

Hur man installerar Apache
Innan vi skriver in hur du installerar Apache-delen skulle vi först ha en allmän översikt över Apache och hur den används i datavetenskap.
Vad är Apache?

Apache Web Server är en HTTP-server som presenterar webbplatser för besökare som kommer till din server. Så om du vill distribuera en webbplats för ett företag eller din organisation, skulle du troligtvis använda Apache för det.
Det finns andra HTTP-servrar där ute, till exempel IIS, men Apache är den standard som de flesta använder, oavsett om de är på Linux, Windows eller Mac. Apache är standard som de flesta går till eftersom det är välkänt, det är väldigt pålitligt och det är gratis.
En sak att inse med Apache är emellertid att eftersom det är en HTTP-server, så om du installerar detta på Linux eller Windows eller Mac så skulle allt du kan göra är att presentera statiska webbplatser för besökare som kommer till din server. Därför, om du kodar ut en HTML-webbplats utan några ytterligare programmeringsspråk än JavaScript, kan du använda den med bara en Apache-server. Du kan ansluta alla dina taggar till Apache-servern och presentera dem för dina besökare.
Hur använde Apache i datavetenskap?
Data Science är det mest efterfrågade studiefältet i den moderna världen. Data Scientist betraktas som det sexigaste jobbet på 2000-talet med professionella från olika discipliner som vill lära sig och bli en Data Scientist. Apache spelar en avgörande roll för alla datavetenskapliga entusiaster, eftersom de behöver tillräcklig kunskap om Apache Hadoop ekosystem.
Apache Hadoop ekosystem
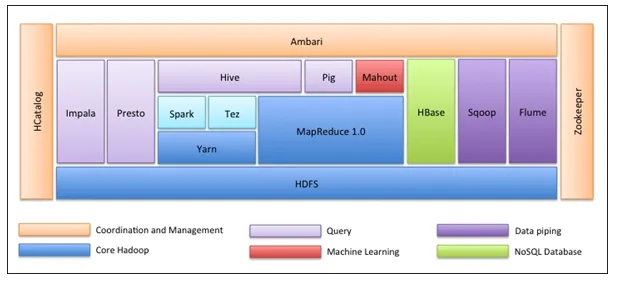
Det allra första är Hadoop Ecosystem är inte ett verktyg. Det är inte ett programmeringsspråk eller ett enda ramverk. Det är en grupp verktyg som används tillsammans av olika företag inom olika domäner för flera uppgifter. Vi kommer att gå igenom varje verktyg en efter en nedan: -
- Apache HDFS (Hadoop Distribuerat filsystem) är lagringsenheten för Hadoop som kan lagra strukturerade, halvstrukturerade och ostrukturerade data. HDFS har metadata som underhåller loggfilen om lagrad data. Den har två komponenter - NameNode och DataNode.
- Apache Yarn är resursförhandlaren som utför alla bearbetningsaktiviteter som schemaläggningsuppgifter, fördelning av resurser osv. Det har två tjänster - För det första är Resurshanteraren som schemaläggar program som körs ovanpå Yarn. För det andra är Node Manager som övervakar resursutnyttjandet .
- Apache Map Reduce är databehandlingskomponenten i Hadoop som bearbetar stora datasätt med distribuerad och parallell databehandling baserad på Map, Sort and Shuffle och Reduce-funktioner. Kartfunktionen filtrerar data, sedan sorteras och blandas och i slutet Minskar funktionsaggregat och sammanfattar resultatet.
- Apache Pig används mest i ETL. Den har två delar - Pig Latin och Pig runtime. Pig Latin är det språk som används för databehandling med hjälp av en fråga, medan grisen är körmiljön. En rad gris-latin är nästan lika med 100 rader med kartminskningskod. Processen innebär först att ladda data och sedan gruppera, sortera, filtrera och lagra dem i HDFS.
- Apache Hive använder en SQL-liknande fråga för att analysera data i en distribuerad miljö. Den har två komponenter - Hive-kommandoraden och JDBC / ODBC-servern och det använda språket kallas HiveQL.
- Apache Mahout är Machine Learning-biblioteket skrivet i Java och används för att skapa applikationer för maskininlärning som kluster, klassificering eller regression. Den har olika algoritmer inbyggda för olika användningsfall.
- Apache HBase är en NoSQL-databas skriven i Java som går över Hadoop. Det är byggt baserat på Googles BigTable och kan hantera alla typer av data.
- Apache Sqoop är ett dataintagningsverktyg som används för bulkstrukturerad dataöverföring mellan RDBMS och Hadoop.
- Apache Flume är ett annat dataintagningsverktyg som används för semistrukturerad och ostrukturerad dataöverföring mellan Hadoop och andra datakällor.
- ZooKeeper är samordnaren som säkerställer samordning mellan olika verktyg i Hadoop-ekosystemet.
- Apache Ambari är en Cluster Manager som försörjer, hanterar Hadoop-kluster och övervakar också deras hälsa och status.
- Apache Tez är ett nytt verktyg i Hadoop-ekosystemet som påskyndar Hadoops frågebehandling.
- Apache Presto är en öppen källdistribuerad SQL-frågemotor som möjliggör en frågefunktion mellan plattformar.
- Apache HCatalog är ett metadata- och tabellhanteringssystem för Hadoop som möjliggör interoperabilitet mellan databehandlingsverktyg. Det hjälper också användare att välja de bästa verktygen för sina miljöer.
- Apache Spark är den mest använda och populära ramen bland Data Scientist. Det är ett höghastighetsklusterdatasystem som optimerar resursutnyttjandet vid många iterativa uppgifter. Det ger flexibilitet för både batchbehandling och realtidsdataanalys.
Nedan följer stegen för att installera Apache
Hittills har vi lärt oss om Apache och hur det är användbart för alla som vill lära sig Data Science eller Big Data Analytics. Nu ska vi dyka ner och installera apache i Windows baserat på stegen nedan.
- Gå till https://httpd.apache.org/ och klicka på länken Hämta under Apache httpd 2.4.38 Released-avsnitt.

