
Översikt över neurala nätverksalgoritmer
- Låt oss först veta vad betyder ett neuralt nätverk? Neurala nätverk är inspirerade av de biologiska nervnäten i hjärnan eller vi kan säga nervsystemet. Det har skapat mycket spänning och forskning pågår fortfarande i denna delmaskin Machine Learning i industrin.
- Den grundläggande beräkningsenheten i ett neuralt nätverk är en neuron eller nod. Den tar emot värden från andra nervceller och beräknar utgången. Varje nod / neuron är associerad med vikt (w). Denna vikt ges enligt den relativa vikten av den specifika neuron eller nod.
- Så om vi tar f som nodfunktion, kommer nodfunktionen f att ge utmatning som visas nedan: -
Utgången från neuron (Y) = f (w1.X1 + w2.X2 + b)
- Där w1 och w2 är vikt, är X1 och X2 numeriska ingångar medan b är förspänningen.
- Ovanstående funktion f är en icke-linjär funktion, även kallad aktiveringsfunktion. Dess grundläggande syfte är att införa icke-linearitet eftersom nästan all verklig data är icke-linjär och vi vill att neuroner ska lära sig dessa representationer.
Olika neurala nätverksalgoritmer
Låt oss nu undersöka fyra olika neurala nätverksalgoritmer.
1. Gradient Descent
Det är en av de mest populära optimeringsalgoritmerna inom maskininlärning. Det används vid utbildning av en maskininlärningsmodell. Med enkla ord används det i grund och botten för att hitta värden på koefficienterna som helt enkelt minskar kostnadsfunktionen så mycket som möjligt. Först börjar vi med att definiera några parametervärden och sedan med hjälp av kalkylen börjar vi iterativt justera värdena så att den förlorade funktionen reduceras.
Låt oss nu komma till den del som är lutning ?. Så, en lutning betyder mycket att utgången från valfri funktion kommer att förändras om vi minskar ingången med lite eller med andra ord kan vi kalla den till sluttningen. Om lutningen är brant kommer modellen att lära sig snabbare på samma sätt som en modell slutar lära sig när lutningen är noll. Detta beror på att det är en minimeringsalgoritm som minimerar en given algoritm.
Under formeln för att hitta nästa position visas i fallet med lutningens nedstigning.
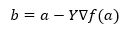
Där b är nästa position
a är aktuell position, gamma är en väntande funktion.
Så, som du kan se är gradient nedstigning en väldigt bra teknik men det finns många områden där gradient nedstigning inte fungerar korrekt. Nedan finns några av dem:
- Om algoritmen inte körs korrekt kan vi stöta på något som problemet med att försvinna gradient. Dessa inträffar när lutningen är för liten eller för stor.
- Problem uppstår när datainriktning utgör ett icke-konvex optimeringsproblem. Gradient anständigt fungerar endast med problem som är det konvex optimerade problemet.
- En av de mycket viktiga faktorerna att leta efter när du använder denna algoritm är resurser. Om vi har mindre minne tilldelat för applikationen bör vi undvika gradientavstigningsalgoritm.
2. Newtons metod
Det är en andra ordning optimeringsalgoritm. Det kallas en andra ordning eftersom den använder den hessiska matrisen. Så, den hessiska matrisen är inget annat än en kvadratisk matris av andra ordningens partiella derivat av en skalad värderad funktion. I Newtons metodoptimeringsalgoritm, tillämpas det första derivatet av en dubbel differentierbar funktion f så att den kan hitta rötterna / stationära punkter. Låt oss nu gå in i stegen som krävs av Newtons metod för optimering.
Den utvärderar först förlustindexet. Den kontrollerar sedan om stoppkriterierna är sanna eller falska. Om det är falskt beräknar det sedan Newtons träningsriktning och träningsfrekvensen och förbättrar sedan parametrarna eller vikterna för nervcellen och återigen fortsätter samma cykel. Så kan du nu säga att det tar färre steg jämfört med lutningens nedstigning för att få minsta möjliga värdet på funktionen. Även om det tar färre steg jämfört med gradientavstigningsalgoritmen används den fortfarande inte i stor utsträckning eftersom den exakta beräkningen av hessian och dess omvända är beräkningsmässigt mycket dyra.
3. Konjugerad lutning
Det är en metod som kan betraktas som något mellan gradientstigning och Newtons metod. Huvudskillnaden är att det påskyndar den långsamma konvergens som vi i allmänhet förknippar med lutningens nedstigning. Ett annat viktigt faktum är att det kan användas för såväl linjära som icke-linjära system och det är en iterativ algoritm.
Det utvecklades av Magnus Hestenes och Eduard Stiefel. Som redan nämnts ovan att den producerar snabbare konvergens än gradientavstamning, Anledningen till att den kan göra det är att i konjugatgradientalgoritmen görs sökningen tillsammans med konjugatinstruktionerna, varför den konvergerar snabbare än gradientavstigningsalgoritmer. En viktig punkt att notera är att y kallas konjugatparametern.
Träningsriktningen återställs periodiskt till lutningens negativa. Denna metod är mer effektiv än gradientavstigning vid utbildning av nervnätverket eftersom den inte kräver den Hessiska matrisen som ökar beräkningsbelastningen och den konvergerar också snabbare än gradientnedstigningen. Det är lämpligt att använda i stora neurala nätverk.
4. Quasi-Newton-metoden
Det är ett alternativt tillvägagångssätt till Newtons metod, eftersom vi nu är medvetna om att Newtons metod är beräkningsmässigt dyr. Denna metod löser dessa nackdelar i en sådan grad att istället för att beräkna den Hessian-matrisen och sedan beräkna det inversa direkt, bygger denna metod upp en ungefärlighet för att inversera Hessian vid varje iteration av denna algoritm.
Nu beräknas denna approximation med hjälp av informationen från det första derivatet av förlustfunktionen. Så vi kan säga att det förmodligen är den bäst lämpade metoden att hantera stora nätverk eftersom det sparar beräkningstid och också att det är mycket snabbare än gradientstigning eller konjugerad gradientmetod.
Slutsats
Innan vi slutar den här artikeln, låt oss jämföra beräkningshastigheten och minnet för de ovannämnda algoritmerna. Enligt minneskrav kräver gradientnedstigning det minsta minnet och det är också det långsammaste. I motsats till att Newtons metod kräver mer beräkningskraft. Så med beaktande av alla dessa är Quasi-Newton-metoden bäst lämpad.
Rekommenderade artiklar
Detta har varit en guide till neurala nätverksalgoritmer. Här diskuterar vi också översikten över Neural Network Algoritm tillsammans med fyra olika algoritmer. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Machine Learning vs Neural Network
- Maskininlärningsramar
- Neurala nätverk vs djup inlärning
- K- betyder klusteralgoritm
- Guide to Classification of Neural Network