
Introduktion till Python-uppsättningar
I den här artikeln kommer vi att diskutera uppsättningar i Python. Python är ett mycket mångsidigt språk och det blir snabbt ett av go-to-språken inom datavetenskapen eftersom det är lätt att förstå läsa och skriva och även baserat på OOP: s koncept. Set är en oordnad samling som representeras av lockiga parenteser i Python. Oordnad här betyder att du inte är säker i vilken ordning artiklarna kommer att visas. Uppsättningen skiljer sig från en lista att den bara kan lagra unika element och inga duplicerade element.
Syntax:
Liksom i allmänhet python är syntaxen i allmänhet lätt. Syntaxen för pytonuppsättningen är följande:
firstset = ("Johnny", "Nilanjan", "Rupa")
print(firstset)
Här är den första uppsättningen variabelnamnet som uppsättningen lagras i. De lockiga hängslen () representerar uppsättning och eftersom vi lägger till strängvärden så krävs dubbla / enstaka inverterade kommatecken. Värdena i uppsättningen separeras med komma-tecken. Nu, eftersom vi har sett syntaxen för uppsättningen med ett exempel i Python. Låt oss nu diskutera de olika metoderna som används i Python-uppsättningarna.
Olika metoder i Python-uppsättningar
Låt oss gå igenom de olika metoder som finns som inbyggd Python för uppsättningar.
1. add (): Som namnet antyder användes det för att lägga till ett nytt element i uppsättningen. Det betyder att du ökar antalet element i uppsättningen med ett. Här är en mycket viktig kunskap om uppsättning som måste hållas i åtanke att elementet bara läggs till om det inte redan finns i uppsättningen tillgångar inte tar duplicerade element. Tilläggsmetoden ger inte heller något värde. Låt oss göra ett exempel.
Koda:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.add("Sepoy")
print("The new word is", firstset)
#to check duplicate property of Set
firstset.add("Sepoy")
print("The new word is", firstset)
Nu är skärmbilden nedan utsignalen från koden när den körs på Jupyter Notebook.
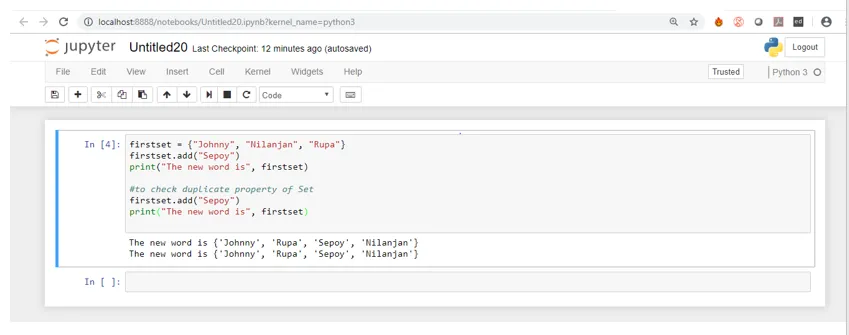
Om du ser utdata första gången, när add () -funktionen används lägger den till elementet och storleken på uppsättningen ökas med en som visas när vi kör den första utskriftssatsen men andra gången när vi använder add () -metoden för att lägga till samma element (sepoy) som första gången, när vi kör utskriftsmeddelandet ser vi samma element visas utan någon ökning av storleken på uppsättningen vilket innebär att uppsättningen inte tar några duplikatvärden.
2. clear (): Som namnet antyder tar det bort alla element från uppsättningen. Den tar varken någon parameter eller returnerar inget värde. Vi måste helt enkelt kalla den klara metoden och utföra den. Låt oss titta på ett exempel:
Koda:
firstset = ("Johnny", "Nilanjan", "Rupa")
print("Before clear", firstset)
firstset.clear()
print("After clear", firstset)
Låt oss titta på utgången efter att ha utfört samma kod i jupyter Notebook.
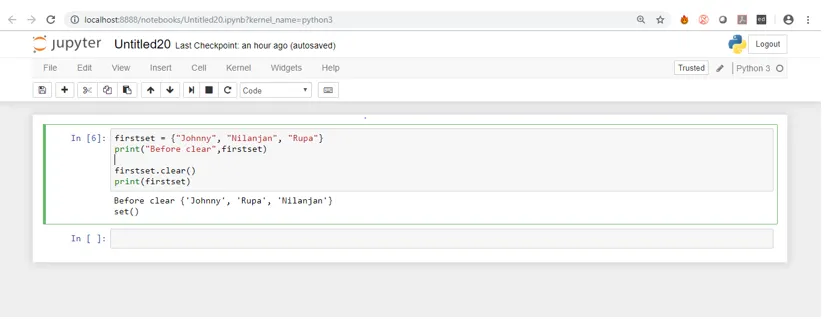
Så, ovanstående skärmdump visar att innan vi körde den klara metoden listan trycktes med element och sedan när vi körde metoden clear () har alla element tagits bort och vi har en tom uppsättning.
