
Introduktion till AWS Data Pipeline
Data växer exponentiellt dag för dag och blir svåra att hantera jämfört med tidigare. Vi behöver verktyg och tjänster för att hantera våra data effektivt och till en billigare kostnad, det är där AWS Data Pipeline kommer i åtanke. Det handlar inte bara om att lagra data, utan du måste analysera, bearbeta, omvandla data till önskad form på samma plats, allt detta kan uppnås med AWS Data Pipeline.
Behov av datapipeline
Låt oss försöka förstå behovet av datapipeline med exemplet:
Exempel 1
Vi har en webbplats som visar bilder och gifs på grundval av användarsökningar eller filter. Vårt primära fokus är att servera innehåll. Det finns vissa mål att uppnå som är följande:
- Förbättrad leverans av innehåll: Servera vad användare vill ha effektivt och snabbt nog.
- Hantera applikationen effektivt: Lagra användardata och webbplatsloggar för senare analysändamål.
- Förbättra verksamheten: Att använda lagrade data och analys tar beslutet att göra affärer bättre till en billigare kostnad.
Exempel 2
Det finns vissa flaskhalsar som ska tas om hand för att uppnå målen:
- Den enorma mängden data i olika format och på olika platser som gör bearbetning, lagring och migrering av data komplex.
Olika datalagringskomponenter för olika typer av data:
- Möjlig realtidsdata för registrerade användare: Dynamo DB .
- Webb-serverloggar för potentiella användare: Amazon S3 .
- Demografidata och inloggningsuppgifter: Amazon RDS.
- Sensordata och tredjepartsdatasats: Amazon S3.
lösningar
- Genomförbar lösning: Vi kan se att vi måste ta itu med olika typer av verktyg för att konvertera data från ostrukturerad till strukturerad för analys. Här måste vi använda olika verktyg för att lagra data och igen för att konvertera, analysera och lagra bearbetade data. Inte en kostnadseffektiv lösning.
- Optimal lösning: Använd en datapipeline som hanterar behandling, visualisering och migrering. Datapipeline kan vara användbar vid migrering av data från olika platser, också analysera data och bearbetning på samma plats för dina räkning.
Vad är AWS-datapipeline?
AWS Data Pipeline är i grunden en webbtjänst som erbjuds av Amazon som hjälper dig att transformera, bearbeta och analysera dina data på ett skalbart och tillförlitligt sätt samt lagra bearbetade data i S3, DynamoDb eller din lokala databas.
- Med AWS Data Pipeline kan du enkelt komma åt data från olika källor.
- Transformera och bearbeta dessa data på skalan.
- Effektiv överföring av resultat till andra tjänster som S3, DynamoDb-tabell eller lokal datalager.
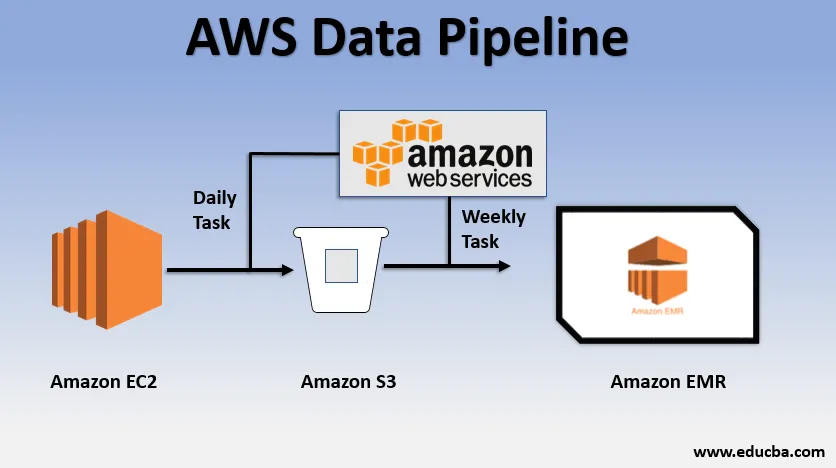
Grundläggande användningsexempel på dataledningen
- Vi kan ha en webbplats distribuerad via EC2 som genererar loggar varje dag.
