

Introduktion till Hadoop Architecture
Hadoop Architecture är en öppen källkodsram som hjälper dig att enkelt bearbeta stora datasätt. Det hjälper till att skapa applikationer som bearbetar enorma data med högre hastighet. Den använder de distribuerade datorkoncepten där data sprids över olika noder i ett kluster. Applikationerna som byggs med Hadoop använder sig av handelsdatorer. Dessa datorer är lätt tillgängliga på marknaden till billiga priser. Detta resultat åstadkommer större beräkningskraft till en låg kostnad. All information som finns i Hadoop finns på HDFS istället för ett lokalt filsystem. HDFS är ett Hadoop Distribuerat filsystem. Denna modell är baserad på datalokalitet där beräkningslogiken skickas till de noder som finns i ett kluster som innehåller data. Denna logik är inget annat än en logik som sammanställer programmet.
Hadoop Arkitektur
Den grundläggande idén med denna arkitektur är att hela lagring och bearbetning sker i två steg och på två sätt. Det första steget är bearbetning som görs av Map reducera programmering och det andra vägssteget är att lagra data som görs på HDFS. Den har en master-slavarkitektur för lagring och databehandling. Huvudnoden för datalagring i Hadoop är namnoden. Det finns också en huvudnod som gör arbetet med att övervaka och parallella med databehandlingen genom att använda Hadoop Map Reduce. Slavarna är andra maskiner i Hadoop-klustret som hjälper till att lagra data och även utföra komplexa beräkningar. Varje slavnod har tilldelats en task tracker och en datanode har en job tracker som hjälper till att köra processerna och synkronisera dem effektivt. Denna typ av system kan ställas in antingen på moln eller på plats. Namnnoden är en enda felpunkt när den inte körs i läget med hög tillgänglighet. Hadoop-arkitekturen har också möjlighet att upprätthålla en stand by Name-nod för att skydda systemet från fel. Tidigare fanns sekundära namnnoder som fungerade som en säkerhetskopia när den primära namnnoden var nere.
FSimage och redigera logg
FSimage och redigeringslogg säkerställer att filsystemmetadata hålls kvar för att hålla jämna steg med all information och namnnod lagrar metadata i två filer. Dessa filer är FSimage och redigeringsloggen. FSimages uppgift är att hålla en fullständig ögonblicksbild av filsystemet vid en viss tidpunkt. Förändringarna som ständigt görs i ett system måste hållas register över. Dessa stegvisa ändringar som att byta namn på eller lägga till information till filen lagras i redigeringsloggen. Ramverket ger ett bättre alternativ snarare än att skapa en ny FSimage varje gång, ett bättre alternativ att kunna lagra data medan en ny fil för FSimage. FSimage skapar en ny stillbild varje gång ändringar görs Om Namnnoden misslyckas kan den återställa sitt tidigare tillstånd. Den sekundära namnnoden kan också uppdatera dess kopia när det sker ändringar i FSimage och redigera loggar. Således säkerställer det att även om namnnoden är nere, i närvaro av sekundär namnnod det inte kommer att förlora data. Namnnod kräver inte att dessa bilder måste laddas om på sekundärnamnoden.
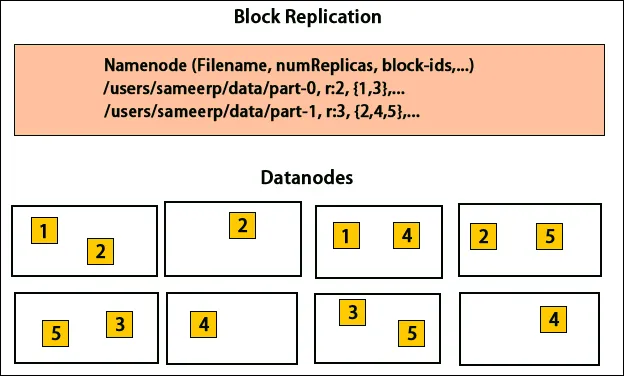
Datareplikation
HDFS är utformad för att bearbeta data snabbt och tillhandahålla tillförlitlig data. Den lagrar data över maskiner och i stora kluster. Alla filer lagras i en serie block. Dessa block replikeras för feltolerans. Blockstorleken och replikeringsfaktorn kan bestämmas av användarna och konfigureras enligt användarkraven. Som standard är replikeringsfaktorn 3. Replikeringsfaktorn kan anges vid skapandet av filen och den kan ändras senare. Alla beslut angående dessa kopior fattas med namnet nod. Namnnoden fortsätter att skicka hjärtslag och blockera rapport med jämna mellanrum för alla datanoder i klustret. Mottagandet av hjärtslag innebär att datanoden fungerar korrekt. Blockrapport anger listan över alla block som finns i datanoden.
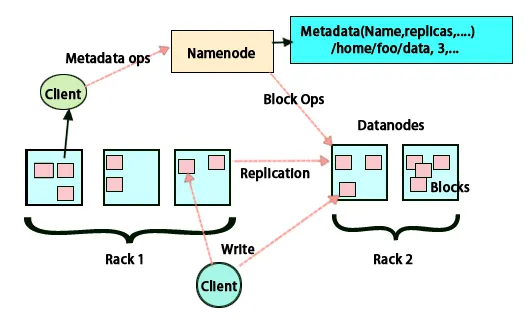
Placering av kopior
Placering av kopior är en mycket viktig uppgift i Hadoop för tillförlitlighet och prestanda. Alla olika datablock placeras på olika rack. Implementeringen av replikplacering kan göras enligt tillförlitlighet, tillgänglighet och nätverksbandbreddanvändning. Datorns kluster kan spridas över olika rack. Högst två noder kan placeras på samma rack. Den tredje kopian bör placeras på ett annat rack för att säkerställa mer tillförlitlighet för data. De två noderna på racket kommunicerar genom olika omkopplare. Namnnoden har rack-id för varje datanod. Men att placera alla noder på olika rack hindrar förlust av data och tillåter användning av bandbredd från flera rack. Det minskar också inter-rack-trafiken och förbättrar prestandan. Dessutom är risken för rackfel mycket mindre jämfört med risken för nodfel. Det minskar den sammanlagda nätverksbandbredden när data läses från två unika rack snarare än tre.
Karta Minska
Map Reduce används för bearbetning av data som lagras på HDFS. Den skriver distribuerade data över distribuerade applikationer som säkerställer effektiv behandling av stora datamängder. De bearbetar på stora kluster och kräver vara som är pålitlig och feltolerant. Kärnan i Map-reducera kan vara tre operationer som kartläggning, insamling av par och blandning av resulterande data.
Slutsats - Hadoop Architecture
Hadoop är en öppen källkodsram som hjälper till i ett feltolerant system. Den kan lagra stora mängder data och hjälper till att lagra tillförlitliga data. De två delarna av lagring av data i HDFS och bearbetning av den genom kartminskning hjälper till att fungera korrekt och effektivt. Den har en arkitektur som hjälper till att hantera alla block av data och även ha den senaste kopian genom att lagra den i FSimage och redigera loggar. Replikeringsfaktorn hjälper också till att ha kopior av data och få tillbaka dem närhelst det finns ett fel. HDFS flyttar också borttagna filer till papperskorgen för optimal användning av utrymmet.
Rekommenderade artiklar
Detta har varit en guide till Hadoop Architecture. Här har vi diskuterat arkitekturen, kartminskning, placering av kopior, datareplikation. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Bli Hadoop-utvecklare
- Introduktion till Android
- Vad är Tableau? | En översikt
- Vad är MapReduce i Hadoop?