
Vad är SVM-algoritm?
SVM står för Support Vector Machine. SVM är en övervakad maskininlärningsalgoritm som ofta används för klassificerings- och regressionsutmaningar. Vanliga tillämpningar av SVM-algoritmen är Intrusion Detection System, Handwriting Recognition, Protein Structure Prediction, Detecting Steganography in digital images, etc.
I SVM-algoritmen representeras varje punkt som en datapost i det n-dimensionella utrymmet där värdet på varje funktion är värdet på en specifik koordinat.
Efter planering har klassificering utförts genom att hitta hype-plan som differentierar två klasser. Se bilden nedan för att förstå detta koncept.
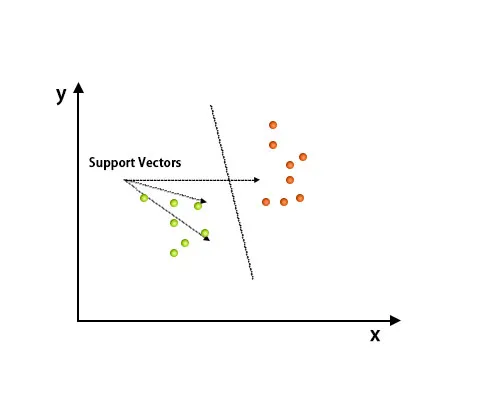
Support Vector Machine-algoritmen används främst för att lösa klassificeringsproblem. Stödvektorer är inget annat än koordinaterna för varje datapost. Support Vector Machine är en gräns som differentierar två klasser med hyperplan.
Hur fungerar SVM-algoritmen?
I ovanstående avsnitt har vi diskuterat differentieringen av två klasser med hyperplan. Nu ska vi se hur denna SVM-algoritm faktiskt fungerar.
Scenario 1: Identifiera rätt hyperplan
Här har vi tagit tre hyperplan, dvs. A, B och C. Nu måste vi identifiera rätt hyperplan för att klassificera stjärna och cirkel.
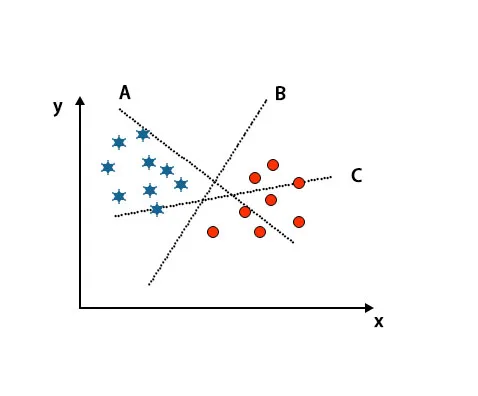
För att identifiera rätt hyperplan bör vi känna tumregeln. Välj hyperplan som skiljer två klasser. I ovanstående bild differentierar hyperplan B två klasser mycket bra.
Scenario 2: Identifiera rätt hyperplan
Här har vi tagit tre hyperplan, dvs A, B och C. Dessa tre hyperplan planerar redan klasser mycket bra.
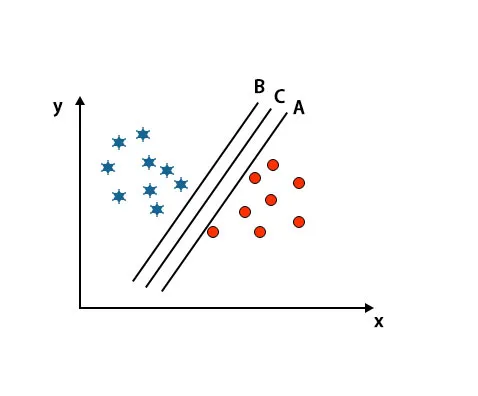
I detta scenario ökar vi avståndet mellan de närmaste datapunkterna för att identifiera rätt hyperplan. Detta avstånd är inget annat än en marginal. Se bild nedan.
