
Introduktion till hivearkitektur
Hive Architecture är byggd ovanpå Hadoop-ekosystemet. Hive har ofta interaktioner med Hadoop. Apache Hive hanterar både domän SQL-databassystem och Map-reducera. Hive-applikationer kan skrivas på olika språk som Java, python. Hivearkitektur visar hur man skriver Hive Query-språk och hur interaktionen mellan programmeraren görs med kommandoradgränssnittet. Hivefrågespråk gör jobbet med att konvertera alla Hadoop-klusteruppgifter genom kartminskning. Som vi alla visste Hadoop att bearbeta big data i en distribuerad miljö och bildar en öppen källkodsram. Med bikupan är det flexibelt att hantera och köra frågan och en bra supporter för att utföra funktioner som inkapsling, ad-hoc-frågor. Den här artikeln ger en kort introduktion till bikuparkitektur som finns på Hadoop-lagret för att utföra sammanfattning i big data.
Hive Arkitektur med dess komponenter
Hive spelar en viktig roll i dataanalys och integration av business intelligence och det stöder filformat som textfil, rc-fil. Hive använder ett distribuerat system för att bearbeta och köra frågor och lagringen görs så småningom på disken och behandlas slutligen med ett kartminskningsramverk. Det löser optimeringsproblemet som hittas under kartminskning och hive utföra batchjobb som tydligt förklaras i arbetsflödet. Här lagrar en metabutik schemainformation. Ett ramverk som heter Apache Tez är designat för realtidsfrågor.
De viktigaste komponenterna i Hive anges nedan:
- Hive klienter
- Hive-tjänster
- Hive-lagring (Meta-lagring)
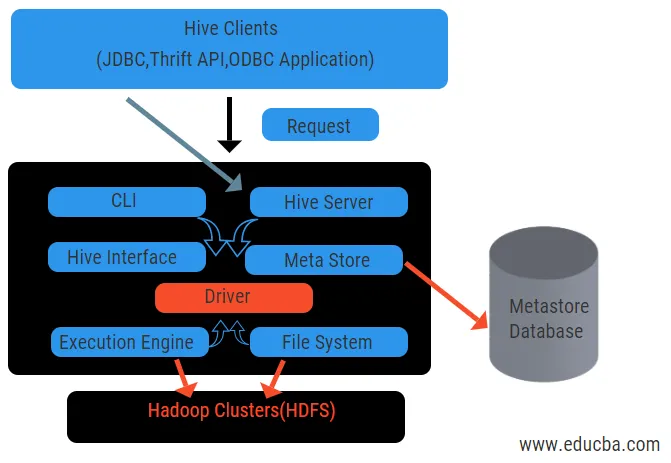
Diagrammet ovan visar strukturen för Hive och dess komponentelement.
Hive-klienter:
De inkluderar Thrift-applikation för att utföra enkla hive-kommandon som är tillgängliga för python, rubin, C ++ och drivrutiner. Dessa klientapplikationsfördelar för att utföra frågor på bikupan. Hive har tre typer av klientkategorisering: sparsamhetsklienter, JDBC och ODBC klienter.
Hive-tjänster:
Att bearbeta alla frågor hive har olika tjänster. Alla funktioner definieras enkelt av användaren i bikupan. Låt oss se alla dessa tjänster i korthet:
- Kommandoradgränssnitt (användargränssnitt): Det möjliggör interaktion mellan användaren och bikupan, ett standardskal. Det tillhandahåller ett GUI för att köra kommandorad från bikupor och insikt i bikupan. Vi kan också använda webbgränssnitt (HWI) för att skicka frågor och interaktioner med en webbläsare.
- Hive Driver: Den tar emot frågor från olika källor och klienter som sparserver och lagrar och hämtar på ODBC- och JDBC-drivrutiner som automatiskt är anslutna till bikupan. Denna komponent gör semantisk analys för att se tabellerna från metastore som analyserar en fråga. Drivrutinen tar hjälp av kompilatorn och utför funktioner som en parser, Planner, Exekvering av MapReduce-jobb och optimering.
- Compiler: Parsning och semantisk process för frågan görs av kompilatorn. Den konverterar frågan till ett abstrakt syntaxträd och igen till DAG för kompatibilitet. Optimisatoren delar i sin tur de tillgängliga uppgifterna. Exekutorns uppgift är att köra uppgifterna och övervaka rörledningsschemat för uppgifterna.
