

Introduktion till beslutsträdalgoritm
När vi har ett problem att lösa som är antingen en klassificerings- eller regressionsproblem, är beslutsträdalgoritmen en av de mest populära algoritmerna som används för att bygga klassificerings- och regressionsmodellerna. De faller under kategorin övervakad inlärning, dvs. data som är märkta.
Vad är beslutsträdalgoritm?
Decision Tree Algoritm är en övervakad maskininlärningsalgoritm där data kontinuerligt delas upp på varje rad baserat på vissa regler tills det slutliga resultatet genereras. Låt oss ta ett exempel, anta att du öppnar ett köpcentrum och naturligtvis skulle du vilja att det ska växa i affärer med tiden. Så för den delen kräver du återvändande kunder plus nya kunder i ditt köpcentrum. För detta skulle du förbereda olika affärs- och marknadsföringsstrategier som att skicka e-post till potentiella kunder; skapa erbjudanden och erbjudanden, inriktning på nya kunder osv. Men hur vet vi vem som är de potentiella kunderna? Med andra ord, hur klassificerar vi kategorin av kunder? Liksom vissa kunder kommer att besöka en gång i veckan och andra vill besöka en eller två gånger i månaden, eller andra kommer att besöka om ett kvartal. Så beslutsträd är en sådan klassificeringsalgoritm som klassificerar resultaten i grupper tills det inte finns mer likhet kvar.
På detta sätt går beslutsträdet ner i ett trädstrukturerat format. Huvudkomponenterna i ett beslutsträd är:
- Beslutsnoder, som är där uppgifterna delas eller säger, det är en plats för attributet.
- Beslutslänk, som representerar en regel.
- Beslutsblad, som är de slutliga resultaten.

Arbeta av en beslutsträdalgoritm
Det finns många steg som är involverade i arbetet med ett beslutsträd:
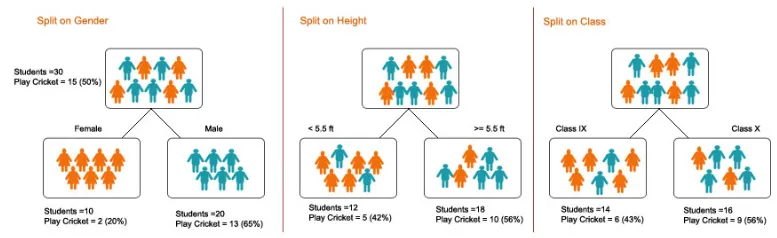
1. Delning - Det är processen för uppdelning av data i delmängder. Delning kan göras på olika faktorer som visas nedan, dvs på könsbasis, höjdbasis eller baserat på klass.
2. Beskärning - Det är processen att förkorta grenarna på beslutsträdet och därmed begränsa träddjupet
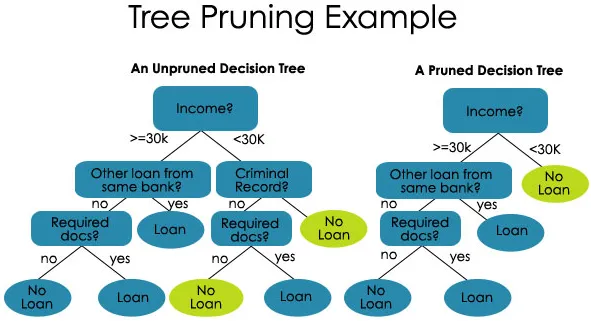
Beskärning är också av två typer:
- Förskärning - Här slutar vi växa trädet när vi inte hittar någon statistiskt signifikant samband mellan attributen och klassen vid någon viss nod.
- Efter-beskärning - För att kunna posta beskärning måste vi validera testuppsättningsmodellens prestanda och sedan klippa grenarna som är ett resultat av överanpassning av buller från träningsuppsättningen.
3. Val av träd - Det tredje steget är processen att hitta det minsta trädet som passar uppgifterna.
Exempel och illustration av konstruktion av ett beslutsträd
Som vi har lärt oss principerna för ett beslutsträd. Låt oss förstå och illustrera detta med hjälp av ett exempel.
Låt oss säga att du vill spela cricket på en viss dag (till exempel lördag). Vilka är de faktorer som är involverade som kommer att avgöra om spelet kommer att hända eller inte?
Det är uppenbart att den viktigaste faktorn är klimatet, ingen annan faktor har så mycket sannolikhet som lika mycket klimat har för lekavbrottet.
