
Introduktion till förstärkningslärande
Förstärkningslärande är en typ av maskininlärning och därför är det också en del av artificiell intelligens, när de tillämpas på system utför systemen steg och lärande baserat på resultatet av steg för att uppnå ett komplext mål som sätts för systemet att uppnå.
Förstå förstärkningslärande
Låt oss försöka under arbetet med förstärkningslärande med hjälp av två fall med enkel användning:
Fall 1
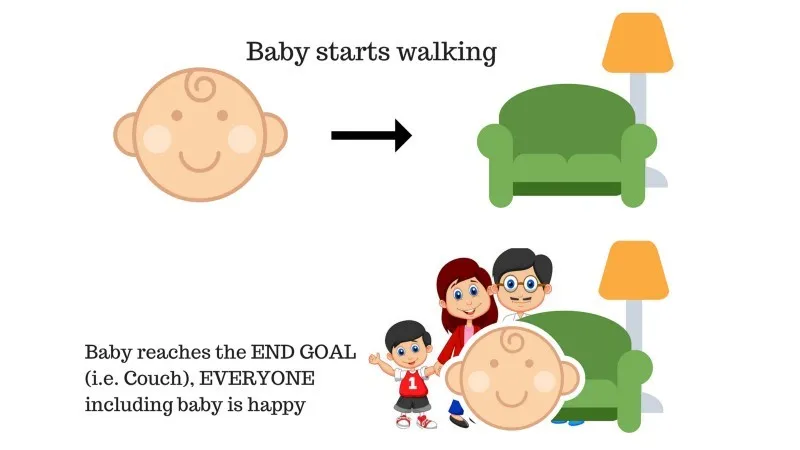
Det finns en baby i familjen och hon har precis börjat gå och alla är ganska nöjda med det. En dag försöker föräldrarna att sätta sig ett mål, låt oss barnet nå soffan och se om barnet kan göra det.
Resultat av fall 1: Barnet når framgångsrikt soffan och därför är alla i familjen mycket glada över att se detta. Den valda vägen kommer nu med en positiv belöning.
Poäng: Belöning + (+ n) → Positiv belöning.
Källa: https://images.app.goo.gl/pGCXJ1N1bzLAer126
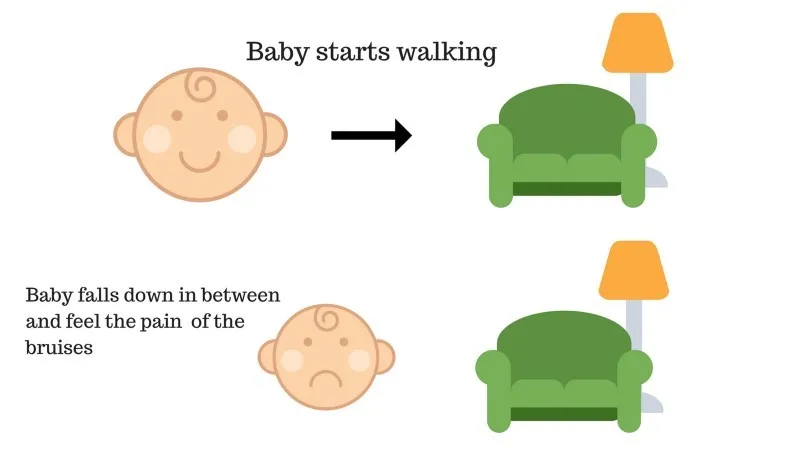
Fall nr 2
Barnet kunde inte nå soffan och barnet har fallit. Det gör ont! Vad kan vara orsaken? Det kan finnas några hinder i vägen till soffan och barnet hade fallit till hinder.
Resultat av fall 2: Barnet faller på några hinder och hon gråter! Åh, det var dåligt, lärde hon sig, att inte falla i hinderfällan nästa gång. Den valda vägen kommer nu med en negativ belöning.
Poäng: Belöningar + (-n) → Negativ belöning.
Källa: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Detta har vi nu sett fall 1 och 2, förstärkningslärande, i koncept, gör detsamma förutom att det inte är mänskligt utan istället utförs beräkningsbart.
