

Lär dig skillnaden mellan statistik och maskininlärning
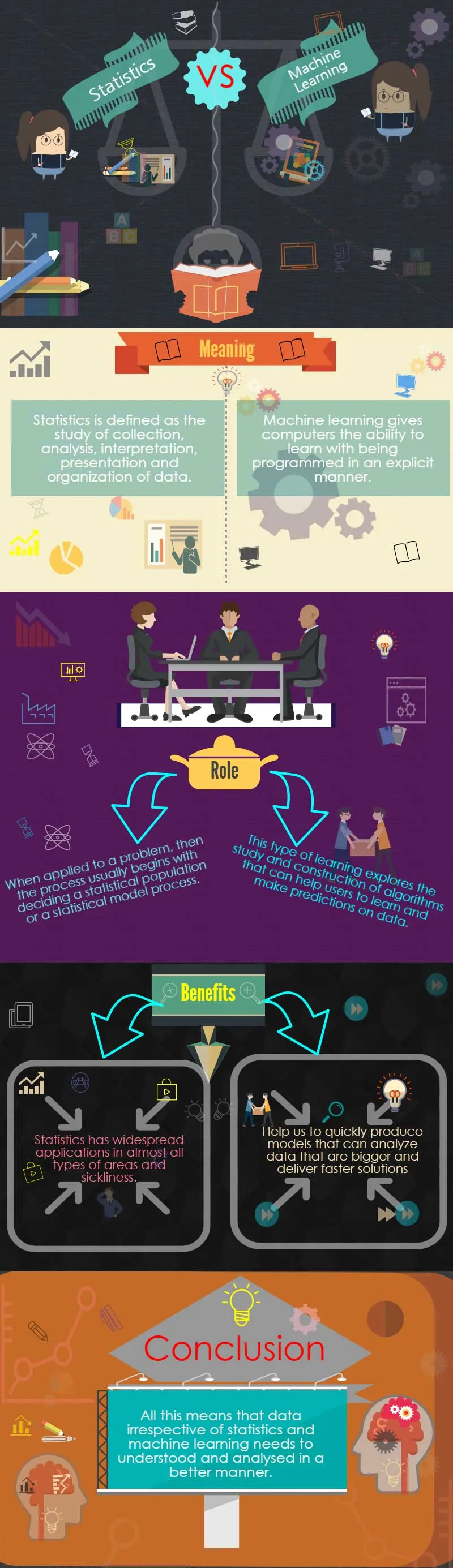
Maskininlärning används effektivt inom olika områden som upptäckt av bedrägerier, webbsökningsresultat, realtidsannonser på webbsidor och mobila enheter, textbaserad sentimentanalys, kreditpoäng och näst bästa erbjudanden, förutsägelse av utrustningsfel, nya prissättningsmodeller, nätverkets intrångsdetektering, mönster- och bildigenkänning, och e-postfiltreringsfiltrering bland andra fält. Statistik definieras som studien av insamling, analys, tolkning, presentation och organisering av data. När statistik tillämpas på ett vetenskapligt, industriellt eller samhälleligt problem, börjar processen vanligtvis med att bestämma en statistisk population eller en statistisk modellprocess.
Statistik kontra maskininlärning -
Data förändras och utvecklas ständigt. Men det är mycket viktigt att anpassa sig till dessa förändringar eftersom data är en kritisk aspekt av företagens tillväxt runt om i världen.
Data definieras som vanliga fakta och statistik som samlas in under den dagliga verksamheten hos ett varumärke / företag. Även om nästan alla typer av företag samlar in data, är det mycket viktigt för varumärken att känna till det.
Utan att kunna dra några insikter och kunskaper från uppgifterna blir de helt värdelösa. Det är därför även om företag har mycket information och data, ibland förlorar de för att de inte kan känna sig ur det.
Sedan företaget grundades samlar företag in mycket information och data om olika saker som kundinformation, produkthöjdpunkter, partnerproblem och anställdas feedback.
