
Introduktion till maskininlärningsmodeller
En översikt över olika maskininlärningsmodeller som används i praktiken. Utifrån definitionen är en maskininlärningsmodell en matematisk konfiguration som erhålls efter tillämpning av specifika maskininlärningsmetoder. Med hjälp av det omfattande utbudet av API: er är det idag ganska mycket rakt fram att bygga en maskininlärningsmodell med färre koderader. Men den verkliga färdigheten hos en tillämpad datavetenskapspersonal ligger i att välja rätt modell baserat på problemställningen och korsvalidering istället för att slänga data till smarta algoritmer slumpmässigt. I den här artikeln kommer vi att diskutera olika modeller för maskininlärning och hur man använder dem effektivt baserat på vilken typ av problem de hanterar.
Typer av maskininlärningsmodeller
Baserat på typen av uppgifter kan vi klassificera maskininlärningsmodeller i följande typer:
- Klassificeringsmodeller
- Regressionsmodeller
- Clustering
- Dimensionalitetsminskning
- Deep Learning etc.
1) Klassificering
När det gäller maskininlärning är klassificering uppgiften att förutsäga ett objekts typ eller klass inom ett bestämt antal alternativ. Outputvariabeln för klassificering är alltid en kategorisk variabel. Till exempel är att förutsäga ett e-postmeddelandet skräppost eller inte är en vanlig binär klassificeringsuppgift. Låt oss nu notera några viktiga modeller för klassificeringsproblem.
- K-närmaste grannalgoritm - enkel men beräknande uttömmande.
- Naiva Bayes - Baserat på Bayes sats.
- Logistic Regression - Linjär modell för binär klassificering.
- SVM - kan användas för binära / multiklassklassificeringar.
- Beslutsträd - " Om annat " baserat klassificerare, mer robust för utläggare.
- Ensembler - Kombination av flera maskininlärningsmodeller klubbar ihop för att få bättre resultat.
2) Regression
I maskinen är inlärningsregression en uppsättning problem där utgångsvariabeln kan ta kontinuerliga värden. Till exempel kan förutsäga flygbolagets pris betraktas som en vanlig regressionsuppgift. Låt oss notera några viktiga regressionsmodeller som används i praktiken.
- Linear Regression - Enklaste baslinjemodell för regressionsuppgift, fungerar bra bara när data är linjärt separerbara och mycket mindre eller ingen multikollinearitet finns.
- Lasso-regression - Linjär regression med L2-regularisering.
- Ridge Regression - Linjär regression med L1-regularisering.
- SVM-regression
- Beslutsträdregression etc.
3) Clustering
I enkla ord är gruppering uppgiften att gruppera liknande objekt ihop. Maskininlärningsmodeller hjälper till att identifiera liknande objekt automatiskt utan manuell intervention. Vi kan inte bygga effektiva övervakade modeller för maskininlärning (modeller som behöver utbildas med manuellt kuraterade eller märkta data) utan homogena data. Clustering hjälper oss att uppnå detta på ett smartare sätt. Följande är några av de allmänt använda klustermodellerna:
- K betyder - Enkelt men lider av hög variation.
- K betyder ++ - Modifierad version av K betyder.
- K medoider.
- Agglomerativ gruppering - En hierarkisk klustermodell.
- DBSCAN - Densitetsbaserad klusteralgoritm etc.
4) Dimensionalitetsminskning
Dimensionalitet är antalet prediktorvariabler som används för att förutsäga den oberoende variabeln eller målet. Av data i den verkliga världen är antalet variabler för hög. För många variabler ger också förbannelsen att överanpassa modellerna. I praktiken bland dessa stora antal variabler, inte alla variabler bidrar lika till målet och i ett stort antal fall kan vi faktiskt bevara avvikelser med ett mindre antal variabler. Låt oss lista några vanliga modeller för minskning av dimension.
- PCA - Det skapar mindre antal nya variabler ur ett stort antal prediktorer. De nya variablerna är oberoende av varandra men mindre tolkbara.
- TSNE - Ger lägre dimensionell inbäddning av högdimensionella datapunkter.
- SVD - Nedbrytning av enkelvärdet används för att sönderdela matrisen i mindre delar för att effektiv beräkna.
5) Deep Learning
Deep learning är en delmaskin av maskininlärning som handlar om neurala nätverk. Baserat på arkitekturen i neurala nätverk, låt oss lista viktiga modeller för djup inlärning:
- Multi-Layer perceptron
- Convolution Neural Networks
- Återkommande nervnätverk
- Boltzmann-maskin
- Autokodare etc.
Vilken modell är bäst?
Ovan tog vi idéer om massor av maskininlärningsmodeller. Nu kommer en uppenbar fråga till oss "Vilken är den bästa modellen bland dem?" Det beror på det aktuella problemet och andra tillhörande attribut som utdelare, volymen av tillgängliga data, kvalitet på data, funktionsteknik etc. I praktiken är det alltid att föredra att börja med den enklaste modellen som är tillämplig på problemet och öka komplexiteten gradvis genom korrekt parameterinställning och korsvalidering. Det finns ett ordspråk i datavetenskapens värld - "Korsvalidering är mer pålitligt än domänkunskap".
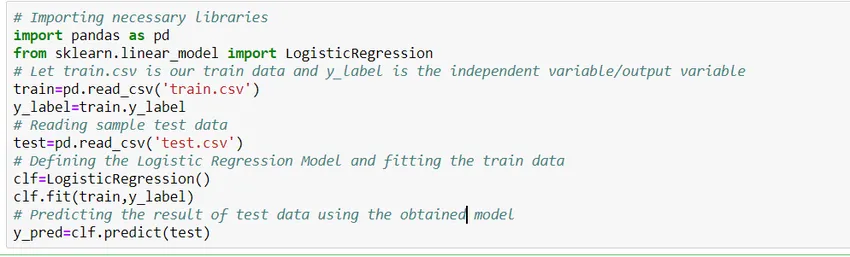
Hur man bygger en modell?
Låt oss se hur man bygger en enkel logistisk regressionsmodell med Scikit Learn-biblioteket av python. För enkelhets skull antar vi att problemet är en standardklassificeringsmodell och 'train.csv' är tåget och 'test.csv' är tåg- och testdata.
Slutsats
I den här artikeln diskuterade vi de viktiga modellerna för maskininlärning som används i praktiska syften och hur man bygger en enkel maskininlärningsmodell i python. Att välja en riktig modell för ett visst användningsfall är mycket viktigt för att få rätt resultat av en maskininlärningsuppgift. För att jämföra prestandan mellan olika modeller definieras utvärderingsmetriker eller KPI: er för specifika affärsproblem och den bästa modellen väljs för produktion efter tillämpning av statistisk resultatkontroll.
Rekommenderade artiklar
Detta är en guide till maskininlärningsmodeller. Här diskuterar vi de 5 bästa typerna av maskininlärningsmodeller med definitionen. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Maskininlärningsmetoder
- Typer av maskininlärning
- Maskininlärningsalgoritmer
- Vad är maskininlärning?
- Hyperparameter-maskininlärning
- KPI i Power BI
- Hierarkisk klusteralgoritm
- Hierarkisk klustering Agglomerativ & delande kluster