

Introduktion till Map Join in Hive
Map join är en funktion som används i Hivefrågor för att öka dess effektivitet när det gäller hastighet. Join är ett villkor som används för att kombinera data från två tabeller. Så när vi utför en normal sammankoppling skickas jobbet till en kartminskningsuppgift som delar huvuduppgiften i två steg - "Kartscen" och "Minska scenen". Kartsteget tolkar ingångsdata och returnerar utgången till reduceringssteget i form av nyckelvärdespar. Den här nästa går genom shuffle-scenen där de sorteras och kombineras. Minskaren tar det här sorterade värdet och slutför sammanfogningsjobbet.
En tabell kan laddas helt i minnet i en mapper och utan att behöva använda Map / Reducer-processen. Den läser uppgifterna från det mindre bordet och lagrar dem i en hash-tabell i minnet och sedan serialiserar den till hashminnesfilen, vilket reducerar tiden avsevärt. Det är också känt som Map Side Join in Hive. I grund och botten handlar det om att utföra sammanfogningar mellan två tabeller genom att bara använda kartfasen och hoppa över minska-fasen. En tidsminskning i beräkningen av dina frågor kan observeras om de regelbundet använder en liten tabellkoppling.
Syntax för karta Gå med i Hive
Om vi vill utföra en anslutningsfråga med hjälp av map-join måste vi ange ett nyckelord “/ * + MAPJOIN (b) * /” i uttalandet enligt nedan:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
I det här exemplet måste vi skapa 2 tabeller med namnen tablename1 och tablename2 med två kolumner: emp_id och emp_name. En bör vara en större fil och en bör vara en mindre.
Innan frågan körs måste vi ställa in egenskapen nedan till true:
hive.auto.convert.join=true
Samlingsfrågan för kartanslutning skrivs som ovan och resultatet vi får är:
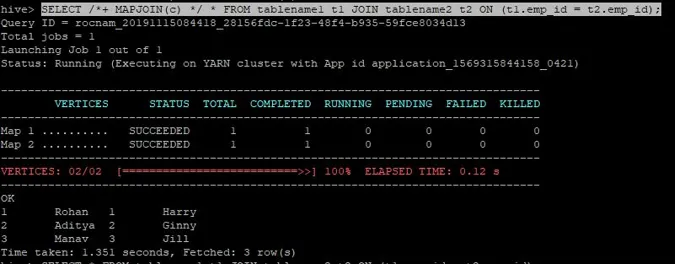
Frågan slutfördes på 1.351 sekunder.
Exempel på Map Join in Hive
Här är följande exempel som nämns nedan
1. Exempel på Map join
Låt oss för detta exempel skapa två tabeller med namnet tabell1 och tabell2 med 100 respektive 200 poster. Du kan hänvisa nedanstående kommando och skärmdumpar för att utföra samma:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Nu laddar vi posterna i båda tabellerna med hjälp av kommandon nedan:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
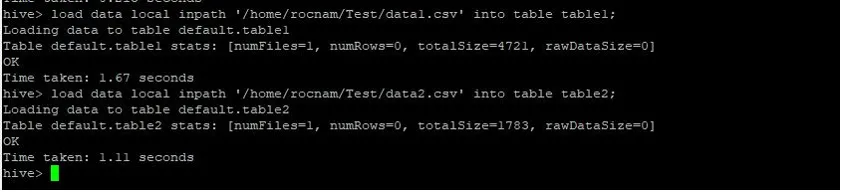
Låt oss utföra en normal kartfogningsfråga på deras ID som visas nedan och verifiera den tid det tar för samma:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
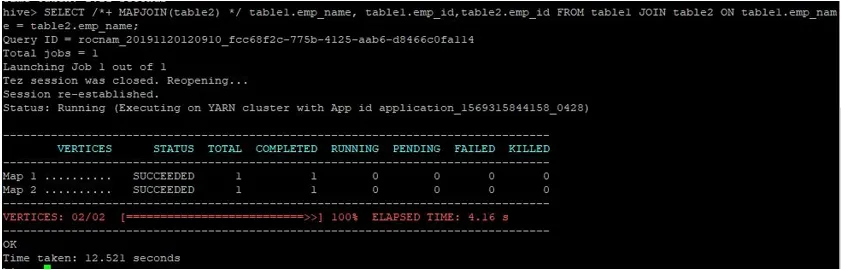
Som vi kan se tog en vanlig fråga om kartfogning 12.521 sekunder.
2. Exempel på en hink-karta
Låt oss nu använda Bucket-map join för att köra samma sak. Det finns några begränsningar som måste följas för bucketing:
- Skoporna kan förenas med varandra endast om de totala skoporna i någon tabell är multipla av antalet skopor i den andra tabellen.
- Måste ha bucketed tabeller för att utföra bucketing. Låt oss därför skapa detsamma.
