

Introduktion till Hive-kommandon
Hive-kommando är ett datalagerinfrastrukturverktyg som sitter ovanpå Hadoop för att sammanfatta Big data. Det bearbetar strukturerade data. Det underlättar datasökning och analys. Hive-kommando kallas också som "schema vid läsning;" Hive verifierar inte data när det laddas, verifiering sker bara när en fråga utfärdas. Den här egenskapen hos Hive gör det snabbt för första laddning. Det är som att kopiera eller helt enkelt flytta en fil utan att sätta några begränsningar eller kontroller. Hive utvecklades först av Facebook. Apache Software Foundation tog upp det senare och utvecklade det vidare.
Här är komponenterna i Hive-kommandot:
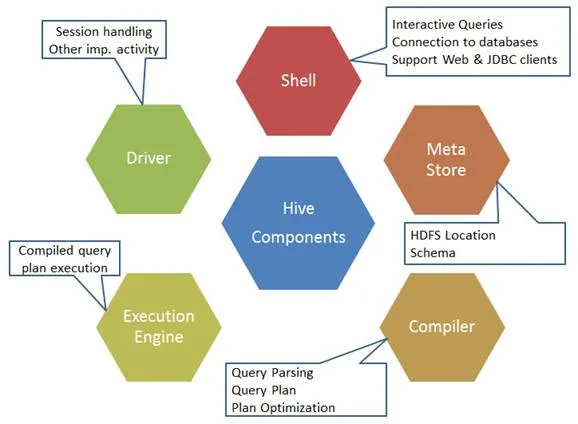
Fig 1. Komponenter i Hive
https://www.developer.com/
Här är kommandot Features of Hive listade nedan:
- Hive-butiker är råa och bearbetade datasätt i Hadoop.
- Det är utformat för OnLine Transaction Processing (OLTP). OLTP är de system som underlättar data med hög volym på mycket kortare tid utan att förlita sig på den enda servern.
- Det är snabbt, skalbart och pålitligt.
- Frågespråket av SQL-typ som anges här kallas HiveQL eller HQL. Detta underlättar ETL-uppgifter och annan analys.
Fig 2. Hiveegenskaper
Källor bilder: - Google
Det finns få begränsningar av Hive-kommandot också, som listas nedan:
- Hive stöder inte undersökningar.
- Hive stöder säkert överskrivning, men tyvärr stöder det inte radering och uppdateringar.
- Hive är inte designad för OLTP, men den används för den.
För att gå in i Hive's interaktiva skal:
$ HIVE_HOME / bin / bikupa
Grundläggande Hive-kommandon
-
Skapa
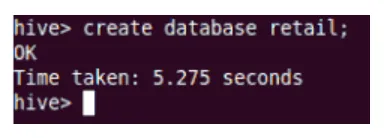
Detta skapar den nya databasen i Hive.
-
Släppa
Släppet tar bort ett bord från Hive
-
Ändra
Ändra kommando hjälper dig att byta namn på tabellen eller tabellkolumnerna.
Till exempel:
hive> ALTER TABELL anställd RENAME TO anställd1;
-
Visa
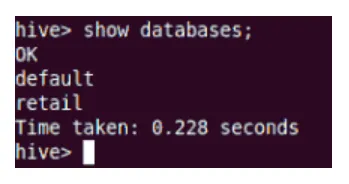
Visa-kommando visar alla databaser som finns i Hive.
-
Beskriva
Beskriv kommando hjälper dig med informationen om schemat i tabellen.
Mellan Hive-kommandon
Hive delar upp en tabell i olika relaterade partitioner baserade på kolumner. Med hjälp av dessa partitioner blir det lättare att fråga data. Dessa partitioner delas vidare upp i hinkar för att köra frågan effektivt till data.
Med andra ord distribuerar skopor data till uppsättningen kluster genom att beräkna hashkoden för nyckeln som nämns i frågan.
-
Lägger till partition
Lägga till partition kan åstadkommas genom att ändra tabellen. Säg att du har tabellen "EMP", med fält som Id, Namn, Lön, Inst., Beteckning och yoj.
hive> ALTER TABLE anställd
> LÄGG TILL DELNING (år = '2012')
plats '/ 2012 / del2012';
-
Byt namn på partition
hive> ALTER TABELL ANTAL AV MEDARBETARE (år = '1203')
RENAME TO PARTITION (Yoj = '1203');
-
Släpp partition
hive> ALTER TABELL DROP för anställda (OM EXISTER)
> DELITION (år = '1203');
-
Relationsoperatörer
Relationsoperatörer består av en viss uppsättning operatörer, som hjälper till att hämta relevant information.
Exempel: Säg att tabellen "EMP" ser ut så här:
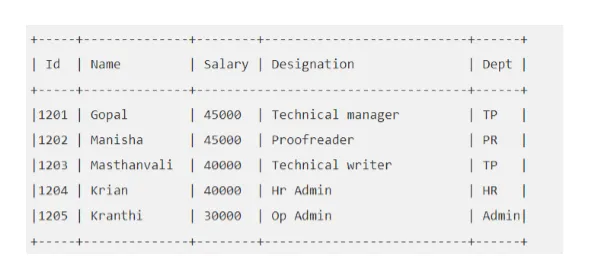
Låt oss utföra Hivefråga som hämtar oss den anställda vars lön är större än 30000.
bikupa> VÄLJ * FRÅN EMP VAR Lön> = 40000;
-
Aritmetiska operatörer
Dessa är operatörer som hjälper till med att utföra aritmetiska operationer på operanderna och i sin tur alltid returnerar nummertyper.
