

Skillnader mellan Sqoop och Flume
Sqoop är en produkt från Apache-programvara. Sqoop extraherar användbar information från Hadoop och skickar sedan till de externa datalagren. Med hjälp av Sqoop kan vi importera data från en RDBMS eller mainframe till HDFS. Flume kommer också från Apache-programvaran. Den samlar in och flyttar rekursiv data som genereras. Apache Flume är inte bara begränsad till aggregering av logg, utan datakällor kan anpassas och därmed kan Flume användas för att transportera stora mängder data. Det bästa sättet att samla in, aggregera och flytta stora mängder data mellan Hadoop Distribuerat filsystem och RDBMS är att använda verktyg som Sqoop eller Flume.
Låt oss diskutera dessa två vanligtvis använda verktyg för ovan nämnda syfte.
Vad är Sqoop
För att använda Sqoop måste en användare ange det verktyg som användaren vill använda och argumenten som styr det specifika verktyget. Du kan också sedan exportera data tillbaka till en RDBMS med Sqoop. Exportfunktionen för Sqoop används för att extrahera användbar information från Hadoop och exportera dem till de externa strukturerade datalagren. Det fungerar med olika databaser som Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Architecture: -
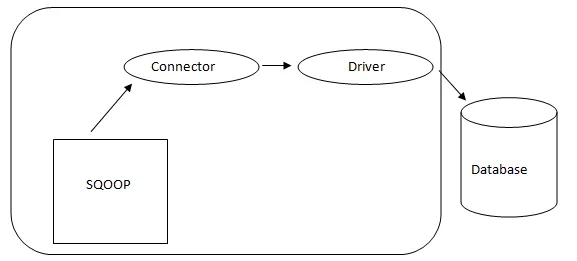
Arkitektur av Sqoop
Anslutningen i en Sqoop är ett plugin för en viss databaskälla, så det är grundläggande att det är en del av Sqoop-anläggningen. Trots det faktum att drivrutinerna är databasspecifika delar och distribueras av olika databasleverantörer, kommer Sqoop själv med olika typer av kontakter som används för rådande databas- och informationslagringssystem. Således levereras Sqoop med en blandning av olika kontakter också ur lådan. Sqoop ger en pluggbar komponent för ett idealiskt nätverk och externt system. Sqoop API ger en användbar struktur för montering av nya anslutningar och därför kan alla databasanslutningar släppas i Sqoop-installationen för att ge anslutning till olika datasystem.
Vad är Flume
Apache Flume är inte bara begränsad till aggregering av logg, utan datakällor kan anpassas och därmed kan Flume användas för att transportera enorma mängder data inklusive, men inte begränsat till e-postmeddelanden, sociala medier genererade data, nätverkstrafikdata och ganska mycket datakälla möjligt.
Flume-arkitektur: - Flume-arkitektur är baserad på många kärnbegrepp:
- Flume Event- det representeras som en enhet för flödande data, som har en byte-nyttolast och uppsättning strängar med valfri stränghuvud. Flume betraktar en händelse bara en generisk byte av byte.
- Flume Agent- Det är en JVM-process som är värd för komponenter som kanaler, diskbänk och källor. Det har potential att ta emot, lagra och vidarebefordra händelserna från en extern källa till nästa nivå.
- Flume Flow - det är den tidpunkt då händelsen genereras.
- Flume Client - det hänvisar till gränssnittet där klienten arbetar vid händelsens ursprungspunkt och levererar det till Flume-agenten.
- Källa - En källa är en som konsumerar händelser med ett specifikt format och levererar det via en specifik mekanism.
- Channel - Det är en passiv butik där evenemang hålls tills diskbänken tar bort den för ytterligare transport.
- Sink - Det tar bort händelsen från en kanal och lägger den på ett externt arkiv som HDFS. Den stöder för närvarande att skapa text- och sekvensfiler och stöder komprimering i båda filtyperna.