Följande är de kommandon som används för att skapa bucklade tabeller tabell 1 och tabell2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Vi ska också infoga samma poster från tabell1 i dessa bockade tabeller:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
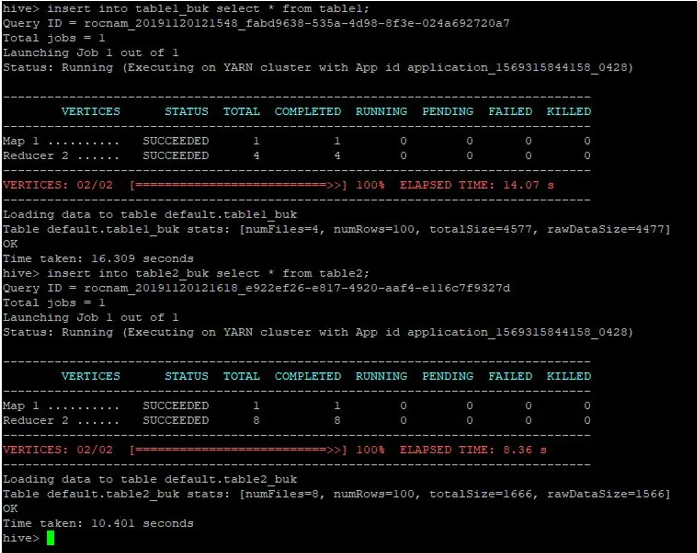
Nu när vi har våra två bucketed-tabeller, låt oss utföra en skopa-kartläggning på dessa. Det första bordet har 4 hinkar medan det andra bordet har 8 hinkar skapade i samma kolumn.
För att kopplingsfrågan med hinkkarta ska fungera bör vi ställa in egenskapen nedan till sann i bikupan:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
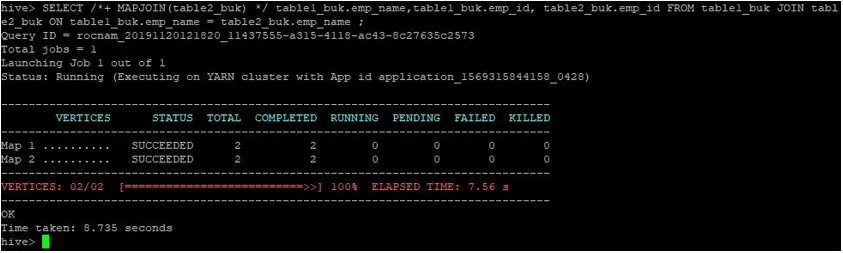
Som vi ser slutfördes frågan på 8.735 sekunder, vilket är snabbare än en vanlig kartuppkoppling.
3. Sortera exempel på sammanslagning av hinkkarta (SMB)
SMB kan utföras på bockade bord med samma antal hinkar och om tabellerna måste sorteras och bockas i sammanfogningskolumner. Mapper-nivå ansluter sig till dessa skopor på motsvarande sätt.
Samma som i hink-kartfogning finns det 4 hinkar för bord1 och 8 hinkar för bord2. I det här exemplet ska vi skapa en annan tabell med fyra hinkar.
För att köra SMB-fråga måste vi ställa in följande bikupegenskaper som visas nedan:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
För att utföra SMB-anslutning måste data sorteras enligt kolumnerna. Därför skriver vi över data i tabell1 som är anpassade enligt nedan:
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Data sorteras nu, vilket kan ses i nedanstående skärmdump:
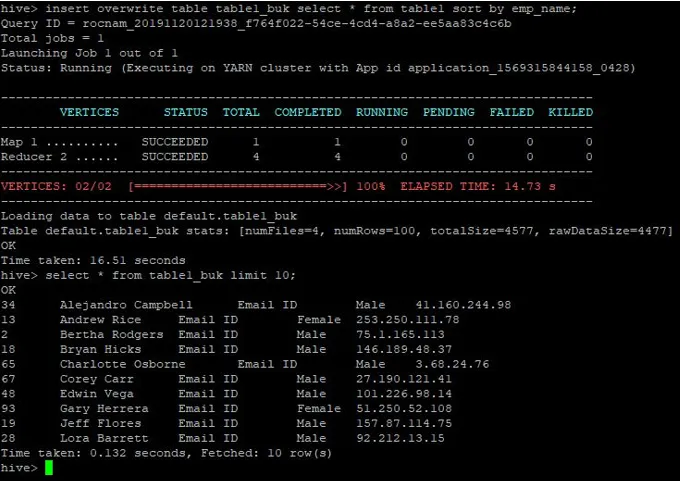
Vi kommer också att skriva över data i skopad tabell2 enligt nedan:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Låt oss utföra kopplingen för ovanstående två tabeller enligt följande:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
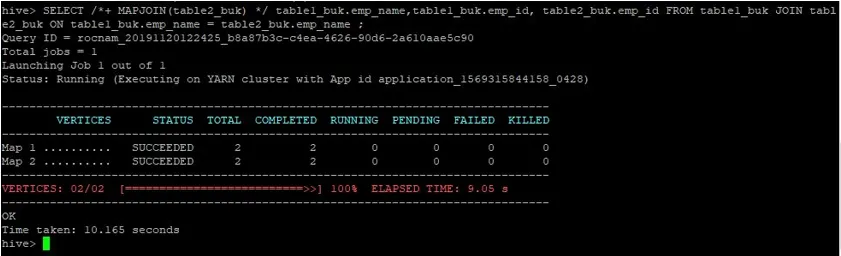
Vi kan se att frågan tog 10, 165 sekunder, vilket igen är bättre än en vanlig kartuppsamling.
