
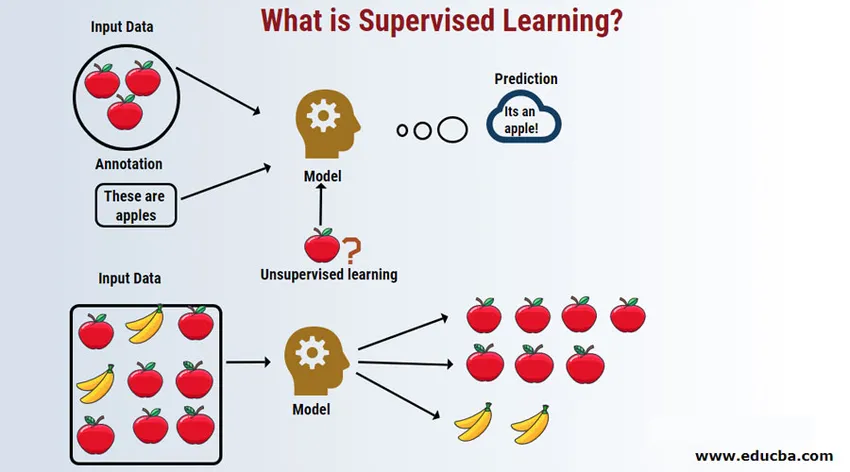
Introduktion till Supervised Learning
Supervised Learning är ett område inom maskininlärning där vi arbetar med att förutsäga värdena med hjälp av märkta datasätt. De märkta inputdatasätten kallas den oberoende variabeln medan de förutsagda resultaten kallas den beroende variabeln eftersom de beror på den oberoende variabeln för deras resultat. Till exempel har vi alla skräppostmappar i vårt e-postkonto (till exempel Gmail) som automatiskt upptäcker de flesta skräppostmeddelanden för dig med noggrannhet mer än 95%. Det fungerar baserat på en övervakad inlärningsmodell där vi har en utbildningsuppsättning med märkta data, som i detta fall är märkt skräppost som flaggas av användare. Dessa träningsuppsättningar används för att lära sig som senare kommer att användas för kategorisering av nya e-postmeddelanden som skräppost om det passar kategorin.
Arbetar med övervakad maskininlärning
Låt oss förstå övervakad maskininlärning med hjälp av ett exempel. Låt oss säga att vi har fruktkorg som är fylld med olika arter av frukt. Vårt jobb är att kategorisera frukt baserat på deras kategori.
I vårt fall har vi övervägt fyra typer av frukt och de är äpplen, bananer, druvor och apelsiner.
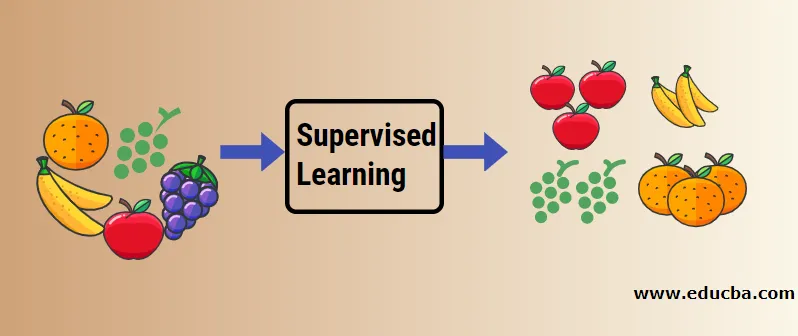
Nu kommer vi att försöka nämna några av de unika egenskaperna hos dessa frukter som gör dem unika.
|
S Nej | Storlek | Färg | Form |
Förnamn |
|
1 | Små | Grön | Rund till oval, gruppformad cylindrisk |
Druva |
|
2 | Stor | Röd | Rundad form med en fördjupning i toppen |
Äpple |
|
3 | Stor | Gul | Lång böjd cylinder |
Banan |
| 4 | Stor | Orange | Rundad form |
Orange |
Låt oss nu säga att du har plockat upp en frukt från fruktkorgen, du tittade på dess funktioner, till exempel dess form, storlek och färg till exempel och sedan drar du att färgen på denna frukt är röd, storleken om stor, formen är avrundad form med depression i toppen, därför är det ett äpple.
- På samma sätt gör du samma sak för alla andra återstående frukter också.
- Den högsta kolumnen ("Fruit Name") kallas svarsvariabeln.
- Så här formulerar vi en övervakad inlärningsmodell, nu kommer det att vara ganska enkelt för alla nya (Låt oss säga en robot eller en främmande) med givna egenskaper för att enkelt gruppera samma typ av frukt ihop.