3. kopia (): Den här metoden används för att skapa en ytlig kopia av en uppsättning. Termen grunt kopierar betyder att om du lägger till nya element i uppsättningen eller tar bort element från uppsättningen ändras inte originaluppsättningen. Det är den grundläggande fördelen med att använda kopieringsfunktionen. Vi kommer att se ett exempel för att förstå det grunt kopierade konceptet.
Koda:
originalset = ("Johnny", "Nilanjan", "Rupa")
copiedset = originalset.copy()
print("originalset:: ", originalset)
print("copiedset:: ", copiedset)
# modify the copiedset to check shallow copy feature
copiedset.add("Rocky")
print("originalset:: ", originalset)
print("copiedset:: ", copiedset)
Låt oss nu kontrollera utgången i Jupyter Notebook.
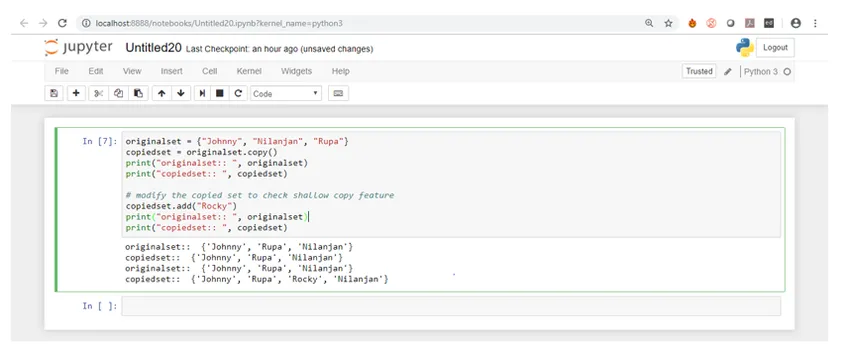
Som ni ser att när vi brukade lägga till funktion för att lägga till ett nytt element i den kopierade uppsättningen, ändrades den kopierade uppsättningen men den ursprungliga uppsättningen förblev fortfarande densamma.
4. skillnad (): Det här är en mycket viktig funktion. Denna funktion returnerar en uppsättning som är skillnaden mellan två uppsättningar. Tänk på att skillnad här inte betyder subtraktion eftersom det här är skillnaden mellan antalet element i två uppsättningar och inte värdena på element. Här betyder exempelvis uppsättning A1 - uppsättning A2 att den returnerar en uppsättning med element som finns i A1 men inte i A2 och vice versa för uppsättning A2 - uppsättning A1 (närvarande i A2 men inte i A1). Detsamma förklaras nedan med hjälp av ett exempel.
Koda:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
print(A1.difference(A2))
print(A2.difference(A1))
Låt oss nu titta på utgången i skärmdumpen nedan.
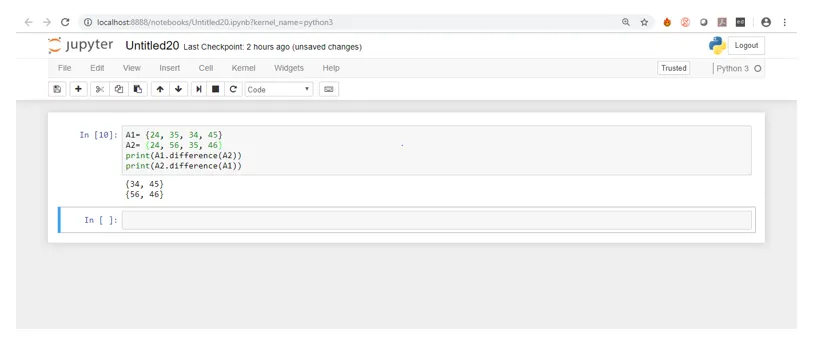
I ovanstående skärmdump, om du tittar noggrant, är det en skillnad mellan det första och det andra resultatet. I det första resultatet visas elementen som finns i A men inte i B, medan det i det andra resultatet visas element som finns i B men inte i A.
5. korsning (): Det skiljer sig mycket från den tidigare inbyggda metoden. I detta fall returneras endast elementen som är vanliga i både uppsättningarna eller i flera uppsättningar (i fallet med mer än två uppsättningar) i form av en uppsättning. Låt oss nu gå igenom ett exempel.