Låt oss nu skapa en annan tabell för tabell2 med fyra hinkar och samma data sorterade med emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
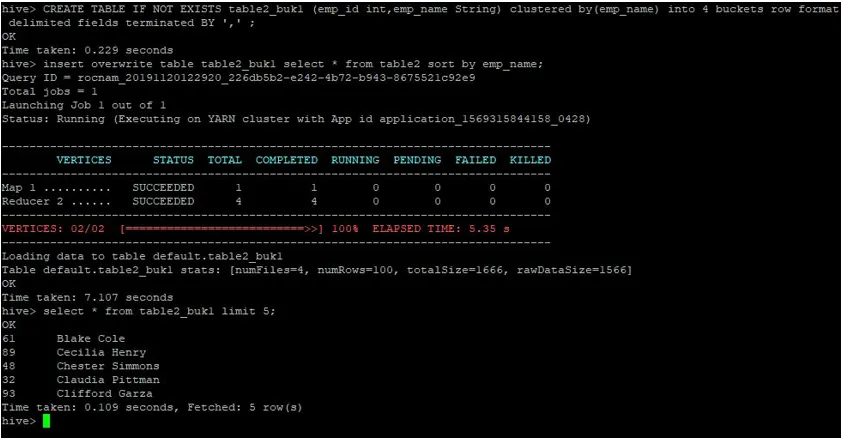
Med tanke på att vi nu har båda borden med fyra hinkar, låt oss återigen utföra en kopplingsfråga.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
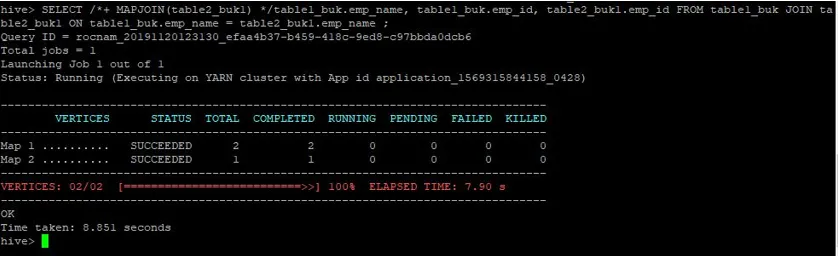
Frågan har tagit 8.851 sekunder igen snabbare än den vanliga kartfogningen.
fördelar
- Kartfogning minskar den tid det tar för sorterings- och sammanslagningsprocesser som sker i blandningen och minskar stadierna och minimerar också kostnaderna.
- Det ökar prestandans effektivitet för uppgiften.
begränsningar
- Samma tabell / alias får inte användas för att gå med i olika kolumner i samma fråga.
- Frågan om sammanfogning av kartor kan inte konvertera Fullständiga yttre sammanfogningar till kortsidesfogar.
- Kartbindning kan endast utföras när ett av tabellerna är tillräckligt litet så att det kan passa i minnet. Därför kan det inte utföras där tabelldata är enorma.
- En vänster sammanfogning är möjlig att göra för en kartanslutning endast när rätt bordstorlek är liten.
- En högerkoppling är möjlig att göra till en kartanslutning endast när den vänstra tabellstorleken är liten.
Slutsats
Vi har försökt ta med de bästa möjliga punkterna på Map Join in Hive. Som vi har sett ovan fungerar Map-side-samverkan bäst när en tabell har mindre data så att jobbet blir slutfört snabbt. Tiden för de frågor som visas här beror på datasättets storlek, varför den tid som visas här endast är för analys. Kartbindning kan enkelt implementeras i realtidsapplikationer eftersom vi har enorma data och därmed hjälper till att minska I / O-trafik i nätverket.
Rekommenderade artiklar
Detta är en guide till Map Join in Hive. Här diskuterar vi exemplen på Map Join in Hive tillsammans med fördelar och begränsningar. Du kan också titta på följande artikel för att lära dig mer -
- Går med i Hive
- Hive Inbyggda funktioner
- Vad är en bikupa?
- Hive-kommandon