Använd förstärkning stegvis
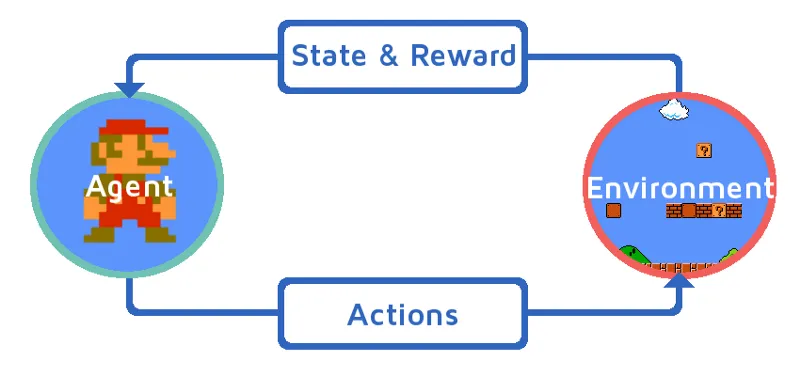
Låt oss förstå förstärkningsinlärningen genom att föra ett förstärkningsagent på ett stegvis sätt. I det här exemplet är vår förstärkningsinlärningsagent Mario, som kommer att lära sig att spela på egen hand:
Källa: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Det nuvarande läget för Mario-spelmiljön är S_0. Eftersom spelet ännu inte har startat och Mario är på sin plats.
- Därefter startas spelet och Mario rör sig, Mario dvs. RL-agenten tar och agerar, låt oss säga A_0.
- Nu har spelmiljöns status blivit S_1.
- Dessutom har RL-agenten, dvs Mario nu tilldelats någon positiv belöningspunkt, R_1, troligen för att Mario fortfarande lever och det inte fanns någon fara.
Nu kommer slingan ovan att fortsätta köra tills Mario slutligen är död eller Mario når sin destination. Denna modell kommer kontinuerligt att visa åtgärden, belöningen och tillståndet.
Maximeringsbelöningar
Målet med förstärkning av inlärningen är att maximera belöningen genom att ta hänsyn till vissa andra faktorer som belöningsrabatten; Vi kommer snart att förklara vad som menas med rabatten med hjälp av en illustration.
Den kumulativa formeln för rabatterade belöningar är som:
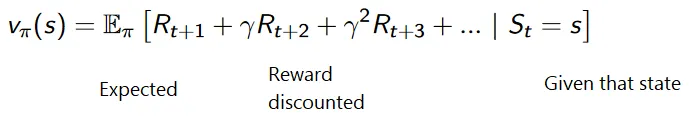
Rabattbelöningar
Låt oss förstå detta genom ett exempel:
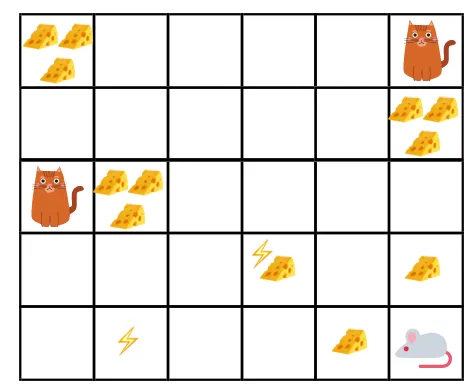
- I den givna figuren är målet att musen i spelet måste äta lika mycket ost innan de äts av en katt eller utan att bli elektrosjockad.
- Nu kan vi anta att ju närmare vi är katten eller den elektriska fällan, desto större sannolikhet gör vi för att musen blir ätad eller chockad.
- Detta innebär att även om vi har full ost nära elstötblocket eller nära katten, desto riskanterare är det att åka dit, är det bättre att äta osten som är i närheten för att undvika risk.
- Så även om vi har ett "block1" med ost som är fullt och är långt ifrån katten och elektriska chockblocket och den andra ett "block2", som också är full men som antingen är nära till katt eller elektrisk chock block, kommer det senare ostblocket, dvs "block2" att vara mer rabatterat i belöningar än det föregående.
Källa: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Källa: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Typer av förstärkningslärande
Nedan finns de två typerna av förstärkningslärande med sina fördelar och nackdelar:
1. Positiv
När styrkan och frekvensen i beteendet ökar på grund av förekomsten av något speciellt beteende, kallas det Positive Reinforcement Learning.
Fördelar: Prestandan maximeras och förändringen kvarstår under längre tid.
Nackdelar: Resultaten kan minskas om vi har för mycket förstärkning.
2. Negativt
Det är en förstärkning av beteende, mest på grund av att den negativa termen försvinner.
Fördelar: Beteendet ökar.
Nackdelar: Endast modellens lägsta beteende kan nås med hjälp av negativt förstärkningslärande.
Var förstärkningslärande bör användas?
