
Definition av medelväxlingsalgoritm
Genomsnittlig skiftalgoritm faller under oövervakad inlärning som kategoriseras som Clustering-algoritmen. Ideologin för algoritmen Mean Shift är att den iterativt tilldelar datapunkter till klusterna genom att skifta mot den punkt som har den högsta densitetspunkten (Mode). Genomsnittlig förskjutning underliggande logik är baserad på begreppet uppskattning av kärntätheten som kallas KDE.
Gemensam skiftalgoritmklustering
En oövervakad inlärningsteknik som upptäckts av Fukunaga och Hostetler för att hitta kluster:
- Mean Shift är också känd som den lägesökande algoritmen som tilldelar datapunkterna till klusterna på ett sätt genom att flytta datapunkterna mot området med hög täthet. Den högsta tätheten av datapunkter benämns modellen i regionen. Mean Shift-algoritmen har applikationer som används allmänt inom området datorsyn och bildsegmentering.
- KDE är en metod för att uppskatta fördelningen av datapunkterna. Det fungerar genom att placera en kärna på varje datapunkt. Kärnan i matematik är en viktningsfunktion som kommer att tillämpa vikter för enskilda datapunkter. Att lägga till all enskild kärna genererar sannolikheten.
Kärnfunktionen krävs för att uppfylla följande villkor:
- Det första kravet är att se till att uppskattningen av kärntätheten är normaliserad.
- Det andra kravet är att KDE är väl associerad med rymdens symmetri.
Två populära kärnfunktioner
Nedan visas de två populära kärnfunktionerna som används i den:
- Flat Kernel
- Gaussian Kernel
- Baserat på den använda Kernel-parametern varierar den resulterande densitetsfunktionen. Om ingen kärnparameter nämns, åberopas Gaussian Kernel som standard. KDE använder begreppet sannolikhetsdensitetsfunktion som hjälper till att hitta de lokala maxima för datadistributionen. Algoritmen fungerar genom att göra datapunkterna för att locka varandra och tillåter datapunkterna mot området med hög täthet.
- Datapunkterna som försöker konvergera mot de lokala maxima kommer att vara av samma grupp. I motsats till K-Means-klusteralgoritmen beror inte outputen från Mean Shift-algoritmen på antaganden om datapunktens form och antalet kluster. Antalet kluster bestäms av algoritmen med avseende på data.
- För att genomföra implementeringen av Mean Shift-algoritmen använder vi oss av pythonpaketet SKlearn.
Implementering av medelväxlingsalgoritmen
Nedan följer implementeringen av algoritmen:
Exempel 1
Baserat på Sklearn Tutorial för Mean Shift Clustering Algoritm. Det första utdraget kommer att implementera en medelväxlingsalgoritm för att hitta klustren i den 2-dimensionella datauppsättningen. Paket som används för att genomföra den genomsnittliga skiftalgoritmen.
Koda:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
En viktig sak att notera är att vi kommer att använda sklearns make_blobs-bibliotek för att generera datapunkter centrerade på 3 platser. För att tillämpa Mean shift-algoritmen på de genererade punkterna måste vi ställa in bandbredden som representerar interaktionen mellan längden. Sklearns bibliotek har inbyggda funktioner för att uppskatta bandbredden.
Koda:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
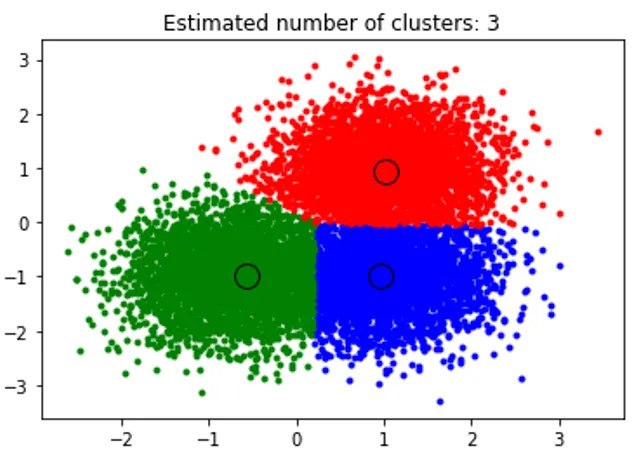
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Ovanstående kodstycke utför kluster och algoritmen hittade kluster centrerade på varje klump som vi genererade. Vi kan se att bilden nedifrån som visas i utdraget visar den genomsnittliga skiftalgoritmen som kan identifiera antalet kluster som behövs under körningstid och räkna ut lämplig bandbredd för att representera interaktionslängden.
Produktion:
Exempel 2
Baserat på bildsegmentering i datorvision. Det andra utdraget kommer att undersöka hur medelväxlingsalgoritmen som används i Deep Learning för att utföra segmentering av den färgade bilden. Vi använder medelväxlingsalgoritmen för att identifiera rumsliga kluster. Det tidigare utdraget använde vi 2-D-datauppsättning medan i detta exempel kommer att utforska 3D-utrymme. Pixel på bilden kommer att behandlas som datapunkter (r, g, b). Vi måste konvertera bilden till arrayformat så att varje pixel representerar datapunkt i den bild vi går till segmentet. Clustering av färgvärdena i rymden returnerar serie kluster, där pixlarna i klustret kommer att likna RGB-utrymme. Paket som används för att implementera Mean Shift Algoritm:
Koda:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Nedan för att utföra segmentering av originalbilden:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Den genererade bilden säger att detta tillvägagångssätt för att identifiera formen på bilder och bestämma de rumsliga klustren kan göras effektivt utan någon bildbehandling.
Produktion:


Fördelar och tillämpningar betyder skiftalgoritm
Nedan visas fördelarna och tillämpningen av den genomsnittliga algoritmen:
- Det används ofta för att lösa datorsyn, där det används för bildsegmentering.
- Kluster av datapunkter i realtid utan att ange antalet kluster.
- Presterar bra på bildsegmentering och videospårning.
- Mer robust mot outliers.
Fördelar med Mean Shift Algoritm
Nedan finns proffs-medelväxlingsalgoritmen:
- Utgången från algoritmen är oberoende av initialiseringar.
- Proceduren är effektiv eftersom den bara har en parameter - Bandbredd.
- Inga antaganden om antalet datakluster och form.
- Den har bättre prestanda än K-Means Clustering.
Nackdelar med medelväxlande algoritm
Nedan visas nackdelarna med den genomsnittliga skiftalgoritmen:
- Dyrt för stora funktioner.
- Jämfört med K-Means-kluster är det mycket långsamt.
- Algoritmutgången beror på parameterbredden.
- Output beror på fönstret.
Slutsats
Även om det är en enkel metod som främst används för att lösa problem relaterade till bildsegmentering, klustering. Det är jämförelsevis långsammare än K-Means och det är beräkningsbart dyrt.
Rekommenderade artiklar
Detta är en guide till Mean Shift-algoritmen. Här diskuterar vi problem relaterade till bildsegmentering, klustering, fördelar och två kärnfunktioner. Du kan också gå igenom våra andra relaterade artiklar för att lära dig mer-
- K- betyder klusteralgoritm
- KNN Algoritm i R
- Vad är genetisk algoritm?
- Kärnmetoder
- Kärnmetoder i maskinlärande
- Detaljförklaring av C ++ - algoritm