Typer av övervakad maskininlärningsalgoritm
Låt oss se olika typer av maskininlärningsalgoritmer:
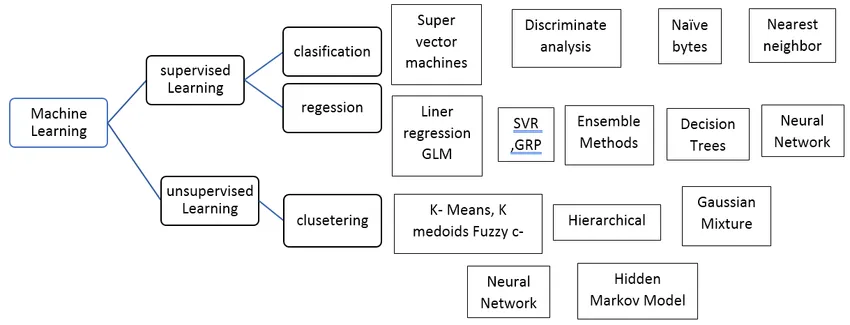
regression:
Regression används för att förutsäga utgång av ett enda värde med hjälp av träningsdatauppsättningen. Utgångsvärdet kallas alltid som den beroende variabeln medan ingångarna kallas den oberoende variabeln. Vi har olika typer av regression i Supervised Learning, till exempel,
- Linjär regression - Här har vi bara en oberoende variabel som används för att förutsäga utgången, dvs beroende variabel.
- Multipel regression - Här har vi mer än en oberoende variabel som används för att förutsäga utgången, dvs den beroende variabeln.
- Polynomregression - Här följer grafen mellan de beroende och oberoende variablerna en polynomfunktion. För t.ex. till en början ökar minnet med åldern, sedan når det en tröskel vid en viss ålder och sedan börjar det minska när vi blir gamla.
Klassificering:
Klassificeringen av övervakade inlärningsalgoritmer används för att gruppera liknande objekt i unika klasser.
- Binär klassificering - Om algoritmen försöker gruppera två distinkta grupper av klasser kallas den binär klassificering.
- Multiklassklassificering - Om algoritmen försöker gruppera objekt till mer än två grupper, kallas den multiklassklassificering.
- Styrka - Klassificeringsalgoritmer fungerar vanligtvis mycket bra.
- Nackdelar - benägen att övermontera och kan vara obegränsad. Till exempel - E-post skräppostklassificerare
- Logistisk regression / klassificering - När Y-variabeln är en binär kategori (dvs. 0 eller 1) använder vi Logistisk regression för förutsägelse. Till exempel - Förutsäga om en given kreditkortstransaktion är bedrägeri eller inte.
- Naïve Bayes klassificerare - Naïve Bayes klassificerare är baserad på Bayesiska teorem. Denna algoritm är vanligtvis bäst lämpad när dimensionerna i ingångarna är höga. Det består av acykliska grafer som har en förälder och många barnnoder. Barnnoderna är oberoende av varandra.
- Beslutsträd - Ett beslutsträd är ett träddiagram som en struktur som består av en intern nod (test på attribut), gren som anger resultatet av testet och bladnoderna som representerar fördelningen av klasser. Rotnoden är den översta noden. Det är en mycket allmänt använd teknik som används för klassificering.
- Support Vector Machine - En supportvektormaskin är eller en SVM gör jobbet med klassificering genom att hitta hyperplanet som ska maximera marginalen mellan två klasser. Dessa SVM-maskiner är anslutna till kärnfunktionerna. Fält, där SVM: er används i stor utsträckning, är biometri, mönsterigenkänning, etc.
fördelar
Nedan är några av fördelarna med övervakade modeller för maskininlärning:
- Modellernas prestanda kan optimeras av användarupplevelserna.
- Övervakad inlärning ger resultat med tidigare erfarenhet och gör att du också kan samla in data.
- Övervakade maskininlärningsalgoritmer kan användas för att implementera ett antal verkliga problem.
nackdelar
Nackdelarna med Supervised Learning är följande:
- Insatsen med att utbilda övervakade modeller för maskininlärning kan ta mycket tid om datasatsen är större.
- Klassificeringen av big data utgör ibland en större utmaning.
- Man kan behöva hantera problemen med övermontering.
- Vi behöver många bra exempel om vi vill att modellen ska fungera bra medan vi utbildar klassificeraren.
God praxis när man bygger in lärningsmodeller
Det är en bra praxis när du bygger en Supervised Learning Machine-modeller: -
- Innan man bygger en bra maskininlärningsmodell måste processen med förbehandling av data utföras.
- Man måste bestämma vilken algoritm som bäst passar ett visst problem.
- Vi måste bestämma vilken typ av data som ska användas för träningsuppsättningen.
- Behöver besluta om strukturen för algoritmen och funktionen.
Slutsats
I vår artikel har vi lärt oss vad som är övervakat lärande och vi såg att vi här tränar modellen med märkta data. Sedan gick vi in på modellerna och deras olika typer. Vi såg slutligen fördelarna och nackdelarna med dessa övervakade maskininlärningsalgoritmer.
Rekommenderade artiklar
Detta är en guide till vad som är Supervised Learning ?. Här diskuterar vi begreppen, hur det fungerar, typer, fördelar och nackdelar med Supervised Learning. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Vad är djupt lärande
- Övervakad inlärning kontra djup inlärning
- Vad är synkronisering i Java?
- Vad är webbhotell?
- Sätt att skapa beslutsträd med fördelar
- Polynomial regression | Användningar och funktioner