

Introduktion till gnistkommandon
Apache Spark är ett ramverk som är byggt ovanpå Hadoop för snabba beräkningar. Det utökar begreppet MapReduce i det klusterbaserade scenariot för att effektivt köra en uppgift. Spark Command är skriven i Scala.
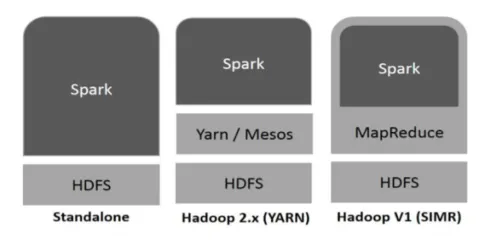
Hadoop kan användas av Spark på följande sätt (se nedan):
Figur 1
https://www.tutorialspoint.com/
- Fristående: Spark direkt utplacerat ovanpå Hadoop. Sparkjobb körs parallellt på Hadoop och Spark.
- Hadoop YARN: Spark körs på garn utan behov av någon förinstallation.
- Spark in MapReduce (SIMR): Spark in MapReduce används för att starta gnistjobb, utöver fristående distribution. Med SIMR kan man starta Spark och kan använda sitt skal utan någon administrativ åtkomst.
Gnistkomponenter:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLIB
- Graphx
Resilient Distribuerade databaser (RDD) betraktas som den grundläggande datastrukturen för Spark-kommandon. RDD är oföränderlig och skrivskyddad. All slags beräkningar i gnistkommandon görs genom transformationer och åtgärder på RDD: er.
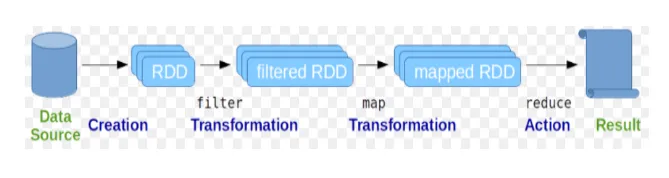
Fig. 2
Google bild
Gnistskal ger ett medium för användare att interagera med dess funktioner. Gnistkommandon har många olika kommandon som kan användas för att bearbeta data på det interaktiva skalet.
Grundläggande gnistkommandon
Låt oss ta en titt på några av de grundläggande gnistkommandona som ges nedan: -
-
Så här startar du gnistskal:

Fig 3
-
Läs fil från det lokala systemet:

Här är "sc" gnistkontexten. Med tanke på “data.txt” finns i hemmakatalogen, läses det så här, annars måste man ange hela sökvägen.
-
Skapa RDD genom parallellisering

NewData är RDD nu.
-
Räkna objekt i RDD

-
Samla
Denna funktion returnerar allt RDD: s innehåll till drivrutinen. Detta är användbart vid felsökning i olika steg i skrivprogrammet.
-
Läs de första tre artiklarna från RDD

-
Spara output / bearbetade data i textfilen

Här är "output" -mappen den aktuella sökvägen.
Mellanstarka gnistkommandon
1. Filtrera på RDD
Låt oss skapa en ny RDD för objekt som innehåller "ja".

Transformationsfilter måste kallas på befintlig RDD för att filtrera på ordet "ja", vilket skapar ny RDD med den nya listan med objekt.
2. Kedjedrift

Här fungerar filtertransformation och räknehandling tillsammans. Detta kallas kedjedrift.
3. Läs det första föremålet från RDD

4. Räkna RDD-partitioner
Som vi vet är RDD tillverkad av flera partitioner, det finns behov av att räkna nej. av partitioner. Eftersom det hjälper till att ställa in och felsöka när du arbetar med gnistkommandon.

Som standard är minsta antal. pf-partition är 2.
5. gå med
Denna funktion förenar två tabeller (tabellelement är i parvis) baserat på den gemensamma tangenten. I parvis RDD är det första elementet nyckeln och det andra elementet är värdet.
6. Cache en fil
Caching är en optimeringsteknik. Caching RDD betyder att RDD kommer att ligga i minnet, och all framtida beräkning kommer att göras på dessa RDD i minnet. Det sparar diskläsningstiden och förbättrar prestandan. Kort sagt, det minskar tiden för åtkomst till data.

