

Skillnaden mellan Apache Nifi och Apache Spark
Fram till en lång tid, när det fanns ett tungt arbete som behövde slutföras, förlitade folk sig på hästar för att dra tunga belastningar, upprätthålla hastigheten eller något annat däremellan. Men inte alla hästar passade för varje uppgift. Samma är fallet med tekniken idag. När nya teknologier kommer in varje dag blir det oerhört viktigt att känna till deras verkliga applikationer. Två sådana tekniker är Apache Nifi och Apache Spark och vi ska studera om dem i det här inlägget.
Apache Spark är ett klusterberäknande open source-ramverk som syftar till att tillhandahålla ett gränssnitt för att programmera hela uppsättningen av kluster med implicit feltolerans och dataparallellism. Den använder RDD: er (Resilient Distribuerade databaser) och bearbetar data i form av Diskretiserade strömmar som vidare används för analytiska ändamål.
Apache Nifi (som är den korta formen av NiagaraFiles) är ett annat program som syftar till att automatisera dataflödet mellan mjukvarusystem. Designen är baserad på flödesbaserad programmeringsmodell som tillhandahåller funktioner som inkluderar drift med klusterförmåga. Det är ett lättanvänt, pålitligt och ett kraftfullt system för att bearbeta och distribuera data. Det stöder skalbara riktade grafer för datarutning, systemmedling och logik för transformation. Låt oss diskutera jämförelserna mellan båda ämnena.
Head to head jämförelse mellan Apache Nifi vs Apache Spark (Infographics)
Nedan visas de 9 bästa jämförelserna mellan Apache Nifi vs Apache Spark
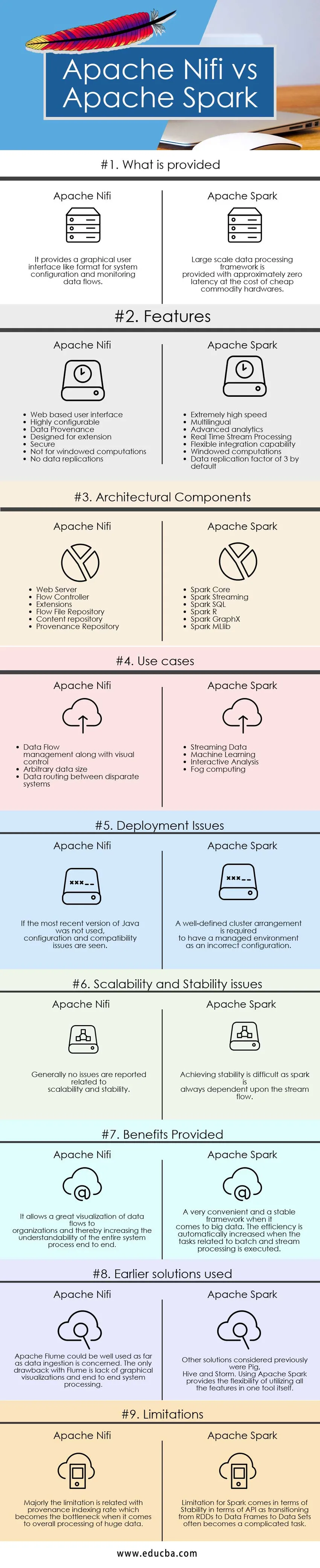
Viktiga skillnader mellan Apache Nifi vs Apache Spark
Skillnaderna mellan Apache Nifi och Apache Spark förklaras i punkterna som presenteras nedan:
- Apache Nifi är ett dataintagningsverktyg som används för att leverera ett lättanvänt, kraftfullt och ett pålitligt system så att bearbetning och distribution av data över resurser blir lätt medan Apache Spark är en extremt snabb klusterberäkningsteknik som är utformad för snabbare beräkning av effektivt utnyttja interaktiva frågor, i minneshantering och strömbehandlingsfunktioner.
- Apache Nifi fungerar i fristående läge och ett klusterläge medan Apache Spark fungerar bra i lokalt eller fristående läge, Mesos, Garn och andra typer av big data-klusterlägen.
