

Översikt över Data Mining Architecture
Datagruvan är sättet att hitta och utforska mönstren grundläggande eller avancerad nivå i en komplicerad uppsättning stora datamängder som involverar de metoder som placeras i skärningspunkten mellan statistik, maskininlärning och även databassystem. Det kan sägas vara ett tvärvetenskapligt fält inom statistik och datavetenskap där målet är att extrahera informationen med hjälp av intelligenta metoder och tekniker från en viss uppsättning data genom extraktion och därmed transformera uppgifterna. Datahanteringsaktiviteter och databehandlingsaktiviteter tillsammans med slutsatser beaktas också. I den här artikeln kommer vi att dyka djupt in i arkitekturen för data mining.
Data Mining Architecture
Datagruvan är tekniken för att extrahera intressant kunskap från en uppsättning enorma mängder data som sedan lagras i många datakällor som filsystem, datalager, databaser. De primära komponenterna i databearbetningsarkitekturen involverar -
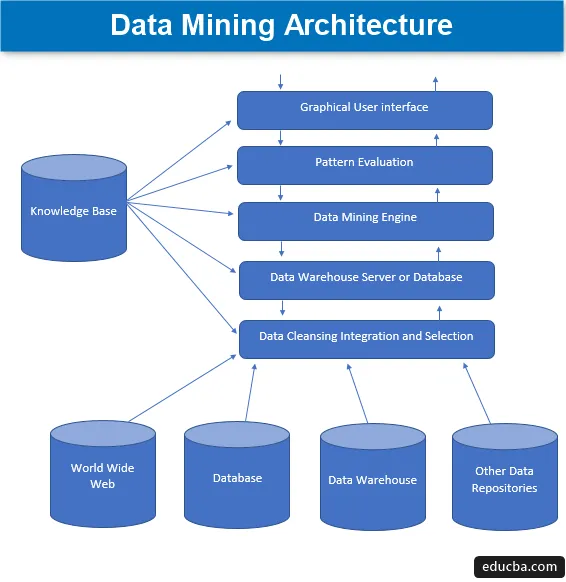
1. Datakällor
En stor variation av nuvarande dokument som datavarehus, databas, www eller populärt kallat World Wide Web som blir de faktiska datakällorna. Oftast kan det också vara så att uppgifterna inte finns i någon av dessa gyllene källor utan endast i form av textfiler, vanliga filer eller sekvensfiler eller kalkylblad och då måste data bearbetas i en mycket på liknande sätt som behandlingen skulle göras på de data som mottagits från gyllene källor. De flesta av de stora delarna av data idag tas emot från internet eller över hela världen, eftersom allt som finns på internet idag är data i någon eller annan form som bildar någon form av informationslagringsenheter.
Innan informationen behandlas framåt involverar de olika processerna genom vilka de rensas, integreras och valts innan data slutligen överförs till databasen eller någon av EDW-servern (enterprise data warehouse). Den stora utmaningen som ibland ligger i denna uppsättning data är olika källnivåer och ett brett utbud av dataformat som bildar datakomponenterna. Därför kan inte uppgifterna användas direkt för bearbetning i sitt naiva tillstånd utan bearbetas, transformeras och utformas på ett mycket mer användbart sätt. På detta sätt säkerställs också uppgifternas tillförlitlighet och fullständighet. Så det primära steget involverar datainsamling, rengöring och integration, och posta att endast relevant information skickas vidare. All denna aktivitet utgör en del av en separat uppsättning verktyg och tekniker.
2. Data Warehouse Server eller Database
Databaseservern är det faktiska utrymmet där informationen finns när den har mottagits från olika antal datakällor. Servern innehåller den faktiska uppsättningen data som blir redo att behandlas och därför hanterar servern datainsamlingen. All denna aktivitet är baserad på begäran om personupptagning av person.
3. Data Mining Engine
När det gäller datakommunikation bildar motorn kärnkomponenten och är den viktigaste delen, eller för att säga drivkraften som hanterar alla förfrågningar och hanterar dem och används för att innehålla ett antal moduler. Antalet moduler som ingår inkluderar gruvuppgifter som klassificeringsteknik, associeringsteknik, regressionsteknik, karakterisering, förutsägelse och kluster, tidsserieranalys, naiva Bayes, stödvektormaskiner, ensemblemetoder, boosting- och bagging-tekniker, slumpmässiga skogar, beslutsträd, etc.
4. Mönsterutvärderingsmoduler
Denna utvärderingsteknik för modulerna är huvudsakligen ansvarig för att mäta intressensen hos alla de mönster som används för att beräkna grundnivån för tröskelvärdet och används också för att interagera med datagruvmotorn för att samordna i utvärderingen av andra moduler. Sammantaget är huvudkompositionen med denna komponent att leta efter och söka efter alla intressanta och användbara mönster som kan göra uppgifterna av relativt bättre kvalitet.
5. Grafiskt användargränssnitt
När informationen kommuniceras med motorerna och bland olika mönsterutvärderingar av moduler, blir det en nödvändighet att interagera med de olika komponenterna som finns och göra det mer användarvänligt så att effektiv och effektiv användning av alla nuvarande komponenter kan göras och därför uppstår behovet av ett grafiskt användargränssnitt populärt känt som GUI.
Detta används för att upprätta en känsla av kontakt mellan användaren och data mining-systemet och därigenom hjälpa användare att komma åt och använda systemet effektivt och enkelt för att hålla dem sakna alla komplexiteter som har uppstått i processen. Detta är en form av abstraktion där bara de relevanta komponenterna visas för användarna och alla komplexiteter och funktionaliteter som är ansvariga för att bygga systemet är dolda för enkelhetens skull. Närhelst användaren skickar in en fråga interagerar modulen sedan med den totala uppsättningen för ett data mining-system för att producera en relevant utgång som lätt kan visas för användaren på ett mycket mer förståeligt sätt.
6. Knowledge Base
Detta är komponenten som utgör basen i den övergripande datainvinningsprocessen eftersom det hjälper till att vägleda sökningen eller i utvärderingen av intressanta mönster som bildas. Detta kunskapsbaserat består av användarnas övertygelser och även de data som erhållits från användarupplevelser som i sin tur är till hjälp i datainsamlingsprocessen. Motorn kan få sina uppsättningar av ingångar från den skapade kunskapsbasen och ger därmed mer effektiva, exakta och tillförlitliga resultat.
Data mining är en av de viktigaste teknikerna i dag som handlar om datahantering och databehandling som utgör ryggraden i alla organisationer. Analys av data i alla organisationer ger fruktbara resultat. Varje komponent i tekniken och arkitekturen för datainsamling har sitt eget sätt att utföra ansvar och även genomföra datakommunikation effektivt. De olika modulerna behövs för att interagera på rätt sätt för att ge ett värdefullt resultat och genomföra det komplexa förfarandet för data mining med framgång genom att tillhandahålla rätt uppsättning information till företaget.
Rekommenderade artiklar
Detta har varit en guide till Data Mining Architecture. Här diskuterar vi de huvudsakliga komponenterna i databearbetningsarkitekturen. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Data Mining Tool
- Fördelar med Data Mining
- Vad är Clustering i Data Mining?
- HTML5 intervjufrågor och svar
- Mest använda tekniker för lärande av ensemble
- Algoritmer av modeller i dataanläggning