
Skillnaden mellan BFS VS DFS
Breadth-First Search (BFS) och Deepth First Search (DFS) är två viktiga algoritmer som används för att söka. Breadth-First Search startar sin sökning från den första noden och rör sig sedan över nivåerna som är närmare rotnoden medan Djup First Search-algoritmen börjar med den första noden och sedan slutför sin sökväg till slutnoden på respektive sökväg. Båda algoritmerna går igenom varje nod under sökningen. Olika koder skrivs för de två algoritmerna för att utföra processen att korsa. De betraktas också som viktiga sökalgoritmer inom Artificial Intelligence.
I det här ämnet kommer vi att lära oss om BFS VS DFS.
Hur fungerar BFS och DFS?
Arbetsmekanismen för båda algoritmerna förklaras nedan med exempel. Se dem för en bättre förståelse av den använda metoden.
Exempel på bredd-första sökning
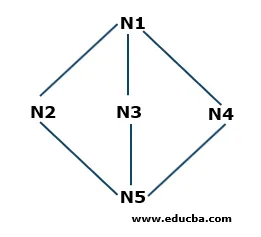
- Steg 1: N1 är rotnoden, så det kommer att börja härifrån. N1 är ansluten till tre noder N2, N3 och N4. Alla tre noderna har inte besökt än. Så vi börjar från N2 och lagrar den i kön. Så kön med namnet Q innehåller bara N2.
F: N2
- Steg 2: Därefter är noden som är ansluten till N1 N3. Eftersom vi gick över eller besökte noden lagrar vi den i kön. Så den uppdaterade kön är
F: N3, N2
- Steg 3: Därefter är noden som är ansluten till rotnoden N4. Vi lagrar det i kön.
F: N4, N3, N2
- Steg 4: Alla noder som är anslutna till N1 lagras i kön. Nu tar vi bort N2 från kön enligt First in First Out-principen (FIFO) och hittar noderna som är anslutna till N2 dvs. N5. N5 besöks inte en gång, så vi lagrar den i kön.
F: N5, N4, N3
- Steg 5: Alla vertikaler besöks, så vi fortsätter att ta bort noderna från kön tills de är tomma.
Exempel på djup Första sökning
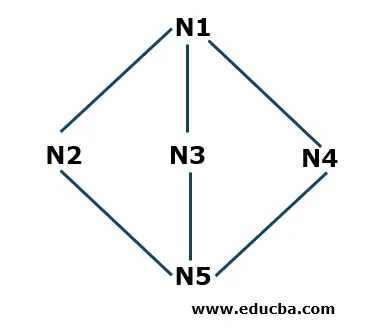
- Steg 1: Vi börjar med N1 som startnod och lagrar den i en stack S. N1 är ansluten till tre angränsande noder N2, N3 och N4. Börjar med N2 (du kan börja alfabetiskt eller numeriskt), sätter vi detta i bunten.
S: N2 (överst), N1
- Steg 2: Nu är de närliggande noderna N2 N1 och N5. Eftersom N1 redan finns i bunten betyder det att den besöks, så vi tar N5 och lägger den i bunten S.
S: N5 (överst), N2, N1
- Steg 3: Nu är de närliggande noderna för N5 N3 och N4. Vi startar N3 och lägger den i bunten.
S: N3 (överst), N5, N2, N1
Nu är N3 ansluten till N5 och N1 som redan finns i bunten vilket innebär att de är besökta, så vi tar bort N3 från bunten enligt Last in First Out-principen (LIFO) -principen.
S: N5 (överst), N2, N1
- Steg 4: Nu lägger vi den sista noden som vi inte stötte på i hela korsningen i N4 och lägger den i bunten.
S: N4 (överst), N5, N2, N1
- Steg 5: Nu lämnas vi inte kvar med några andra noder, så vi kontrollerar i bunten om det finns några noder anslutna till respektive noder i den som inte besöks. Om alla anslutna noder besöks tar vi bort de noder som finns i bunten. Till exempel har N4 inga anslutningsnoder som vi inte har kontrollerat så vi tar bort den från stacken. På liknande sätt kan vi leta efter andra noder. Algoritmen stannar när stacken är tom.