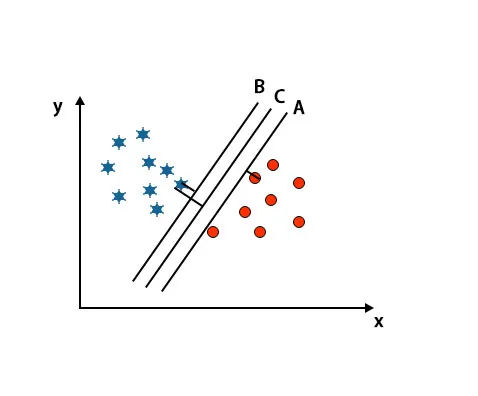
I ovanstående bild är marginalen för hyperplan C högre än hyperplan A och hyperplan B. Så i detta scenario är C rätt hyperplan. Om vi väljer hyperplanet med en lägsta marginal kan det leda till felklassificering. Därför valde vi hyperplan C med maximal marginal på grund av robusthet.
Scenario 3: Identifiera rätt hyperplan
Obs: För att identifiera hyperplanet följer du samma regler som nämnts i de föregående avsnitten.
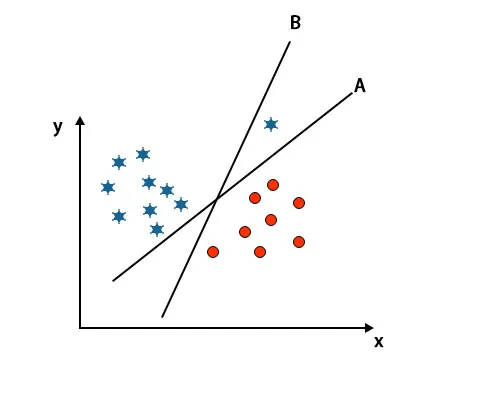
Som du kan se i ovanstående bild är marginalen för hyperplan B högre än marginalen för hyperplan A, det är därför som vissa kommer att välja hyperplan B som höger. Men i SVM-algoritmen väljer den det hyperplanet som klassificerar klasser exakt före maximeringsmarginalen. I detta scenario har hyperplan A klassificerat allt noggrant och det finns ett visst fel med klassificeringen Av hyperplan B. Därför är A rätt hyperplan.
Scenario 4: Klassificera två klasser
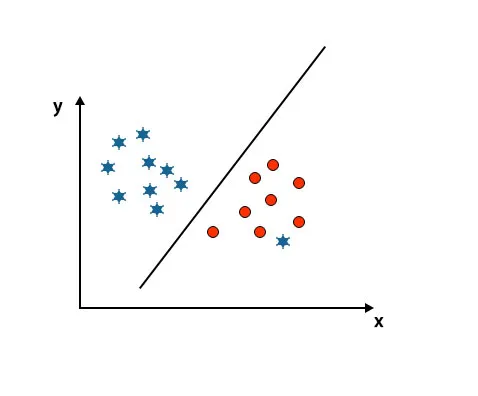
Som ni kan se i bilden nedan kan vi inte skilja två klasser med en rak linje eftersom en stjärna ligger som en outlier i den andra cirkelklassen.
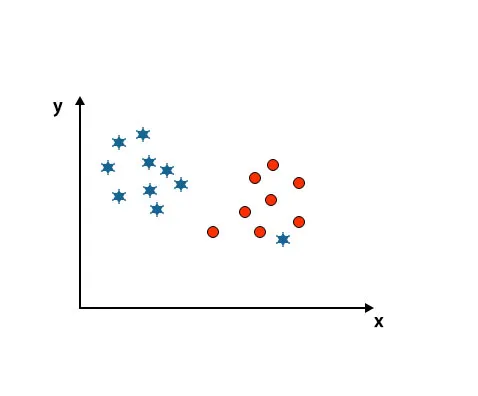
Här är en stjärna i en annan klass. För stjärnsklassen är den här stjärnan den högre. På grund av SVM-algoritmens robusthetsegenskap hittar den rätt hyperplan med högre marginal som ignorerar en utligare.
Scenario 5: Fin hyperplan för att differentiera klasser
Hittills har vi sett linjära hyperplan. I bilden nedan har vi inte linjärt hyperplan mellan klasser.
