

Skillnaden mellan Hadoop och HBase
Hadoop är ett öppet Java-ramverk som används för att hantera och behandla en enorm mängd strukturerad och ostrukturerad data. Hadoop är massivt skalbar och används därför för att bearbeta Big Data-arbetsbelastningar. Big data lagras, öppnas och bearbetas i det pålitliga och expanderbara klustret. HBase (Hadoop Database) är en icke-relationell och inte bara SQL, dvs. NoSQL-databas som körs på toppen av Hadoop som ett distribuerat och skalbart stordatabutik. Det är en öppen källkodsdatabas där data lagras i form av rader och kolumner, i den cellen är en korsning av kolumner och rader.
Nedan är kärnkomponenterna i Hadoop-arkitekturen:
- Hadoop Distribuerat filsystem (HDFS): Hadoop innehåller ett distribuerat lagringssystem, Hadoop Distribuerat filsystem (HDFS). HDFS är master-slavarkitekturen som lagrar data över hela klustret. Data distribueras på flera slavnoder av huvudnoden i formblocket. Huvudnoden heter Namenode och slavnoder kallas Datanode. HDFS är lätt att utöka och lagrar en enorm mängd data på Datanodes. HDFS har en konfigurerbar replikeringsfaktor med standardvärde 3 som kan redigeras.
- MapReduce: MapReduce är ett programmeringsparadigm, som processar parallellt på ett stort antal datasätt över nätverket. MapReduce hänvisar till två olika uppgifter: kartlägga inmatningsdata där data delas in i en deluppsättning data som kallas tuples och reducera uppgiften tar dessa tuples från kartan som input och kombineras för att bilda utgången från originalet.
- Garn: YARN står för Ytterligare en resursnavigator som beräknar resurser som hanterar CPU och minne, schemaläggning av resursförfrågningar.
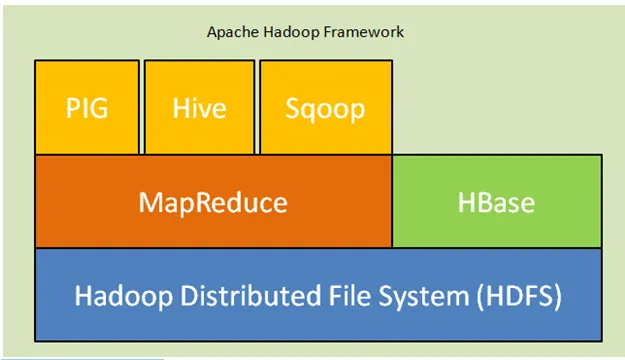
Fig. Apache Hadoop Framework
Regionservern serverar data för läsning / skrivning. All HBas-data lagras i HDFS-filen. HDFS Datanode lagrar data som Regionservern hanterar. HDFS Namenode behåller metadatainformation för alla fysiska datablock som innehåller filerna.
Versionering används för att spåra celländringar, vilket håller spåret med innehållsversionen. Från det kan alla versioner av innehåll hämtas. Varje cellvärde innehåller attributet 'version' med avseende på tidsstämpeln för att hämta cellen. Varje värde på kartan är en oavbruten grupp av byte. Kartan indexeras av en radtangent, kolumnnyckel och en tidsstämpel. Arkitekturen för HBase är mycket skalbara, glesa, distribuerade, ihållande och flerdimensionella sorterade kartor.
Jämförelse mellan Head och Head mellan Hadoop vs HBase (Infographics)
Nedan visas topp 7 skillnaden mellan Hadoop vs HBase
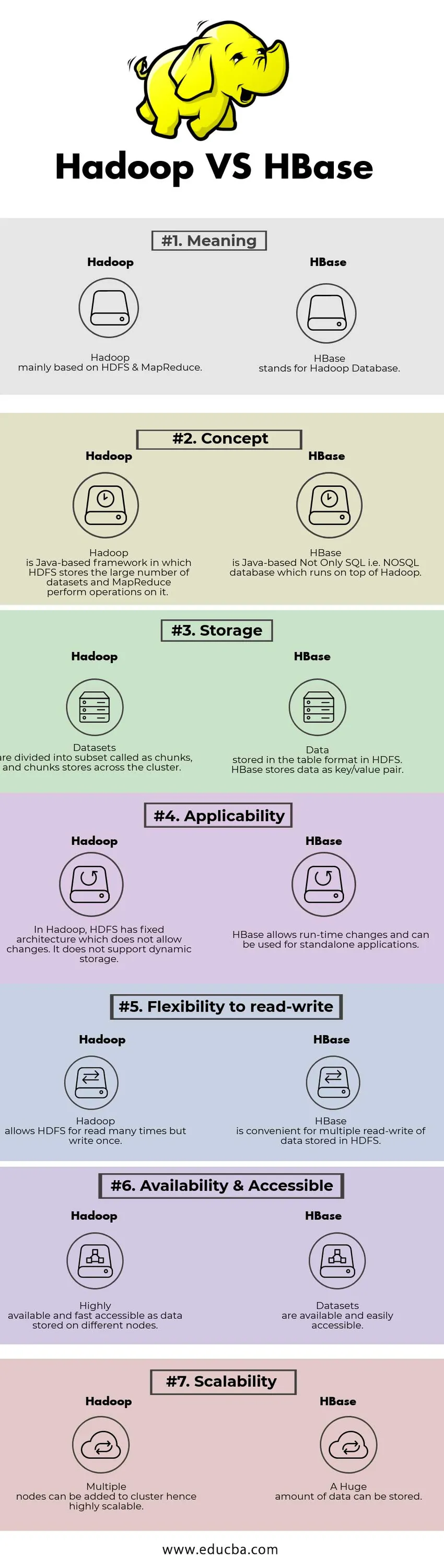
Viktiga skillnader mellan Hadoop vs HBase
Skillnaden mellan Hadoop och HBase förklaras i punkterna som presenteras nedan:
- Hadoop är inte lämplig för online analytisk bearbetning (OLAP) och HBase är en del av Hadoop ekosystem som ger slumpmässig realtidsåtkomst (läs / skriv) till data i Hadoop filsystem.