- Den tar dig till följande sida och klickar sedan på Filer för Microsoft Windows.
- Klicka på Apache Lounge.

- Du kan ladda ner 32-bitars eller 64-bitars av zip-filen baserat på ditt Windows-operativsystem. Vi kommer att ladda ner 64-bitarsversion här. Klicka på motsvarande .zip-länk för att ladda ner.

- Nu kräver det C ++ Redistributable Visual Studio 2017. Så vi kommer att ladda ner den från motsvarande 32-bitars eller 64-bitarslänk

- När båda filerna har laddats ner kommer vi att ladda ner den nedladdade platsen och installera C ++ Redistributable Visual Studio 2017 först. Dubbelklicka på .exe-filen.

- Markera "Jag accepterar" och klicka på Installera.

- Installationen av Apache pågår.
- När den är klar får du ett meddelande som det här. Klicka på Stäng för att slutföra installationen.
- Gå nu till mappen där du laddar ner zip-filen Apache. Högerklicka på den och välj extrakt här.
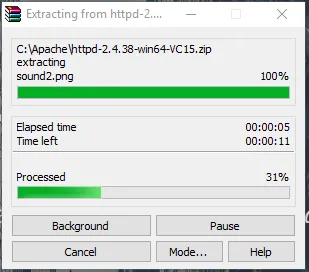
- Nu kommer vi att skapa en Apache24-mapp. Kopiera den här mappen till C-enhet och sedan lägger vi till en sökväg till systemmiljövariabler.
Gå till Systemegenskaper -> Fliken Avancerat -> Klicka på knappen Miljövariabler nedan.
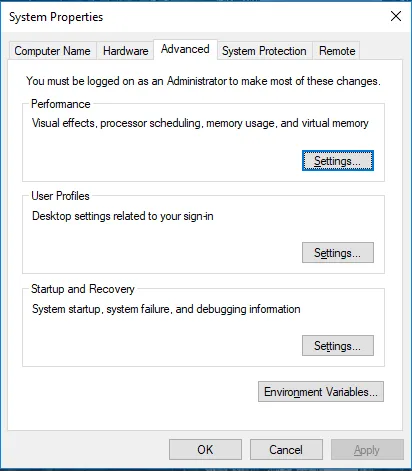
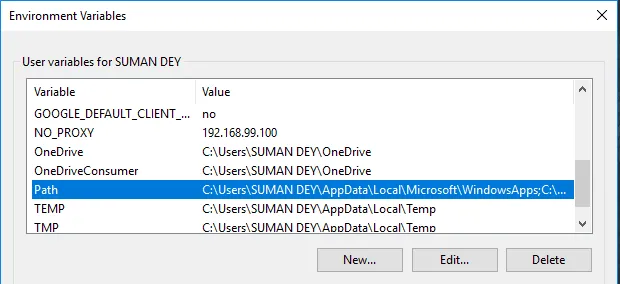