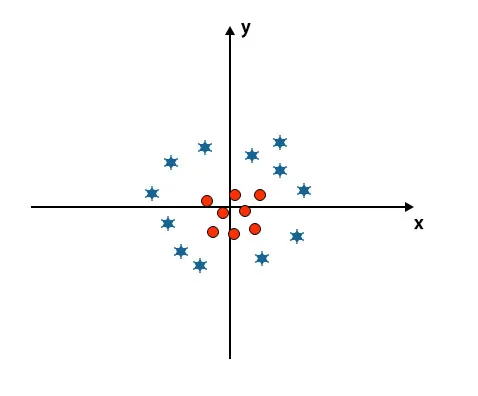
För att klassificera dessa klasser introducerar SVM några ytterligare funktioner. I det här scenariot kommer vi att använda den nya funktionen z = x 2 + y 2.
Plottar alla datapunkter på x- och z-axeln.

Notera
- Alla värden på z-axeln bör vara positiva eftersom z är lika med summan av x-kvadrat och y-kvadrat.
- I ovan nämnda plott är röda cirklar stängda för ursprunget till x-axeln och y-axeln, vilket leder värdet av z till lägre och stjärnan är exakt motsatsen till cirkeln, det är borta från ursprunget till x-axeln och y-axeln, vilket leder värdet på z till högt.
I SVM-algoritmen är det lätt att klassificera med linjärt hyperplan mellan två klasser. Men frågan uppstår är om vi ska lägga till denna funktion i SVM för att identifiera hyperplan. Så svaret är nej, för att lösa detta problem har SVM en teknik som är allmänt känd som ett kärntrick.
Kärntrick är funktionen som omvandlar data till en lämplig form. Det finns olika typer av kärnfunktioner som används i SVM-algoritmen, dvs. Polynomial, linjär, icke-linjär, Radial Base-funktion, etc. Här konverteras lågdimensionellt inmatningsutrymme till ett högdimensionellt utrymme med hjälp av kärntrick.
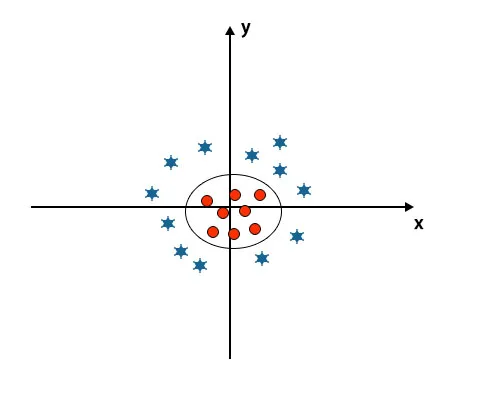
När vi tittar på hyperplanet ursprunget till axeln och y-axeln ser det ut som en cirkel. Se bild nedan.
Fördelar med SVM-algoritm
- Även om inmatningsdata är icke-linjära och icke-separerbara, genererar SVM: er exakta klassificeringsresultat på grund av dess robusthet.
- I beslutsfunktionen använder den en delmängd av träningspunkter som kallas supportvektorer, varför den är minneseffektiv.
- Det är användbart att lösa alla komplexa problem med en lämplig kärnfunktion.
- I praktiken generaliseras SVM-modeller med mindre risk för överanpassning i SVM.
- SVM: er fungerar bra för textklassificering och när man hittar den bästa linjära separatorn.
Nackdelar med SVM-algoritm
- Det tar lång träningstid när man arbetar med stora datasätt.
- Det är svårt att förstå den slutliga modellen och individuella effekter.
Slutsats
Det har guidats till Support Vector Machine Algoritm, som är en maskininlärningsalgoritm. I den här artikeln diskuterade vi vad som är SVM-algoritmen, hur det fungerar och det är fördelarna i detalj.
Rekommenderade artiklar
Detta har varit en guide till SVM-algoritm. Här diskuterar vi dess arbete med ett scenario, fördelar och nackdelar med SVM-algoritm. Du kan också titta på följande artiklar för att lära dig mer -
- Data Mining Algoritms
- Teknik för gruvdrift
- Vad är maskininlärning?
- Maskininlärningsverktyg
- Exempel på C ++ -algoritm