Dessa data och information kan effektivt användas för att registrera och mäta ett omfattande utbud av affärsfunktioner, vare sig det är externt eller internt. På egen hand är inte mycket informativt, men det är en grund för vilken företag kan fatta framtida beslut och också utveckla framgångsrika strategier.
Kunderna baserar sig på varumärken som bygger sitt namn och värde på marknaden. Det är därför kunddata är oerhört viktiga eftersom de tillåter varumärken att förbättra och förstå sina kunder på ett antal olika sätt.
Data är därför det enda sättet på vilket företag förstår många aspekter av företagets funktioner som ett antal förfrågningar, inkomna inkomster, bland annat erhållna utgifter.
Data är därför viktiga för varumärken för att förstå kundens tankesätt och förväntningar. Sammantaget är data ett viktigt element för att säkerställa fortsatt framgång och tillväxt för alla företag, särskilt i denna konkurrensålder och tider.
Artikeln om statistik vs maskininlärning är strukturerad enligt nedan -
- Statistik mot maskininlärningsinfografi
- Vad är skillnaden Statistik kontra maskininlärning?
- En mer djupgående titt på statistik och dess betydelse i samhället
- En mer djupgående titt på maskininlärning och dess betydelse i samhället
- Slutsats - Statistik kontra maskininlärning
Statistik mot maskininlärningsinfografi
Är data och information densamma? Vad är skillnaden Statistik kontra maskininlärning?
Data och information är två distinkta saker. Medan data är råa fakta och statistik, är information samma data som presenteras på ett korrekt och snabbt sätt.
Vidare är information specifik och organiserad, generellt med syfte att ge sammanhang och förståelse för en viss aspekt av varumärkesfunktion. Ett annat sätt på vilket information skiljer sig från data är att det är genom informationen att varumärken kan fatta korrekta beslut och skapa kampanjer som är kreativa, effektiva och engagerande.
Det är därför information är så viktig eftersom det gör det möjligt för varumärken att fatta beslut som kan användas av ledningen för att verkligen stärka sig själva.
Det är därför varumärken strävar efter att samla in information om kunder och kunder så att de kan samarbeta med dem på ett effektivt sätt. Allt detta sagt är det viktigt att komma ihåg att det verkliga värdet på information ligger i dess förmåga att ge riktning till företaget.
Om det till exempel saknas kundtillfredsställelse enligt informationen från kunderna, är det bara till hjälp om varumärket ändrar denna uppfattning genom att erbjuda bättre värde för sina produkter och tjänster.
Kort sagt ska informationsprocessen utgöra en del av en bredare granskningsprocess inom företagen, så att den kan hjälpa dem att producera bättre och mer lönsamma resultat.
Därför kan information samlas in och analyseras på olika sätt som är maskininlärning och statistik.
Från personer som bor i ett land till atomer i en kristall kan befolkningen vara av olika slag. Att hantera alla aspekter av data som planering av datainsamling till experiment är statistik ett varierat och omfattande område.
Maskininlärning, å andra sidan, är ett underfält inom datavetenskap som har utvecklats från studiet av beräkningsteori i konstgjord intelligens och mönsterigenkänning.
Arthur Samuel definierade 1959 maskininlärning som studiefältet som ger datorer möjlighet att lära sig med att vara programmerade på ett uttryckligt sätt.
Denna typ av lärande utforskar studier och konstruktion av algoritmer som kan hjälpa användare att lära sig och göra förutsägelser om data. Sådana algoritmer fungerar genom en modellskapning och används för att göra datadriven förutsägelse snarare än att följa statiska programinstruktioner.
Rekommenderade kurser
- Kurs i IP-routing
- Hacking-utbildningskurser
- Kurs om RMAN
- Online certifieringskurs i Python

En mer djupgående titt på statistik och maskininlärning
Statistik spelar en mycket viktig roll i nästan alla områden av mänsklig aktivitet. Från att hjälpa till att bestämma ett lands per capita till sysselsättningsgraden till antalet medicinska / skolanläggningar som krävs i en region, har statistik och maskininlärning en mycket viktig roll i människors samhälle.