Vi har samlat in data från de senaste 10 dagarna som presenteras nedan:
| Dag | Väder | Temperatur | Fuktighet | Vind | Spela? |
| 1 | Molnig | Varm | Hög | Svag | Ja |
| 2 | Solig | Varm | Hög | Svag | Nej |
| 3 | Solig | Mild | Vanligt | Stark | Ja |
| 4 | Regnig | Mild | Hög | Stark | Nej |
| 5 | Molnig | Mild | Hög | Stark | Ja |
| 6 | Regnig | Häftigt | Vanligt | Stark | Nej |
| 7 | Regnig | Mild | Hög | Svag | Ja |
| 8 | Solig | Varm | Hög | Stark | Nej |
| 9 | Molnig | Varm | Vanligt | Svag | Ja |
| 10 | Regnig | Mild | Hög | Stark | Nej |
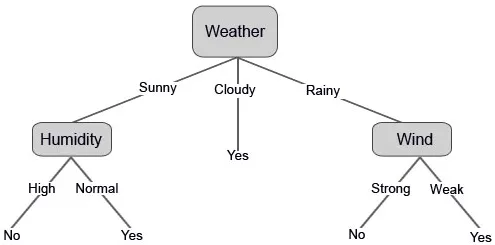
Låt oss nu konstruera vårt beslutsträd baserat på de uppgifter som vi har. Så vi har delat beslutsträdet i två nivåer, den första är baserad på attributet "Väder" och den andra raden är baserat på "Fuktighet" och "Vind". Nedanstående bilder illustrerar ett lärt beslutsträd.
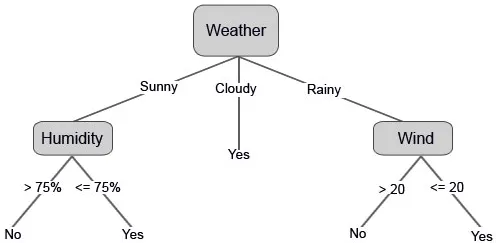
Vi kan också ställa in några tröskelvärden om funktionerna är kontinuerliga.
Vad är entropi i beslutsträdalgoritmen?
Med enkla ord är entropi måttet på hur störande dina data är. Även om du kanske har hört den här termen i dina matematik- eller fysikklasser, är det samma här.
Anledningen till att Entropy används i beslutsträdet är för att det slutliga målet i beslutsträdet är att gruppera liknande datagrupper i liknande klasser, dvs att rensa uppgifterna.
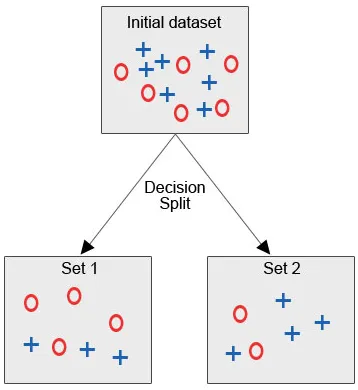
Låt oss se bilden nedan, där vi har det första datasättet och vi måste tillämpa beslutsträdalgoritm för att gruppera de liknande datapunkterna i en kategori.
Efter beslutsdelningen, som vi tydligt kan se, faller de flesta röda cirklar under en klass medan de flesta av de blå korsarna faller under en annan klass. Därför var ett beslut att klassificera attributen som kunde baseras på olika faktorer.
Låt oss försöka göra matematik här:
Låt oss säga att vi har "N" -uppsättningar för objektet och dessa artiklar faller i två kategorier, och nu för att gruppera data baserade på etiketter introducerar vi förhållandet:
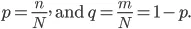
Entropin för vår uppsättning ges av följande ekvation:
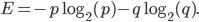
Låt oss kolla grafen för den givna ekvationen:
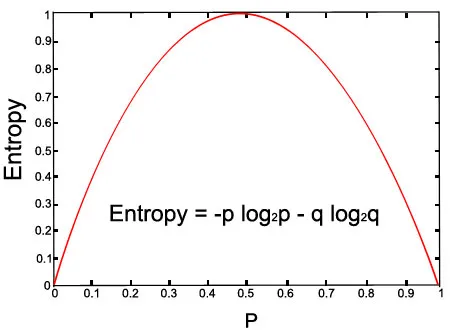
Ovanstående bild (med p = 0, 5 och q = 0, 5)
fördelar
1. Ett beslutsträd är enkelt att förstå och när det först är förstått kan vi konstruera det.
2. Vi kan implementera ett beslutsträd för såväl numeriska som kategoriska data.
3. Beslutsträdet har visat sig vara en robust modell med lovande resultat.
4. De är också tidseffektiva med stora data.
5. Det kräver mindre ansträngning för utbildning av uppgifterna.
nackdelar
1. Instabilitet - Endast om informationen är exakt och korrekt ger beslutsträdet lovande resultat. Även om det sker en liten förändring av inmatningsdata kan det orsaka stora förändringar i trädet.
2. Komplexitet - Om datasatsen är enorm med många kolumner och rader, är det en mycket komplex uppgift att designa ett beslutsträd med många grenar.
3. Kostnader - Ibland förblir kostnad också en viktig faktor eftersom det krävs avancerad kunskap i kvantitativ och statistisk analys när man måste bygga ett komplext beslutsträd.
Slutsats
I den här artikeln lärde vi oss om beslutsträdets algoritm och hur man konstruerar en. Vi såg också den stora roll som Entropy spelar i beslutsträdets algoritm och slutligen såg vi fördelar och nackdelar med beslutsträdet.
Rekommenderade artiklar
Detta har varit en guide till beslutsträdalgoritmen. Här diskuterade vi rollen som Entropy, Working, Advantages and Disruption. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Viktiga metoder för gruvdrift
- Vad är webbapplikation?
- Guide till Vad är datavetenskap?
- Data Analyst intervjufrågor
- Tillämpning av beslutsträd vid dataanläggning