

Introduktion till AdaBoost-algoritm
AdaBoost-algoritmen kan användas för att öka prestandan för vilken maskininlärningsalgoritm som helst. Machine Learning har blivit ett kraftfullt verktyg som kan göra förutsägelser baserade på en stor mängd data. Det har blivit så populärt på senare tid att tillämpningen av maskininlärning kan hittas i våra dagliga aktiviteter. Ett vanligt exempel på det är att få förslag på produkter när du handlar online baserat på tidigare föremål som köpts av kunden. Maskininlärning, ofta kallad prediktiv analys eller prediktiv modellering, kan definieras som datorns förmåga att lära sig utan att programmeras uttryckligen. Den använder programmerade algoritmer för att analysera inmatningsdata för att förutsäga utdata inom ett acceptabelt intervall.
Vad är AdaBoost-algoritm?
När det gäller maskininlärning har boosting härstammat från frågan om en uppsättning svaga klassificerare kunde omvandlas till en stark klassificerare. Svag elev eller klassificerare är en elev som är bättre än slumpmässig gissning och detta kommer att vara robust när det gäller överanpassning som i en stor uppsättning svaga klassificerare, varvid varje svag klassificerare är bättre än slumpmässigt. Som en svag klassificerare används vanligtvis en enkel tröskel för en enda funktion. Om funktionen är över tröskeln än förutspådd tillhör den till positivt annars tillhör negativ.
AdaBoost står för 'Adaptive Boosting' som förvandlar svaga elever eller prediktorer till starka prediktorer för att lösa klassificeringsproblem.
För klassificering kan den slutliga ekvationen läggas nedan: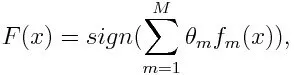
Här betecknar f m den svaga klassificeringen och m representerar motsvarande vikt.
Hur fungerar AdaBoost-algoritmen?
AdaBoost kan användas för att förbättra prestandan för maskininlärningsalgoritmer. Det används bäst med svaga elever och dessa modeller uppnår hög noggrannhet över slumpmässiga chanser för ett klassificeringsproblem. De vanliga algoritmerna med AdaBoost som används är beslutsträd med nivå ett. En svag elev är en klassificerare eller prediktor som presterar relativt dåligt när det gäller noggrannhet. Det kan också antydas att de svaga eleverna är enkla att beräkna och många instanser av algoritmer kombineras för att skapa en stark klassificering genom boosting.
Om vi tar en datauppsättning som innehåller ett antal poäng och överväger nedan
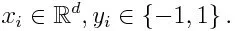
-1 representerar negativ klass och 1 indikerar positiv. Den initialiseras enligt nedan, vikten för varje datapunkt som:
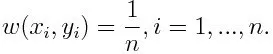
Om vi överväger iteration från 1 till M för m, får vi uttrycket nedan:
Först måste vi välja den svaga klassificeringen med det lägsta viktade klassificeringsfelet genom att anpassa de svaga klassificerarna till datauppsättningen.
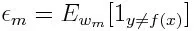
Beräkna sedan vikten för den m: a svaga klassificeringen enligt nedan:
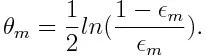
Vikten är positiv för alla klassificerare med högre noggrannhet än 50%. Vikten blir större om klassificeringen är mer exakt och den blir negativ om klassificeringen har noggrannhet mindre än 50%. Förutsägelsen kan kombineras genom att invertera skylten. Genom att invertera förutsägelsens tecken kan en klassificerare med 40% noggrannhet omvandlas till 60% noggrannhet. Så klassificeringen bidrar till den slutliga förutsägelsen, även om den presterar sämre än slumpvis gissning. Den slutliga förutsägelsen kommer dock inte att ha något bidrag eller få information från klassificeraren med exakt 50% noggrannhet. Den exponentiella termen i telleren är alltid större än 1 för ett felklassificerat fall från den positiva viktade klassificeraren. Efter iteration uppdateras de felklassificerade fallen med större vikter. De negativt viktade klassificeringarna uppträder på samma sätt. Men det är en skillnad att när tecknet är inverterat; de rätta klassificeringarna skulle ursprungligen omvandlas till felklassificering. Den slutliga förutsägelsen kan beräknas genom att ta hänsyn till varje klassificerare och sedan utföra summan av deras vägda förutsägelse.
Uppdatera vikten för varje datapunkt enligt nedan:
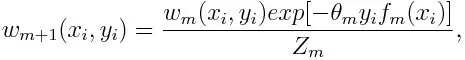
Zm är här normaliseringsfaktorn. Det ser till att summan av alla instansvikter blir lika med 1.
Vad används AdaBoost-algoritm för?
AdaBoost kan användas för ansiktsdetektering eftersom det verkar vara standardalgoritmen för ansiktsdetektering i bilder. Den använder en avstötningskaskad som består av många lager av klassificerare. När detekteringsfönstret inte känns igen i något lager som ett ansikte avvisas det. Den första klassificeringen i fönstret förkastar det negativa fönstret och håller beräkningskostnaderna till ett minimum. Även om AdaBoost kombinerar de svaga klassificerarna, används principerna för AdaBoost också för att hitta de bästa funktionerna att använda i varje lager av kaskaden.
Fördelar och nackdelar med AdaBoost-algoritmen
En av de många fördelarna med AdaBoost-algoritmen är att det är snabbt, enkelt och enkelt att programmera. Dessutom har den flexibiliteten att kunna kombineras med någon maskininlärningsalgoritm och det finns inget behov av att ställa in parametrarna förutom för T. Det har utvidgats till att lära sig problem utöver binär klassificering och det är mångsidigt eftersom det kan användas med text eller numeriskt data.
AdaBoost har också få nackdelar som det är från empiriska bevis och särskilt sårbara för enhetligt brus. Svaga klassificerare som är för svaga kan leda till låga marginaler och överanpassning.
Exempel på AdaBoost-algoritm
Vi kan överväga ett exempel på antagning av studenter till ett universitet där antingen antas eller nekas. Här kan de kvantitativa och kvalitativa uppgifterna hittas från olika aspekter. Till exempel kan resultatet av antagningen som kan vara ja / nej vara kvantitativt medan alla andra områden som färdigheter eller hobbyer för studenter kan vara kvalitativa. Vi kan enkelt hitta korrekt klassificering av träningsdata bättre än chansen för förhållanden som om eleven är bra på ett visst ämne, då är hon / han antagen. Men det är svårt att hitta mycket noggrann förutsägelse och då kommer svaga elever in i bilden.
Slutsats
AdaBoost hjälper till med att välja träningsuppsättningen för varje ny klassificerare som tränas baserat på resultaten från föregående klassificerare. Även när du kombinerar resultaten; den bestämmer hur mycket vikt som ska ges till varje klassificerings föreslagna svar. Det kombinerar de svaga eleverna för att skapa en stark en för att korrigera klassificeringsfel, vilket också är den första framgångsrika boostingalgoritmen för binära klassificeringsproblem.
Rekommenderade artiklar
Detta har varit en guide till AdaBoost-algoritmen. Här diskuterade vi konceptet, användningar, arbeta, fördelar och nackdelar med exempel. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Naive Bayes algoritm
- Frågor för marknadsföring av sociala medier
- Länkbyggnadsstrategier
- Plattform för marknadsföring av sociala medier