databehandling | Apache Hive används för
batchbehandling dvs Online Analytical Processing (OLAP) | Apache HBase används för transaktionsbearbetning, dvs Online Transactionional Processing (OLTP) |
| Bearbetar hastighet | Apache Hive har högre latens på grund av att MapReduce-jobb körs i bakgrunden | Apache HBase arbetar med realtidsfrågor och mycket snabbare än Apache Hive |
| Kompatibilitet med Hadoop | Apache Hive kör ovanpå MapReduce | Apache HBase körs ovanpå HDFS |
| Definition | Apache Hive är öppen källkod och liknar SQL som används för analytiska frågor | Apache HBase är en open source NoSQL-databas som används för realtidsfrågor |
| Delad metadata | Data skapade i Apache Hive syns automatiskt för Apache HBase | Data skapade i Apache HBase är automatiskt synliga för Apache Hive |
| schema | Apache-bikupa stöder schema för att infoga data i tabeller | Apache HBase är schemafri databas. |
| Uppdatera funktionen | Uppdateringsfunktionen är komplicerad i Apache Hive | Användaren kan mycket enkelt uppdatera data i Apache HBase |
| Operationer | Verksamheten i Apache Hive körs inte i realtid | Verksamheten i Apache HBase körs i realtid |
| Datatyper | Apache Hive är avsett för strukturerade och semistrukturerade data | Apache HBase är för ostrukturerad data. |
| Konsistensnivå | Apache-bikupan stöder eventuell konsistens | Apache HBase stöder omedelbar konsistens |
| Partitionsmetoder | Apache Hive stöder skärmningsfunktioner | Apache HBase stöder också skärmningsfunktioner |
| Datalagring | Datumet lagras i Hive Metastore, Partitioner och hinkar i Apache Hive | Data lagras i kolumnen och raden av tabeller i Apache HBase |
Slutsats - Apache Hive vs Apache HBase
Vanligtvis används Apache Hive vs Apache HBase tillsammans i samma kluster. Båda kan användas tillsammans för att förbättra processorkraften. Eftersom bikupa förbättrar de analytiska sidorna på HDFS medan HBase förbättrar transaktioner i realtid. Användaren kan använda Hive som ETL-verktyg för batchinsatser med data till HBase och sedan för att utföra frågor som ytterligare kan ansluta data som finns i HBas-tabeller med de data som redan finns på HDFS. Data kan läsas och skrivas från Apache Hive till HBase och tillbaka igen. Gränssnittet mellan Apache Hive och Apache HBase är fortfarande moget. Det kommer mycket mer att komma. Jag kan ändå säga Både Apache Hive vs Apache HBase gör Hadoop-kluster mer robust och kraftfull.
Relaterade artiklar:
Detta har varit en guide till Apache Hive vs Apache HBase, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Topp 5 stora datatrender
- 5 utmaningar med Big Data Analytics
- Hur knäcker Hadoop utvecklarintervju?
- 5 utmaningar med Big Data Analytics