I nuvarande tider har statistik en mycket viktig och kritisk position inom ett antal områden inklusive handel, handel, psykologi, kemi, botanik, astronomi bland många andra.
Detta beror på att statistik har ett brett användningsområde inom nästan alla typer av områden och sjukdom. Här är några viktiga områden där statistik och maskininlärning kan tillämpas för att samla in bättre information och insikter.
- Verksamhet: Statistik har en mycket viktig och kritisk roll att spela inom affärsområdet. Detta beror på att varumärken och företag är extremt konkurrenskraftiga, vilket gör det svårt för varumärken att ligga före sina kunders förväntningar och önskemål. Det är därför viktigt att varumärken fattar snabba beslut så att de kan fatta bättre beslut. Statistik kan hjälpa varumärken att förstå kundens förväntningar och därmed balansera deras efterfrågan och utbud på ett effektivt sätt. Detta innebär att många av varumärkets beslut är beroende av goda statistiska beslut och insikter.
- Ekonomi: Ett annat viktigt område där statistik spelar en viktig roll i ekonomin. Detta beror på att statistik till stor del beror på statistik. Detta beror på att nationalinkomstkonton är viktiga indikatorer för ekonomer och administratörer. Statistiska metoder används för att utarbeta dessa konton och även för att samla in och analysera data. Förhållandet mellan tillgång och krav studeras genom statistisk analys och nästan alla aspekter av ekonomi kräver en stor och komplicerad förståelse av statistik.
- Matematik: Statistik är en integrerad del av naturvetenskap och samhällsvetenskap. Naturvetenskapens metoder är tillförlitliga men deras slutsatser är ibland inte så troligtvis för att de är baserade på ofullständiga bevis. Statistisk hjälp för att beskriva dessa mätningar på ett exakt sätt. Många statiska metoder som sannolikhetsgenomsnitt, dispersioner, uppskattning är en integrerad del av matematiken och används ofta inom detta område.
- Banking: Ett annat område där statistik spelar en viktig roll i bankrörelsen. Banker behöver statistik av ett antal skäl och syften. Nästan alla banker arbetar med principen att när en av deras kunder investerar lite pengar i sin bank, kommer de att hålla dem i sin bank under en tid och inte ta ut dem. Genom att tjäna vinster från dessa insättningar tjänar banken vinster och detta är den huvudsakliga källan till deras intäkter. Bankirerna använder statistiska tillvägagångssätt baserade på sannolikhet för att uppskatta antalet insättare och deras fordringar under en viss dag, vilket gör det möjligt för dem att fungera på ett smidigt och effektivt sätt.
- Statlig förvaltning: Statistik är ett annat område som är avgörande för tillväxt och utveckling i alla länder. Detta beror på att statistik är grunden för vilken politik som utarbetas i landet. Det är därför statistiska uppgifter används allmänt för att fatta administrativa beslut. Om till exempel regeringen vill höja de anställdas löneskala för att hjälpa dem att höja sin levnadsstandard är det genom statistik att regeringen kan hitta en ökning av levnadskostnaderna. Dessutom är beredningen av federala och provinsiella statsbudgetar också beroende av statistik eftersom det hjälper tjänstemännen att uppskatta de förväntade utgifterna och intäkterna från olika källor. Så statistik är mycket viktigt för att hjälpa regeringarna utföra sina uppgifter på ett smidigt sätt.

En mer djupgående titt på maskininlärning och dess betydelse i samhället
Datorer och bärbara datorer har tagit hela världen med storm och har drastiskt förändrat livet för många människor. Låt oss visualisera en situation i en minut. Låt oss försöka tänka på en värld utan datorer.
Om detta hände skulle människor inom det medicinska området inte ha hittat många botemedel mot sjukdomar, eftersom datorer har spelat en viktig roll i processen för att hjälpa läkare få bättre insikter i världen av sjukdomar och hälsa.
