

Vad är Hive-funktion?
Som vi vet idag är Hadoop en av de mångsidiga teknologierna i big data. Hadoop har förmågan att hantera stora datasätt men eftersom datatillväxten är proportionerligt blir kartdämpande program svåra. För att utföra SQL-frågor, närvarande i HDFS introducerades en sådan teknik av Hadoop som heter Apache Hive startad av Facebook. Hive används mycket av dataanalytiker. De distribueras för tre funktioner, nämligen: Datasammanfattning, dataanalys på distribuerad fil och datafråga. Hive tillhandahåller SQL-liknande frågor som kallas HQL - språk med hög fråga stöder DML, användardefinierade funktioner. Hive-kompilator konverterar internt denna fråga till kartminskande jobb som förenklar Hadoops arbete när man skriver komplexa program. Vi kunde hitta en bikupa i applikationer som datalagring, datavisualisering och ad-hoc-analys, google analytics. Den viktigaste fördelen är att de använder sig av SQL-kunskap, som är en grundläggande färdighet implementerad över datavetenskapsmän och programvara.
Olika bikupfunktioner i detalj
Hive stöder olika datatyper som inte finns i andra databassystem. den innehåller en karta, matris och struktur. Hive har några inbyggda funktioner för att utföra flera matematiska och aritmetiska funktioner för ett speciellt syfte. Funktioner i bikupa kan kategoriseras i följande typer. De är inbyggda funktioner och användardefinierade funktioner.
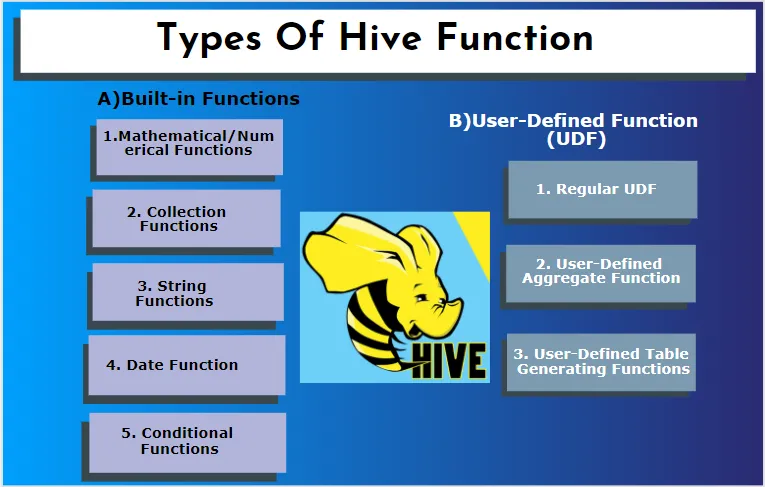
A) Inbyggda funktioner
Dessa funktioner extraherar data från bikuptabellerna och bearbetar beräkningarna. Några av de inbyggda funktionerna är:
1. Matematiska / numeriska funktioner
Dessa funktioner används huvudsakligen för matematiska beräkningar. Dessa funktioner används i SQL-frågor.
| Funktionsnamn | Exempel | Beskrivning |
| ABS (dubbel x) | Hive> välj ABS (-200) från tmp; | Det returnerar det absoluta värdet för ett nummer. |
| CEIL (dubbel x) | Hive> välj CEIL (8.5) från tmp; | Det hämtar minsta heltal större än eller lika med värdet x. |
| Rand (), rand (int seed) | Hive> välj Rand () från tmp;
Rand (0-9) | Det returnerar ett slumpmässigt antal, beror på frövärde som slumpmässiga siffror genererade skulle vara deterministiska. |
| Pow (dubbel x, dubbel y) | Hive> välj Pow (5, 2) från tmp; | Det returnerar x-värde höjt till y-effekten. |
| GOLV (dubbel y) | Hive> välj FLOOR (11.8) från tmp; | Det ger ett maximalt heltal mindre än eller lika för att ge värdet y. |
| EXP (dubbel a) | Hive> välj Exp (30) från tmp; | Det returnerar exponentvärdet 30. de naturliga algoritmvärdena. |
| PMOD (int a, int b) | Hive> välj PMOD (2, 4) från tmp; | Det ger antalet positiva moduler. |
2. Samlingsfunktioner
Att dumpa alla elementen tillsammans och returnera enstaka element beror på den ingående datatypen.
| Funktionsnamn | Exempel | Beskrivning |
| Map_values (Map) | Hive> välj kartvärden ('hej', 45) | Den hämtar oordnade arrayelement. |
| Storlek (karta) | Hive> välj storlek (karta) | Returnerar antalet element på datatypskartan. |
| Array_contains (Array b) | Hive> välj array_concepts (a (10)) | Returnerar SANT om matrisen innehåller värdet. |
| Sort_array (Array a) | Hive> välj sort_array ((10, 3, 6, 1, 7)) | Sorterar ingångsuppsättningen i stigande ordning enligt den naturliga ordningen för matriselementen och returnerar värdet. |
3. Strängfunktioner
Med hjälp av strängfunktioner utförs dataanalys utmärkt.