- Execution Engine: Alla frågor behandlas av en exekveringsmotor. En DAG-scenplaner utförs av motorn och hjälper till att hantera beroenden mellan de tillgängliga stadierna och utföra dem på rätt komponent.
- Metastore: Det fungerar som ett centralt arkiv för att lagra all strukturerad information om metadata också är det en viktig aspektdel för bikupan eftersom den har information som tabeller och uppdelningsdetaljer och lagring av HDFS-filer. Med andra ord säger vi att metastore fungerar som ett namnområde för tabeller. Metastore anses vara en separat databas som också delas av andra komponenter. Metastore har två delar som kallas service och backlog-lagring.
Hive-datamodellen är strukturerad i partitioner, hinkar, tabeller. Alla dessa kan filtreras, ha partitionstangenter och för att utvärdera frågan. Hivefrågan fungerar på Hadoop-ramverket, inte på den traditionella databasen. Hive-server är ett gränssnitt mellan en fjärrklientfrågor till bikupan. Exekveringsmotorn är helt inbäddad i en hive-server. Du kan hitta bikupapplikationer i maskininlärning, affärsintelligens i detekteringsprocessen.
Work Flow of Hive:
Hive fungerar i två typer av lägen: interaktivt läge och icke-interaktivt läge. Tidigare läge tillåter alla bikupekommandon att gå direkt till bikupskal medan den senare typen kör kod i konsolläge. Data delas upp i partitioner som vidare delas upp i hinkar. Exekveringsplaner är baserade på aggregering och dataskepp. En ytterligare fördel med att använda bikupa är att det enkelt bearbetar storskalig information och har fler användargränssnitt.
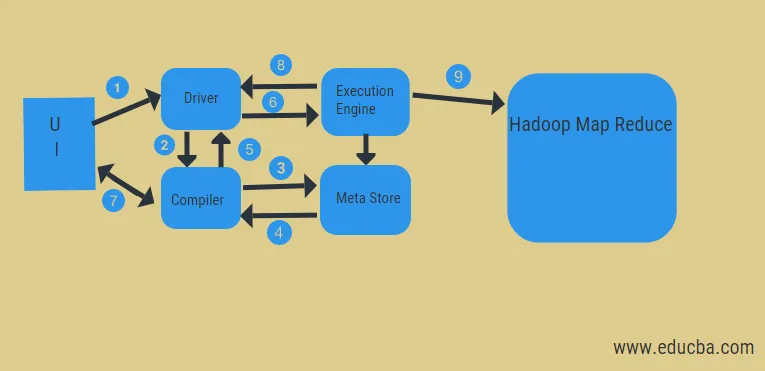
Från diagrammet ovan kan vi få en glimt av dataflödet i bikupan med Hadoop-systemet.
Stegen inkluderar:
- köra frågan från UI
- få en plan från föraren uppgifter DAG stadier
- få metadataförfrågan från meta-butiken
- skicka metadata från kompilatorn
- skicka planen tillbaka till föraren
- Kör plan i körmotorn
- hämta resultat för rätt användarfråga
- skicka resultat i två riktningar
- exekveringsmotorbehandling i HDFS med kartminskning och hämtning av resultat från datanoderna som skapats av jobbsökaren. det fungerar som en koppling mellan Hive och Hadoop.
Exekveringsmotorns uppgift är att kommunicera med noder för att få informationen lagrad i tabellen. Här utförs SQL-operationer som skapa, släpp, ändra för att komma åt tabellen.
Slutsats:
Vi har gått igenom Hive Architecture och deras arbetsflöde, hive utför i princip petabyte datamängd och därmed är det ett datalagerpaket på Hadoop-plattformen. Eftersom bikupan är ett bra val att hantera hög datavolym hjälper det i dataförberedelser med guiden för SQL-gränssnittet för att lösa MapReduce-problem. Apache hive är ett ETL-verktyg för att bearbeta strukturerade data. Att känna till arbetet med bikuparkitektur hjälper företagare att förstå principen att fungera i bikupan och har en bra start med bikupprogrammering.
Rekommenderade artiklar:
Detta har varit en guide till Hive Architecture. Här diskuterar vi bikupearkitekturen, olika komponenter och arbetsflödet i bikupan. Du kan också titta på följande artiklar för att lära dig mer-
- Hadoop Arkitektur
- Användningar av Ruby
- Vad är C ++
- Vad är MySQL-databas
- Hive Order by