- Funktioner i Apache Nifi inkluderar garanterad leverans av data, effektiv databuffring, Prioriterad kö, Flow Specific QoS, Data Provenance, Roll buffertåterställning, Visuellt kommando och kontroll, Flödesmallar, Säkerhet, Parallell Streaming-funktioner medan funktioner i Apache-gnist inkluderar blixt snabbt snabbbearbetningsmöjlighet, flerspråkig, datorminne, effektivt utnyttjande av hårdvarusystem för varor, avancerad analys, effektiv integrationsförmåga.
- Apache Nifi ger en bättre läsbarhet och övergripande förståelse för systemet genom att tillhandahålla visualiseringsfunktioner och dra och släpp-funktioner. Dataflödet kan enkelt hanteras och regleras med hjälp av konventionella tekniker och processer medan i fallet med Apache Spark för att se dessa typer av visualiseringar behövs ett klusterhanteringssystem som Ambari. Apache Spark ger i sig inte visualiseringsfunktioner och är bara bra när det gäller programmering. Det är överlägset ett mycket bekvämt och stabilt system för behandling av enorma mängder data.
- Begränsningen med Apache Nifi är relaterad till vad som är dess fördel. Den enda drag-and-drop-funktionen ger en begränsning av att inte kunna skala och ge robusthet när det gäller att integrera den med andra komponenter och verktyg medan i fallet med Apache Spark kommer den primära begränsningen tillsammans med användning av omfattande varuhårdvara och hantera dem blir ibland en tråkig uppgift. Den andra rapporterade begränsningen kommer tillsammans med sina strömmningsfunktioner relaterade till Diskretiserad ström och Windowed eller batch-ström där transformeringen av RDD till dataram och datasatser ger en orsak till instabilitet ibland.
Apache Nifi vs Apache Spark Comparision Table
| Grund för jämförelse | Apache Nifi | Apache Spark |
| Vad tillhandahålls | Det ger ett grafiskt användargränssnitt som ett format för systemkonfiguration och övervakning av dataflöden. | Storskalig databehandlingsram är försedd med ungefär noll latens till bekostnad av billig varuhårdvara. |
| Funktioner |
|
|
| Arkitektoniska komponenter |
|
|
| Använd fall |
|
|
| Problem med driftsättning | Om den senaste versionen av Java inte användes visas problem med konfigurering och kompatibilitet | Ett väldefinierat klusterarrangemang krävs för att ha en hanterad miljö som en felaktig konfiguration |
| Skalbarhets- och stabilitetsfrågor | Generellt rapporteras inga problem relaterade till skalbarhet och stabilitet | Att uppnå stabilitet är svårt eftersom en gnista alltid beror på strömningsflödet. |
| Fördelar | Det möjliggör en stor visualisering av dataflöden till organisationer och därigenom ökar förståelsen för hela systemprocessen från slut till slut | En mycket bekväm och stabil ram när det gäller big data. Effektiviteten ökas automatiskt när uppgifterna relaterade till batch- och strömbearbetning utförs. |
| Tidigare lösningar | Apache Flume kan användas väl när det gäller intag av data. Den enda nackdelen med Flume är bristen på grafiska visualiseringar och systembehandling i slutändan | Andra lösningar som beaktats tidigare var Pig, Hive och Storm. Att använda Apache Spark ger flexibiliteten att använda alla funktioner i ett verktyg i sig själv. |
| begränsningar | I huvudsak är begränsningen relaterad till ursprungsindexgraden som blir flaskhalsen när det gäller övergripande behandling av enorma data | Begränsning för gnista kommer i form av stabilitet när det gäller API eftersom övergången från RDD till dataramar till datasätt ofta blir en komplicerad uppgift. |
Slutsats - Apache Nifi vs Apache Spark
För att avsluta inlägget kan man säga att Apache Spark är en tung krigshäst medan Apache Nifi är en kvikk rashäst. Båda har sina egna fördelar och begränsningar som ska användas inom sina respektive områden. Du måste bestämma rätt verktyg för ditt företag. Håll dig uppdaterad på vår blogg för fler artiklar relaterade till nyare teknik för big data.
Rekommenderad artikel
Detta har varit en guide till Apache Nifi vs Apache Spark, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Apache Hadoop vs Apache Spark | Topp 10 jämförelser du måste känna till!
- Apache Storm vs Apache Spark - Lär dig 15 användbara skillnader
- 7 viktiga saker om Apache Spark (guide)
- De 15 bästa sakerna du behöver veta om MapReduce vs Spark