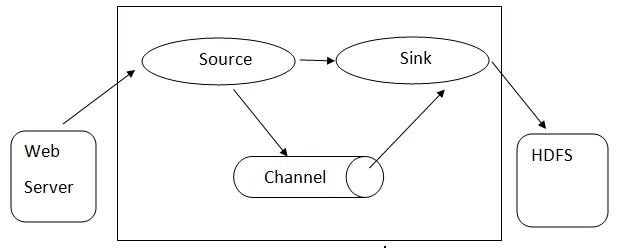
Arkitektur av Flume
Head to Head Jämförelse mellan Sqoop vs Flume (Infographics)
Nedan är topp 7 jämförelsen mellan Sqoop vs Flume

Viktiga skillnader mellan Sqoop vs Flume
Vi vet nu att det finns många skillnader mellan Sqoop vs Flume, här är de viktigaste skillnaderna mellan dem som anges nedan -
1. Sqoop är utformad för att utbyta massinformation mellan Hadoop och Relational Database.
Medan Flume används för att samla in data från olika källor som genererar data angående ett visst användningsfall och sedan överför denna stora mängd data från distribuerade resurser till ett enda centraliserat arkiv.
2. Sqoop innehåller också en uppsättning kommandon som låter dig inspektera databasen du arbetar med. Således kan vi betrakta Sqoop som en samling relaterade verktyg.
När du samlar in datumet Flume skalar data horisontellt och flera Flume-agenter kan sättas in för att samla in datumet och samla dem. Därefter flyttas dataloggar till ett centraliserat datalager, dvs. Hadoop Distribuerat filsystem (HDFS).
3. Nyckelfaktorn för att använda Flume är att data måste genereras på ett kontinuerligt och strömmande sätt. På liknande sätt är Sqoop bäst lämpad i situationer då dina data lever i databasesystem som MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (Jämförelsetabell)
| Grund för jämförelse | SQOOP | VATTENRÄNNA |
|
Grundläggande natur | Sqoop fungerar bra med alla RDBMS som har JDBC (Java Database Connectivity) som Oracle, MySQL, Teradata, etc. | Flume fungerar bra för Streaming-datakälla som genererar kontinuerligt såsom loggar, JMS, katalog, kraschrapporter, etc. |
| Data flöde | Sqoop används specifikt för parallell dataöverföring. Av denna anledning kan utgången vara i flera filer | Flume används för att samla in och aggregera data på grund av dess distribuerade natur. |
| Drivna händelser | Sqoop drivs inte av händelser. | Flume är helt händelsestyrd. |
| Arkitektur | Sqoop följer anslutningsbaserad arkitektur, vilket betyder kontakter, vet hur man ansluter till en annan datakälla. | Flume följer agentbaserad arkitektur, där koden som skrivs i den kallas en agent som ansvarar för att hämta data. |
| Var du ska använda | Används främst för att kopiera data snabbare och sedan använda dem för att generera analytiska resultat. | Vanligtvis används för att dra data när företag vill analysera mönster, grundorsaker eller sentimentanalys med loggar och sociala medier. |
| Prestanda | Det minskar överdrivna lagrings- och bearbetningsbelastningar genom att överföra dem till andra system och har snabb prestanda. | Flume är feltolerant, robust och har en hållbar pålitlighetsmekanism för failover och återhämtning. |
| Släpphistorik | Den första versionen av Apache Sqoop lanserades i mars 2012. Den nuvarande stabila versionen är 1.4.7 | Den första stabila versionen 1.2.0 av Apache Flume lanserades i juni 2012. Den nuvarande stabila versionen är Apache Flume version 1.8.0. |
Slutsats - Sqoop vs Flume
Som du lärde dig ovan är Sqoop och Flume främst två dataintagningsverktyg som används är Big Data-världen. Om du behöver lägga in textuppgifter i Hadoop / HDFS är Flume det rätta valet för att göra det. Om dina data inte genereras regelbundet fungerar Flume fortfarande men det kommer att vara en överdödelse för den situationen. På liknande sätt är Sqoop inte den bästa passningen för händelsestyrd datahantering.
Rekommenderade artiklar
Detta har varit en guide till skillnader mellan Sqoop vs Flume, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. den här artikeln består av alla användbara skillnader mellan Sqoop och Flume. Du kan också titta på följande artiklar för att lära dig mer
- Hadoop vs Teradata - Användbara skillnader att lära sig
- 5 Den viktigaste skillnaden mellan Apache Kafka vs Flume
- Big Data vs Apache Hadoop - Topp 4 jämförelse du måste lära dig
- 5 Den viktigaste skillnaden mellan Apache Kafka vs Flume
- Viktig textbrytning kontra naturligt språkbearbetning - Topp 5 jämförelser