Saker som kan göras med förstärkningslärande / exempel. Följande är de områden där förstärkningslärande används idag:
- Sjukvård
- Utbildning
- Spel
- Datorsyn
- Företagsledning
- Robotics
- Finansiera
- NLP (Naturligt språkbearbetning)
- Transport
- Energi
Karriärer i förstärkningslärande
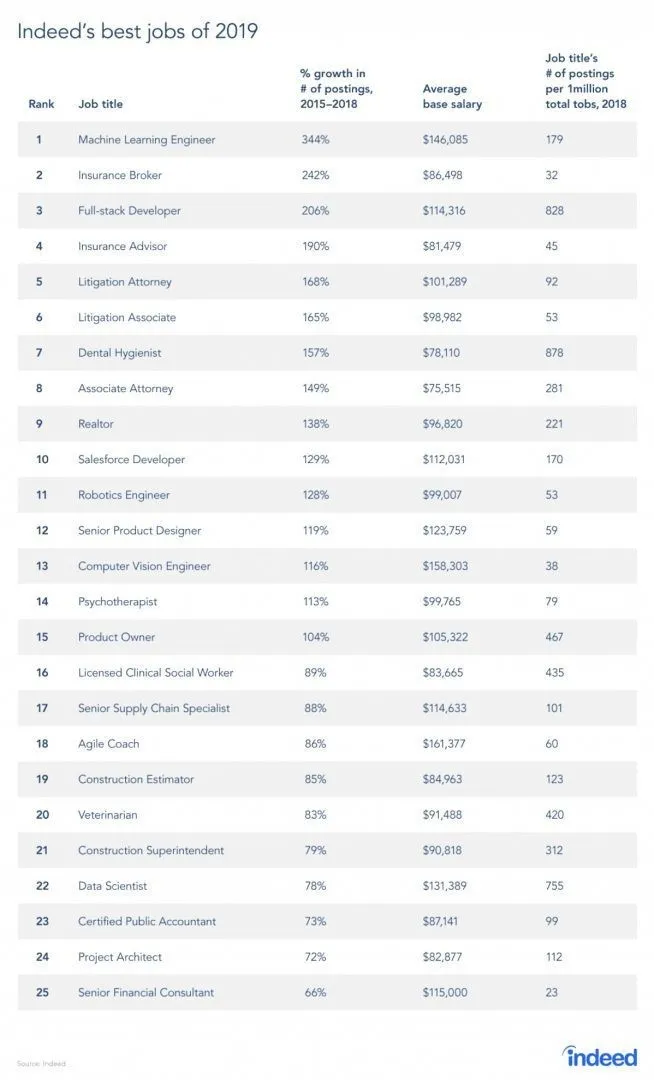
Det finns en rapport från jobbsidan verkligen, eftersom RL är en gren av maskininlärning, enligt rapporten är maskininlärning det bästa jobbet för 2019. Nedan visas ögonblicksbilden av rapporten. Enligt de nuvarande trenderna kommer en maskininlärningsingenjör med en enorm genomsnittslön på $ 146.085 och med en tillväxttakt på 344 procent.
Källa: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Färdigheter för förstärkning av lärande
Nedan följer de färdigheter som krävs för att förstärka inlärning:
1. Grundläggande färdigheter
- Sannolikhet
- Statistik
- Datamodellering
2. Programmeringsfärdigheter
- Grunder för programmering och datavetenskap
- Design av programvara
- Kunna tillämpa Machine Learning-bibliotek och algoritmer
3. Programmeringsspråk för maskininlärning
- Pytonorm
- R
- Det finns även andra språk där maskininlärningsmodeller kan utformas som Java, C / C ++ men Python och R är de mest gynnade språken som används.
Slutsats
I den här artikeln började vi med en kort introduktion om förstärkningslärande, och sedan djupt djupt i arbetet med RL och olika faktorer som är involverade i arbetet med RL-modeller. Sedan hade vi lagt några exempel i verkligheten för att förstå ännu bättre om ämnet. I slutet av denna artikel bör man ha en god förståelse för arbetet med förstärkningslärande.
Rekommenderade artiklar
Detta är en guide till Vad är förstärkningslärande ?. Här diskuterar vi funktionen och olika faktorer som är involverade i utvecklingen av modeller för förstärkning av lärande, med exempel. Du kan också gå igenom våra andra relaterade artiklar för att lära dig mer -
- Typer av maskininlärningsalgoritmer
- Introduktion till artificiell intelligens
- Artificiell intelligensverktyg
- IoT-plattformen
- Topp 6 maskininlärningsprogrammeringsspråk