| Dela (sträng s, sträng pat) | Hive> välj split ('educba ~ hive ~ Hadoop, ' ~ ') utgång: ("educba", "hive", "Hadoop") | Det delar sträng runt klapputtryck och returnerar en matris. |
| last (sträng s, int Len, sträng pad) | Hive> välj last ('EDUCBA', 6, 'H') | Den returnerar strängar med höger polstring med strängens längd. (padkaraktär). |
| Längd (sträng str) | Hive> välj längd ('educba') | Denna funktion returnerar strängens längd. |
| Rtrim (sträng a) | Hive> välj rtrim ('ÄMNE');
Utgång: 'Ämne' | Resultatet returneras genom att trimma avstånd från höger ändar. |
| Concat (sträng m, sträng n) | Hive> välj concat ('data', 'ware') Resultat: Dataware | Det resulterar i strängen genom att göra sammankoppling av två strängar, detta kan ta valfritt antal ingångar. |
| Omvänd (strängar) | Hive> välj omvänd ('Mobil') | Returnerar resultatet av en omvänd sträng. |
4. Datumfunktion
Det är nödvändigt att ha dataformat i bikupan för att förhindra Null-fel i utgången. Det är nödvändigt att ha datumkompatibilitet för att gå med hive-introducerade datumfunktioner.
| Unix_timestamp ( Stringdatum, strängmönster ) | Hive> välj Unix_ timestamp ('2019-06-08', 'yyyy-mm-dd'); Resultat: 124576 400 tid taget: 0.146 sekunder | Denna funktion returnerar datum till det specifika formatet och returnerar sekunder mellan datum- och Unix-tider. |
| Unix_timestamp (String date) | Hive> välj Unix_ timestamp ('2019-06-08 09:20:10', 'åååå-mm-dd'); | Det returnerar datumet i 'åååå-MM-dd HH: mm: ss' -format i Unix-tidsstämpel. |
| Hour (String date) | Hive> välj timme ('2019-06-08 09:20:10'); Resultat: 09 timmar | Det returnerar tidsstämpel timmen |
5. Villkorliga funktioner
| If (Boolean test, T value true, t false) | Hive> välj IF (1 = 1, 'TRUE', 'FALSE') som IF_CONDITION_TEST; | Det kontrollerar med villkoret om värdet är sant returnerar 1 och falskt returnerar 0. |
| Är inte noll (b) | Hive> Select är inte null (null); | Detta hämtar inte null-uttalanden. om null returnerar falskt. |
| Koalesce (värde1, värde2) | Exempel: bikupa> välj sammanfall (Null, noll, 4, noll, 6). den returnerar 4. | Den hämtar först inte nollvärden från listan över värden. |
B) Användardefinierad funktion (UDF)
Hive använder användarspecifika funktioner enligt de klientkrav som det skrivs i java-programmering. Det implementeras av två gränssnitt, nämligen enkla API och komplexa API. De åberopas från bikupfrågan. Tre typer av UDF: er
1. Vanlig UDF
Det fungerar på ett bord med en enda rad. Det skapas genom att skapa en java-klass och sedan packa dem i en .jar-fil, nästa steg är att verifiera med en bikupklassväg. kör sedan dem slutligen i en bikupfråga.
2. Användardefinierad aggregerad funktion
De använder aggregerade funktioner som avg / medel genom att implementera fem metoder init (), iterate (), partiell (), merge (), terminera ().
3. Användardefinierad tabellgenererande funktioner
Det fungerar med en enda rad i en tabell och resulterar i flera rader.
Slutsats
Sammanfattningsvis har vi lärt oss att arbeta i bikupplattformen med inbyggda funktioner och användardefinierade funktioner i detalj genom denna artikel. De flesta organisationer har programmerare och SQL-utvecklare för att arbeta med serversidan, men en apachehive är ett kraftfullt verktyg som hjälper dem att använda Hadoop-ramverk utan förkunskaper om program och kartminskning. Hive hjälper nya användare att starta och utforska dataanalys utan några hinder.
Rekommenderade artiklar
Detta är en guide till Hive-funktionen. Här diskuterar vi konceptet, två olika typer av funktioner och delfunktioner i Hive. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Toppsträngfunktioner i bikupa
- Hiveintervjufrågor
- Vad är RMAN Oracle?
- Vad är vattenfallsmodell?
- Introduktion till Hive Architecture
- Hive Order by