Men data kommer inte att cachelagras om du kör ovanför funktionen. Detta kan bevisas genom att besöka webbsidan:
http: // localhost: 4040 / lagring
RDD kommer att cachelagras när åtgärden är klar. Till exempel:

Ytterligare en funktion som fungerar som cache () är persist (). Persist ger användarna flexibilitet att ge argumentet, vilket kan hjälpa till att data cachas i minne, disk eller off-heap-minne. Persist utan några argument fungerar som cache ().
Avancerade gnistkommandon
Låt oss ta en titt på några av de avancerade gnistkommandona som ges nedan: -
-
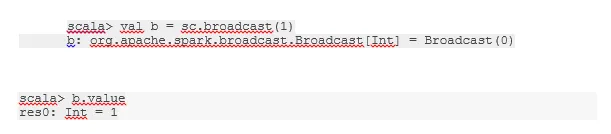
Sänd en variabel
Broadcast-variabel hjälper programmeraren att fortsätta läsa den enda variabel som är cache-cache på varje maskin i klustret, snarare än att skicka kopia av den variabeln med uppgifter. Detta hjälper till att minska kommunikationskostnaderna.
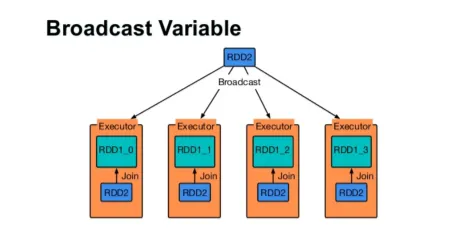
Fig 4
Google bild
Kort sagt, det finns tre huvudfunktioner i Broadcasted-variabeln:
- Oföränderlig
- Passa in i minnet
- Distribuerat över kluster
-
ackumulatorer
Ackumulatorer är de variabler som läggs till tillhörande operationer. Det finns många användningsområden för ackumulatorer som räknare, summor etc.

Namnet på ackumulatorn i koden kunde också ses i Spark UI.
-
Karta
Kartfunktion hjälper till att iterera över varje rad i RDD. Funktionen som används på kartan tillämpas på alla element i RDD.
Till exempel, i RDD (1, 2, 3, 4, 6) om vi tillämpar “rdd.map (x => x + 2)” får vi resultatet som (3, 4, 5, 6, 8).
-
Flatmap
Flatmap fungerar som kartan, men kartan returnerar bara ett element medan flatmap kan returnera listan över element. Därför behöver man dela upp meningar i ord.
-
Växa samman
Denna funktion hjälper till att undvika blandning av data. Detta tillämpas i den befintliga partitionen så att mindre data blandas. På detta sätt kan vi begränsa användningen av noder i klustret.
Tips och tricks för att använda gnistkommandon
Nedan finns de olika tips och tricks med gnistkommandon: -
- Nybörjare av Spark kan använda Spark-shell. Eftersom gnistkommandon är byggda på Scala är det definitivt bra att använda scala-gnistskal. Python-gnistskal finns emellertid också tillgängligt, så att även något man kan använda, som är välbekant med python.
- Gnistskal har många alternativ för att hantera resurserna i klustret. Under kommandot kan du hjälpa dig med det:

- I Spark är det vanliga att arbeta med långa datasätt. Men saker går fel när dåliga insatser tas. Det är alltid en bra idé att släppa dåliga rader med hjälp av filterfunktionen för Spark. Den bra uppsättningen av input kommer att vara en bra gång.
- Spark väljer en egen partition för dina data. Men det är alltid en bra praxis att hålla ett öga på partitioner innan du börjar ditt jobb. Att testa olika partitioner hjälper dig med parallelliteten i ditt jobb.
Slutsats - Gnistkommandon:
Spark-kommandot är en revolutionerande och mångsidig big data-motor som kan fungera för batchbearbetning, realtidsbearbetning, cachedata etc. Spark har en rik uppsättning av maskininlärningsbibliotek som kan göra det möjligt för datavetare och analytiska organisationer att bygga starka, interaktiva och snabba applikationer.
Rekommenderade artiklar
Detta har varit en guide till gnistkommandon. Här har vi diskuterat såväl grundläggande som avancerade gnistkommandon och några omedelbara gnistkommandon. Du kan också titta på följande artikel för att lära dig mer -
- Adobe Photoshop-kommandon
- Viktiga VBA-kommandon
- Tableau-kommandon
- Fuskark SQL (kommandon, gratis tips och trick)
- Typer av sammanfogningar i Spark SQL (exempel)
- Gnistkomponenter | Översikt och Topp 6-komponenter