Till exempel: Att lägga till två nummer, t.ex. 22 & 33
bikupa> VÄLJ 22 + 33 LÄGG TILL FRÅN temp;
-
Logisk operatör
Dessa operatörer ska utföra logiska operationer, som i gengäld alltid returnerar True / False.
bikupa> VÄLJ * FRÅN EMP VAR Lön> 40000 && Avd. = TP;
Avancerade Hive-kommandon
-
Se
Visa-konceptet i Hive är liknande som i SQL. Vyn kan skapas vid körning av ett SELECT-uttalande.
Exempel:
hive> CREATE VIEW EMP_30000 AS
VÄLJ * FRÅN EMP
VAR lön> 30000;
-
Laddar data i tabellen
Hive> Ladda data lokal inpath '/home/hduser/Desktop/AllStates.csv' i tabellstater;
Här är "States" den redan skapade tabellen i Hive.
https://www.tutorialspoint.com/hive/
Hive har några inbyggda funktioner som hjälper dig att hämta ditt resultat på ett bättre sätt.
Som runda, golv, BIGINT etc.
-
Ansluta sig
Kopplingsklausul kan hjälpa dig att gå med i två tabeller baserade på samma kolumnnamn.
Exempel:
hive> VÄLJ c.ID, c.NAME, c.AGE, o.AMOUNT
FRÅN KUNDER c GÅ MED ORDERS o
ON (c.ID = o.CUSTOMER_ID);
Alla typer av sammanfogningar stöds av Hive: Vänster yttre koppling, höger yttre koppling, full yttre koppling.
Tips och tricks för att använda hive-kommandon
Hive gör databehandling så enkel, enkel och utdragbar att användaren uppmärksammar mindre på att optimera Hivefrågorna. Men att uppmärksamma några saker när du skriver Hivefråga kommer säkert att få stor framgång i att hantera arbetsbelastningen och spara pengar. Nedan följer några tips om det:
- Partitioner och hinkar: Hive är ett big data-verktyg som kan fråga på stora datasätt. Att skriva frågan utan att förstå domänen kan dock ge stora partitioner i Hive.
Om användaren känner till datasatsen, kan relevanta och mycket använda kolumner grupperas i samma partition. Detta hjälper till att köra frågan snabbare och ineffektivt sätt.
I slutändan nej. av mapper- och I / O-operationer kommer också att reduceras.
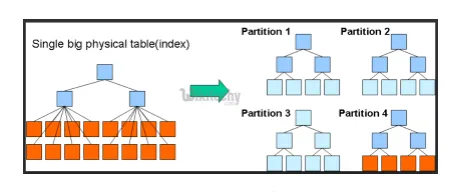
Fig 3. Partitionering
Källbilder: Google-bild
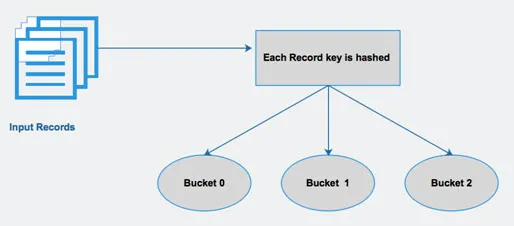
Fig 4 Bucketing
Källor bilder: - Google-bild
- Parallell exekvering: Hive kör frågan i flera steg. I vissa fall kan dessa steg bero på andra steg, varför de inte kan komma igång, när det föregående steget är avslutat. Oberoende uppgifter kan dock köras parallellt för att spara den totala körtiden. För att aktivera parallellkörningen i Hive:
ställa in hive.exec.parallel = true;
Därför kommer detta att förbättra klusteranvändningen.
- Blockera provtagning: Sampling av data från en tabell gör det möjligt att utforska frågor om data.
Trots att vi har buckat, vill vi snarare ta prov på datasätt mer slumpmässigt. Blockprover kommer med olika kraftfulla syntaxer, som hjälper till att sampla in data på olika sätt.
Provtagning kan användas för att hitta ca. info från datasatsen som det genomsnittliga avståndet mellan ursprung och destination.
Fråga 1% av big data kommer att ge nära det perfekta svaret. Utforskning blir mycket lättare och effektivare.
Slutsats - Hive-kommandon
Hive är en högre abstraktion ovanpå HDFS, som ger flexibelt frågespråk. Det hjälper till att fråga och bearbeta data på ett enklare sätt.
Hive kan klubbas med andra Big data-element för att utnyttja dess funktionalitet på ett fullständigt sätt.
Rekommenderade artiklar
Detta har varit en guide till Hive-kommandon. Här har vi diskuterat såväl grundläggande som avancerade Hive-kommandon och några omedelbara Hive-kommandon. Du kan också titta på följande artikel för att lära dig mer -
- Hiveintervjufrågor
- Hive VS nyans - Topp 6 användbara jämförelser
- Tableau-kommandon
- Adobe Photoshop-kommandon
- Använda ORDER BY-funktion i Hive
- Ladda ner och installera Hive steg för steg