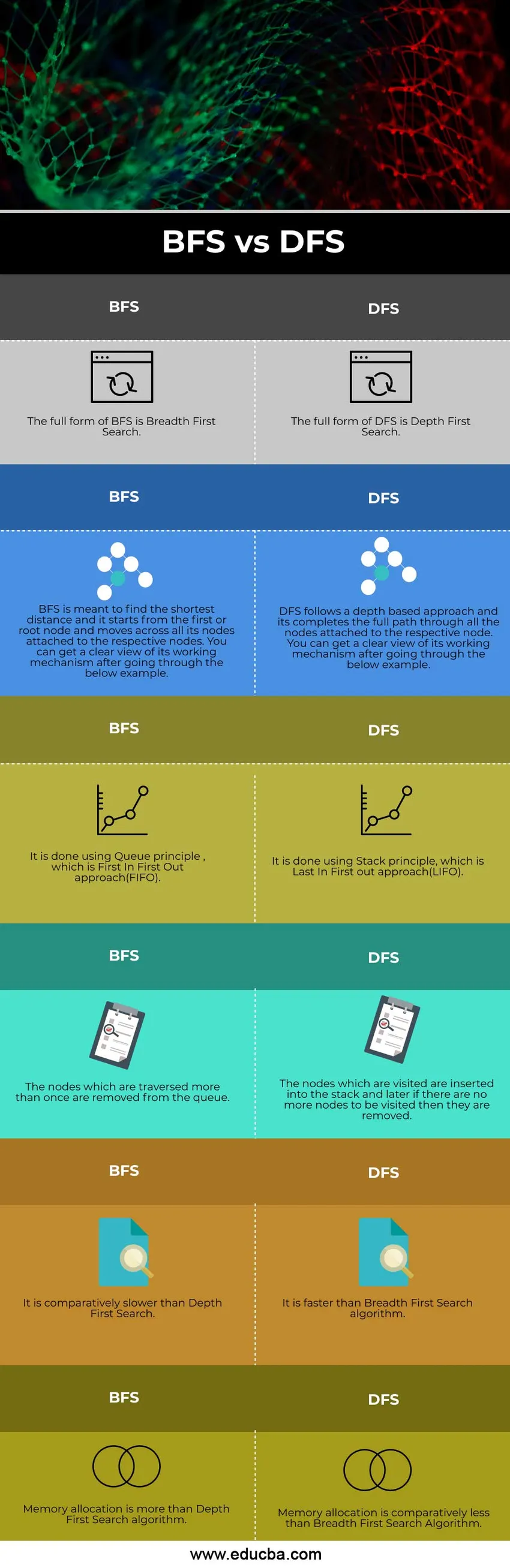
Jämförelse mellan huvud och huvud mellan BFS VS DFS (Infographics)
Nedan visas de 6 främsta skillnaderna mellan BFS VS DFS
Viktiga skillnader mellan BFS och DFS
Låt oss diskutera några av de viktigaste viktiga skillnaderna mellan BFS och DFS
- Breadth-First Search (BFS) startar från rotnoden och besöker alla respektive noder som är kopplade till den medan DFS startar från rotnoden och slutför den fulla sökvägen som är kopplad till noden.
- BFS följer tillvägagångssättet i kö medan DFS följer tillvägagångssättet från Stack.
- Metoden som används i BFS är optimal medan processen som används i DFS inte är optimal.
- Om vårt mål är att hitta den kortaste vägen än BFS föredras framför DFS.
BFS- och DFS-jämförelsetabell
Låt oss diskutera den bästa jämförelsen mellan BFS vs DFS
| BFS | DFS |
| Den fullständiga formen av BFS är Breadth-First Search. | Den fullständiga formen av DFS är Depth First Search |
| BFS är tänkt att hitta det kortaste avståndet och det börjar från den första eller rotnoden och rör sig över alla sina noder kopplade till respektive noder. Du kan få en klar bild av dess arbetsmekanism efter att ha gått igenom exemplet nedan. | DFS följer ett djupbaserat tillvägagångssätt och det fullbordar hela vägen genom alla noder som är kopplade till respektive nod. Du kan få en klar bild av dess arbetsmekanism efter att ha gått igenom exemplet nedan. |
| Det görs med hjälp av Queue-principen, som är First In First Out-metoden (FIFO). | Det görs med hjälp av Stack-principen, som är Last In First out-metoden (LIFO). |
| De noder som korsas mer än en gång tas bort från kön. | De noder som besöks sätts in i bunten och senare om det inte finns fler noder att besöka tas de bort. |
| Det är relativt långsammare än Depth First Search. | Det är snabbare än Breadth-First Search-algoritmen. |
| Tilldelning av minne är mer än algoritmen för Deepth First Search. | Tilldelning av minne är jämförelsevis mindre än algoritmen för bredd-första sökningen |
Slutsats
Det finns många applikationer där ovanstående algoritmer används som maskininlärning eller för att hitta lösningar relaterade till artificiell intelligens etc. De används främst i diagram för att hitta om det är tvåparti eller inte, för att upptäcka cykler eller komponenter som är anslutna. De betraktas också som viktiga algoritmer för att hitta vägen eller för att hitta det kortaste avståndet. Beroende på verksamhetens krav kan vi använda två algoritmer. Emellertid anses Breadth-First Search vara ett optimalt sätt snarare än Djup First Search-algoritmen.
Rekommenderade artiklar
Detta är en guide till BFS VS DFS. Här diskuterar vi BFS VS DFS viktiga skillnader med infografik och jämförelsetabell. Du kan också titta på följande artiklar för att lära dig mer -
- BFS-algoritm
- TeraData vs Oracle
- Big Data vs Data Warehouse
- Big Data vs Apache Hadoop: Topp 4 jämförelse du måste lära dig