Koda:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
A3= (24, 35, 47, 56)
print(A1.intersection(A2, A3))
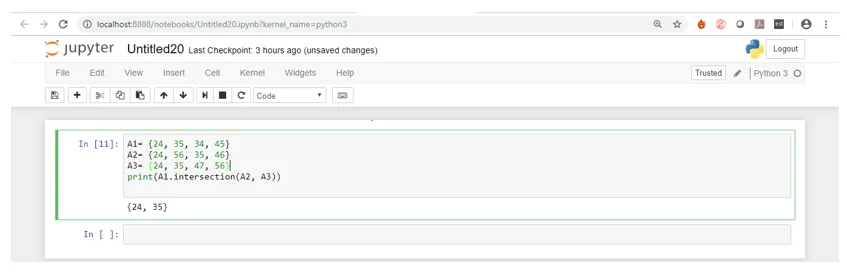
Som ni kan se att de tre uppsättningarna bara hade två gemensamma element som är 24 och 35. Därför returnerade den en uppsättning som bara innehöll 24 och 35 vid körning av koden.
6. union (): Det är en funktion som returnerar en uppsättning med alla element i den ursprungliga uppsättningen och även de angivna uppsättningarna. Eftersom den returnerar en uppsättning så kommer alla objekt bara att ha ett utseende. Om två uppsättningar innehåller samma värde visas objektet bara en gång.
Koda:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
A3= (24, 35, 47, 56)
print(A1.union(A2, A3))
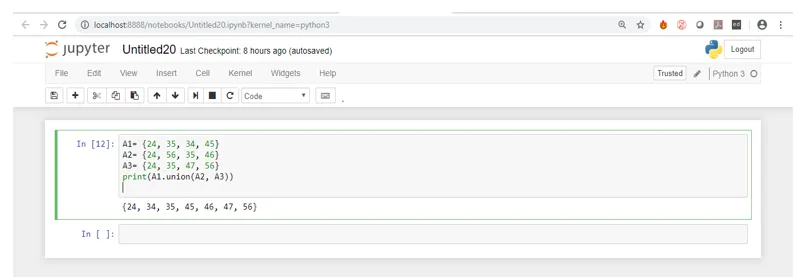
I skärmdumpen ovan kan du se utgången från koden vid körning. Om du tittar noga hittar du alla värden från A1 och alla unika värden från de andra två uppsättningarna.
7. issubset (): Denna funktion returnerar booleska värden som är sanna eller falska. Om alla element i en uppsättning finns i en annan uppsättning returnerar det sant annars falskt. Vi kommer att se ett exempel på samma för att förstå bättre.
Koda:
A1 =(3, 6, 8)
A2 =(45, 87, 3, 67, 6, 8)
print(A1.issubset(A2))
print(A2.issubset(A1))
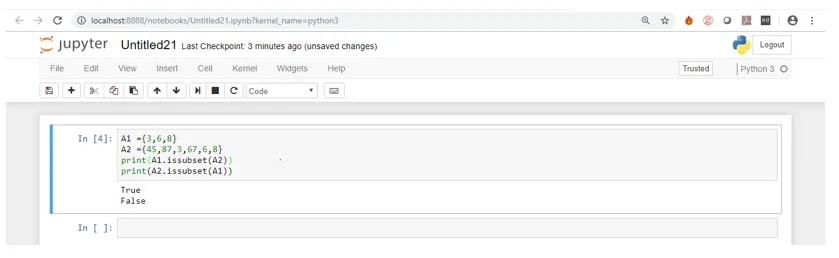
Om du ser ovanstående skärmdump för utdata kan du se att A2 har alla elementen i A1 men A1 inte har alla elementen i A2. Följaktligen är A1 en delmängd av A2.
8. issuperset (): Denna funktion returnerar booleska värden som är sanna eller falska. Om en uppsättning innehåller alla element i en annan uppsättning kan den uppsättningen kallas en superset för den andra uppsättningen och värdet som returneras av funktionen är sant annars är falskt. Vi kommer att se ett exempel på samma för att förstå bättre.