- Hadoop-ramverket är feltolerant av design och stöder snabb dataöverföring mellan noder även vid systemfel. HBase är en icke-relationell och open source Not-Only-SQL-databas som kör ovanpå Hadoop. HBase tillhör CP-typen CAP (konsistens, tillgänglighet och partitionstolerans) teorem.
- Hadoop är bäst lämpad för att utföra batchanalys. En av dess största nackdelar är emellertid dess oförmåga att utföra realtidsanalys, IT-branschens trendkrav. HBase, å andra sidan, kan hantera stora datamängder och är inte lämpligt för batchanalys. Istället används den för att skriva / läsa data från Hadoop i realtid.
- Både Hadoop och HBase kan bearbeta strukturerade, semistrukturerade och ostrukturerade data. I Hadoop saknar HDFS en in-minne-bearbetningsmotor som bromsar processen för dataanalys; eftersom den använder vanlig gammal MapReduce för att göra det. HBase, tvärtom, skryter med en processor i minnet som drastiskt ökar hastigheten för läsning / skrivning.
- Hadoop är mycket transparent när det gäller att utföra dataanalys. HBase å andra sidan, som en NoSQL-databas i tabellformat, hämtar värden genom att sortera dem under olika nyckelvärden.
Hadoop vs HBase jämförelsetabell
| GRUND FÖR Jämförelse | Hadoop | HBase |
| Menande | Hadoop huvudsakligen baserat på HDFS & MapReduce. | HBase står för Hadoop Database. |
| Begrepp | Hadoop är ett Java-baserat ramverk där HDFS lagrar det stora antalet datasätt och MapReduce utför operationer på det. | HBase är Java-baserad Not Only SQL, dvs. NoSQL-databas som körs ovanpå Hadoop. |
| Lagring | Datauppsättningar är indelade i delmängder som kallas bitar och bitar butiker över hela klustret. | Data lagrade i tabellformatet i HDFS. HBase lagrar data som nyckel- / värdepar. |
| Tillämplighet | I Hadoop har HDFS fast arkitektur som inte tillåter förändringar. Det stöder inte dynamisk lagring. | HBase tillåter förändringar av driftstid och kan användas för fristående applikationer. |
| Flexibilitet för att läsa-skriva | Hadoop tillåter HDFS att läsa många gånger men skriva en gång. | HBase är bekvämt för flera lässkrivningar av data lagrade i HDFS |
| Tillgänglighet & tillgängligt | Mycket tillgängligt och snabbt tillgängligt som data lagrade på olika noder. | Datasätt är tillgängliga och lättillgängliga |
| skalbarhet | Flera noder kan läggas till i kluster och därmed mycket skalbara. | En enorm mängd data kan lagras. |
Slutsats - Hadoop vs HBase
Hadoop-arkitektur baserad huvudsakligen på HDFS och MapReduce. HBase är den stödjande komponenten i Hadoop-systemet. HBase kan värd enorma tabeller och ger snabb slumpmässig åtkomst till tillgängliga data medan HDFS är lämpligt för att lagra stora filer. Både Hadoop och HBase ger snabb åtkomst till data men med HBase kan läs / skrivoperationer utföras och för HDFS läsas många gånger och en gång kan skrivning utföras. Den här artikeln beskrev en förståelse av Hadoop och HBase, kort markerade funktioner och jämförs klokt.
Rekommenderad artikel
- Apache Hadoop vs Apache Spark | Topp 10 jämförelser du måste känna till!
- Hadoop vs Hive - Ta reda på de bästa skillnaderna
- HBase vs Cassandra - Vilken som är bättre (Infographics)
- Topp 12 jämförelse av Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Spark: Vilka är funktionerna?