Återigen skulle filmer som Toy Story och Jurassic Park inte ha varit möjligt utan datorer eftersom dessa filmer har använt datorgrafik och animering.
Apotek skulle ha svårt att hålla reda på vilka mediciner de ska ge till sina patienter. Att räkna röster skulle vara nära omöjligt utan datorer och ännu viktigare rymdutforskning skulle fortfarande ha varit en avlägsen dröm för alla rymdentusiaster.
På grund av datorernas växande betydelse har datorteknologier fått en ännu större roll och detta har resulterat i maskinernas förmåga att automatiskt tillämpa komplexa matematiska beräkningar på big data i en snabbare och snabbare takt.
Några av de allmänt publicerade exemplen på applikationer för maskininlärning som idag är extremt populära i världen inkluderar följande:
- Kärnan i maskininlärning är den extremt populära självstyrda bilen från Google
- Onlinerekommendationer som är anpassade för plattformar som Amazon och Netflix är ett resultat av maskininlärningsapplikationer som nu passar för att förstå det vardagliga mänskliga beteendet
- Att förstå kundbeteende på Twitter för varumärken och nu maskininlärning med skapande av språklig regel hjälper varumärken att förstå och stärka sina kunder i det offentliga området
- Bedrägeri upptäckt är ett viktigt område där maskininlärning hjälper varumärken att vara säkra och effektiva på alla plattformar
Idag finns det ett växande intresse för maskininlärning eftersom i dag de växande volymerna och variationerna av tillgängliga data, beräkningsbehandling har resulterat i ett behov av billigare och kraftfulla dataanalysmetoder.
Detta innebär att maskininlärning kan hjälpa oss att snabbt producera modeller som kan analysera större data och leverera snabbare lösningar som är korrekta och effektiva, även i stor skala.
Allt detta innebär att förutsägelser med högt värde kan hjälpa ekonomier och varumärken att fatta bättre och smartare beslut, inte bara utan mänsklig intervention utan också i realtid.
Varumärken behöver snabba rörliga modeller för att hålla jämna steg med marknadens krav och de kan göra detta på ett effektivt sätt genom användning av maskininlärning.
Medan människor generellt sett kan skapa en eller två bra modeller i veckan, kan maskininlärning skapa tusentals modeller i veckan, vilket gör märken mer effektiva och bättre på lång sikt också.
Maskininlärning skiljer sig därför mycket från datastatistik. Enkelt uttryckt, medan maskininlärning använder samma algoritmer och tekniker, är det en stor skillnad mellan dessa två statistik och maskininlärningstekniker.
Medan data mining upptäcker tidigare okända mönster och kunskap, används maskininlärning för att reproducera kända mönster och kunskap.
Dessa mönster tillämpas sedan automatiskt på andra data, och sedan används de för att hjälpa de berörda människorna att fatta bättre beslut och åtgärder.
Med den ökade användningen av datorer utvecklas datatekniker och maskininlärning också snabbt för att möta behoven hos märken och företag i olika sektorer.
Neurala nätverk har länge använts i data mining-applikationer och nu med datorns kraft är det möjligt att skapa flera neurala nätverk som har många lager. I maskinlärande lingo kallas dessa djupa neurala nätverk.
Slutsats - Statistik kontra maskininlärning
Allt detta innebär att data oavsett statistik kontra maskininlärning måste förstå och analyseras på ett bättre sätt. Detta beror på att datainsikten är avgörande för framgångar och misslyckanden hos varumärken i olika kategorier och att investera dem är ett av de främsta kraven för alla typer av företag.
Rekommenderade artiklar
Så här är några artiklar som hjälper dig att få mer detaljerad information om statistik vs maskininlärning och även om statistik och maskininlärning så bara gå igenom länken som ges nedan.
- Machine Learning vs Statistics
- Karriärer i statistik
- Viktigt steg till investeringsbankers livsstil
- Statistikintervjufrågor | Användbart och mest frågat