Koda:
A1 = (3, 6, 8)
A2 = (45, 87, 3, 67, 6, 8)
print(A1.issuperset(A2))
print(A2.issuperset(A1))
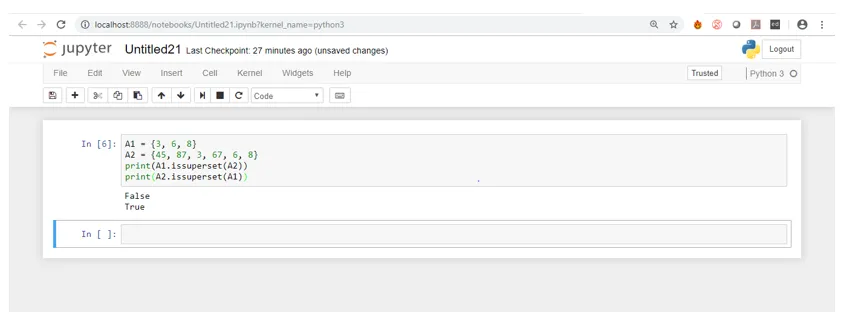
Som du kan se från utgångsskärmbilden att den andra uppsättningen A2 innehåller alla element i uppsättningen A1. Därför är det en superset av A1. Detsamma är inte sant för A1 med avseende på A2, därför returnerar det falskt.
9. ta bort (): Den här funktionen används för att ta bort element från uppsättningen. Elementen som ska tas bort skickas som argument. Funktionen tar bort elementet om det finns i uppsättningen, annars returnerar det ett fel. Vi kommer att utföra ett exempel för att kontrollera detta.
Koda:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.remove("Nilanjan")
print(firstset)
# to check error
firstset.remove("Rocky")
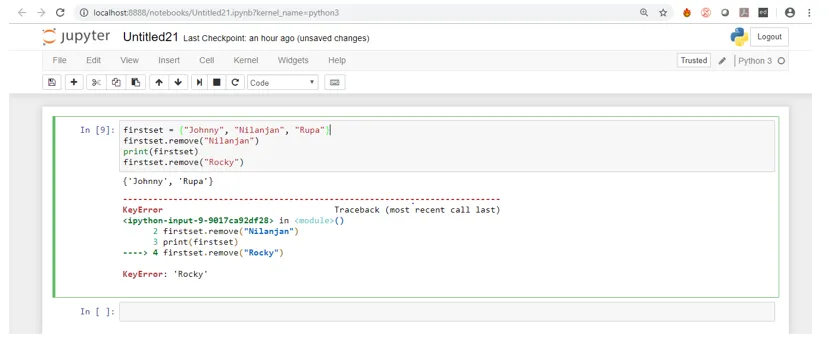
Om du ser skärmdumpen ovan när koden körs tar den bort elementet "Nilanjan" som det fanns i uppsättningen men när vi försöker ta bort "Rocky" ger det oss ett fel eftersom "Rocky" inte finns i uppsättningen.
10. kassera (): Den här inbyggda metoden används också för att ta bort element från uppsättningen men den skiljer sig från borttagningsmetoden som vi diskuterade tidigare. Om elementet finns i uppsättningen tar det bort elementet men om det är närvarande returnerar det inget fel och skriver normalt bara uppsättningen. Vi kommer att se ett exempel på detta
Koda:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.discard("Nilanjan")
print(firstset)
firstset.discard("Rocky")
print(firstset)
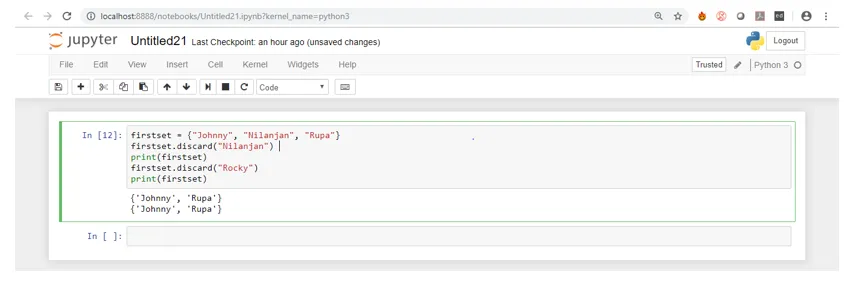
Om vi ser ovanstående skärmdump så kan vi se att även om "Rocky" inte finns i uppsättningen ser vi inget fel visas till skillnad från om metoden tas bort där ett fel visades.
Slutsats
Vi har diskuterat i denna artikel begreppet set i python och de olika funktionerna som kan användas eller tillämpas i set. Som diskuterade är uppsättningar viktiga i python och de inbyggda metoderna används för att manipulera uppsättningarna och även för att utföra operationer med uppsättningar.
Rekommenderade artiklar
Detta är en guide till Python-uppsättningarna. Här diskuterar vi introduktionen av Python-uppsättningarna, olika metoder i Python-uppsättningar tillsammans med Syntax. Du kan också gå igenom våra andra artiklar som föreslås för att lära dig mer–
- String Array i Python
- Vad är Python
- NLP i Python
- Är Python ett skriptspråk?
- Python-funktioner
- String Array i JavaScript
- Komplett guide till strängarray i C