- En enkel daglig uppgift kan kopieras loggfiler från E2 och uppnå dem till S3-hinken.
- En veckovis uppgift kan vara att bearbeta data och starta dataanalys över Amazon EMR för att generera veckorapporter på grundval av all insamlad data.
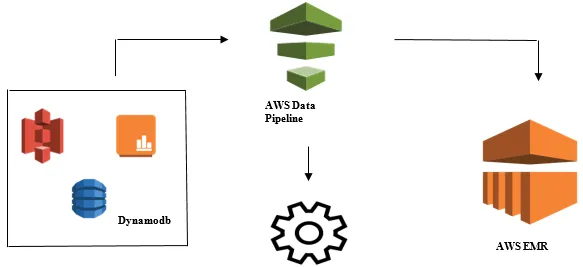
Lansering av dataanalys med AWS-datapipeline
- Insamling av data från olika datakällor som - S3, Dynamodb, Lokala, sensordata etc.
- Utför transformation, bearbetning och analys på AWS EMR för att generera veckovis rapporter.
- Veckorapport sparad i Redshift, S3 eller lokal databas.
Fördelarna med AWS Data Pipeline
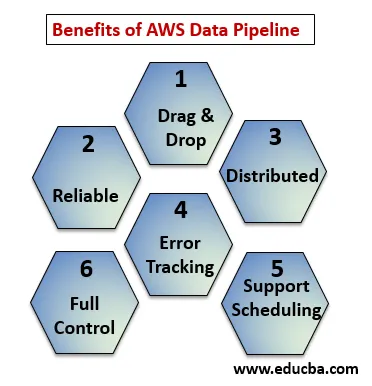
Nedanför punkterna förklarar fördelarna med AWS Data Pipeline:
- Dra och släpp konsol som är lätt att förstå och använda.
- Distribuerad och tillförlitlig infrastruktur: Dataledningar körs på skalbara tjänster och är tillförlitliga om något fel eller uppgift misslyckas kan det ställas in för att försöka igen.
- Stöder schemaläggning och felspårning: Du kan schemalägga dina uppgifter och spåra dem vad som har misslyckats och framgång.
- Distribuerad: Kan köras parallellt på flera maskiner eller på linjärt sätt.
- Full kontroll över beräkningsresurser som EC2, EMR-kluster.
AWS Data Pipeline Components
Nedan finns komponenterna i AWS Data Pipeline:
1. Rörledningsdefinition
Konvertera din affärslogik till AWS Data Pipeline.
- Datanoder : Innehåller namn, plats, datakällans format det kan vara (S3, dynamodb, lokalt)
- Aktiviteter : Flytta, omvandla eller utföra frågor på dina data.
- Schema : Planera dina dagliga eller veckovisa aktiviteter.
- Förvillkor : Villkor som startar schemaläggaren kontrollerar datatillgänglighet vid källan.
- Resurser : Beräkna resurser EC2, EMR.
- Åtgärder : Uppdatering om datapipeline, skicka aviseringar, trigglarm.
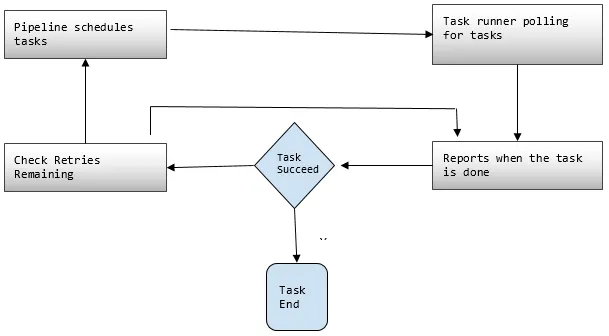
2. Rörledningar
Här planerar du och kör uppgifterna för att utföra definierade aktiviteter.
- Pipeline C omponents: Pipeline-komponenter är desamma som komponenterna i Pipeline-definitionen.