- I Variabler, hitta sökväg och klicka på Redigera.
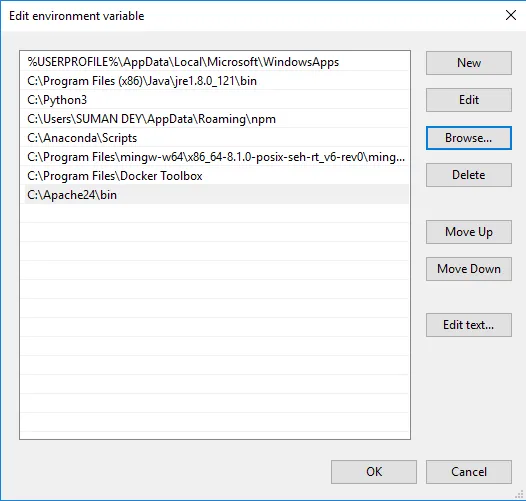
- Klicka på Bläddra -> Gå till C-enhet Apache24-mappen -> Välj papperskorg -> Klicka på Ok.
- Vi kommer att installera Apache som en Windows-tjänst. Kör kommandotolken som administratör. Skriv httpd –k installera och tryck på enter.
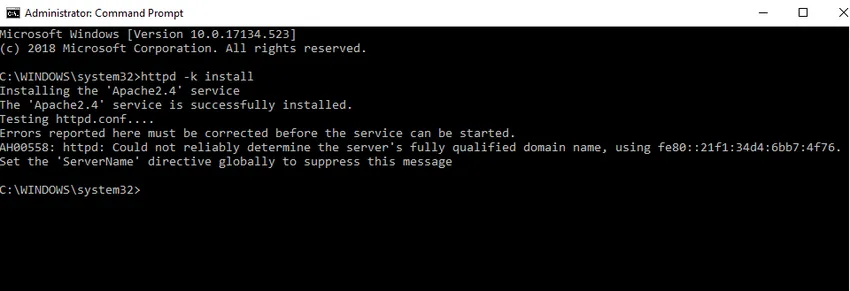
- Vi kontrollerar installationen av Apache-tjänsten. Klicka på Windows-ikonen och skriv tjänster. Klicka på appen Tjänster och hitta tjänster med namnet Apache24.

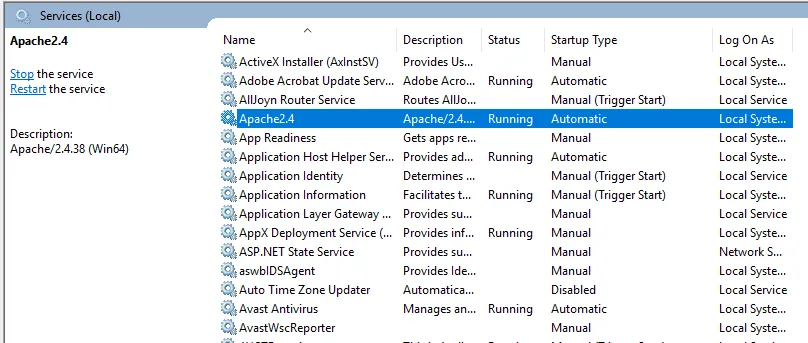
- För att starta Apache-servern, högerklicka på den och klicka på Start. Status kommer att ändras till 'Running'.
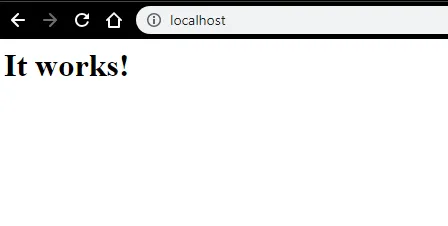
- Vi kan testa med en webbläsare. Öppna en webbläsare och navigera till http: // localhost och tryck på enter. Ett meddelande om "Det fungerar!" kommer att dyka upp för att bekräfta en framgångsrik installation av Apache.
Rekommenderade artiklar
Detta har varit en guide för hur du installerar Apache. Här har vi diskuterat instruktionerna och olika steg för att installera Apache. Du kan också titta på följande artikel för att lära dig mer -
- Apacheintervjufrågor
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Topp skillnader