- Instanser: Under körning av uppgifter sammanställer AWS alla komponenter för att skapa vissa handlingsbara instanser. Sådana fall har all information om specifika uppgifter.
- Försök: Vi har redan diskuterat hur tillförlitlig datapipeline är med sina försöksmekanismer. Här ställer du in hur många gånger du vill prova uppgiften igen om den misslyckas.
3. Uppdragslöpare
Frågar eller undersöker uppgifter från AWS Data Pipeline och utför sedan dessa uppgifter.
AWS Data Pipeline Pricing
Nedanför punkterna förklarar AWS Data-pipeline-prissättning:
1. Gratis nivå
Du kan komma igång med AWS Data Pipeline gratis som en del av AWS gratis användningsnivå. Nya anmälningskunder får varje månad några gratisförmåner under ett år:
- 3 Förutsättningar för lågfrekvens som körs på AWS utan laddning.
- 5 Aktiviteter med lågfrekvens som körs på AWS utan kostnad.
2. Låg frekvens
Låg frekvens är tänkt att köra en gång på en dag eller mindre. Datapipeline följer samma faktureringsstrategi som andra AWS-webbtjänster, dvs faktureras för din användning. Det tas ut hur ofta dina uppgifter, aktiviteter och förutsättningar körs varje dag och var de körs (AWS eller lokalt). Högfrekventa aktiviteter är schemalagda att köras mer än en gång om dagen.
Exempel: Vi kan schemalägga en aktivitet som ska köras varje timme och bearbeta webbplatsloggarna eller så kan det vara var 12: e timme. Medan lågfrekventa aktiviteter är de som körs en gång om dagen eller mindre om förutsättningarna inte är uppfyllda. Inaktiva rörledningar har antingen inaktiva, väntande och Färdiga tillstånd.
3. Prissättning av AWS-datapipeline visas Regionvis
Region nr 1: USA : s öst (N.Virginia), USA: s väst (Oregon), Asien och Stilla havet (Sydney), EU (Irland)
| Hög frekvens | Låg frekvens | |
| Aktiviteter eller förutsättningar som går över AWS | $ 1, 00 per månad | 0, 06 $ per månad |
| Aktiviteter eller förutsättningar som körs på plats | $ 2, 50 per månad | $ 1, 50 per månad |
| Inaktiva rörledningar: $ 1, 00 per månad |
Region nr 2: Asien och Stilla havet (Tokyo)
| Hög frekvens | Låg frekvens | |
| Aktiviteter eller förutsättningar som går över AWS | $ 0, 9524 per månad | $ 0, 5715 per månad |
| Aktiviteter eller förutsättningar som körs på plats | 2, 381 $ per månad | 1, 4286 $ per månad |
| Inaktiva rörledningar: $ 0, 9524 per månad |
Rörledningen som ett dagligt jobb dvs en lågfrekvensaktivitet på AWS för att flytta data från DynamoDB-tabellen till Amazon S3 skulle kosta $ 0, 60 per månad. Om vi lägger till EC2 för att producera en rapport baserad på Amazon S3-data, skulle den totala pipeline-kostnaden vara $ 1, 20 per månad. Om vi kör denna aktivitet var sjätte timme kostar det $ 2, 00 per månad, för då skulle det vara en högfrekvent aktivitet.
Slutsats
AWS Data Pipeline är en mycket praktisk lösning för att hantera exponentiellt växande data till en billigare kostnad. Det är väldigt pålitligt och skalbart enligt din användning. För alla affärsbehov där det handlar om en stor mängd data är AWS Data Pipeline ett mycket bra val för att nå alla våra affärsmål.
Rekommenderade artiklar
Detta är en guide till AWS Data Pipeline. Här diskuterar vi behoven hos datapipeline, vad är AWS datapipeline, dess komponent- och prissättningsdetaljer. Du kan också gå igenom våra andra relaterade artiklar för att lära dig mer -
- AWS EBS
- AWS-databaser
- Vad är AWS EC2?
- Fördelarna med datavisualisering
- Topp 7 konkurrenter av AWS med funktioner
- Lär dig listan över Amazon Web Services-funktioner