

Introduktion av återkommande nervnätverk (RNN)
Ett återkommande neuralt nätverk är en typ av ett konstgjordt neuralt nätverk (ANN) och används i tillämpningsområden av naturlig språkbearbetning (NLP) och taligenkänning. En RNN-modell är utformad för att känna igen datans sekvensiella egenskaper och därefter använda mönstren för att förutsäga det kommande scenariot.
Arbeta med återkommande nervnätverk
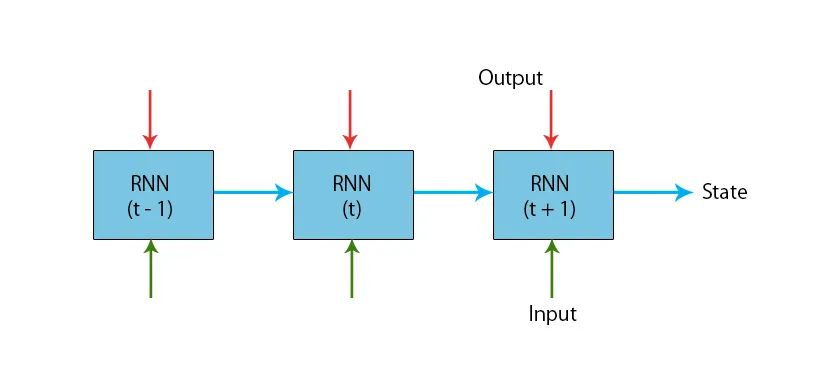
När vi pratar om traditionella neurala nätverk är alla utgångar och ingångar oberoende av varandra, som visas i diagrammet nedan:
Men i fallet med återkommande neurala nätverk matas utgången från de tidigare stegen till ingången i det aktuella tillståndet. Till exempel, för att förutsäga nästa bokstav i något ord, eller för att förutsäga nästa ord i meningen, finns det ett behov av att komma ihåg de tidigare bokstäverna eller orden och lagra dem i någon form av minne.
Det dolda lagret är det som kommer ihåg lite information om sekvensen. Ett enkelt verkligt exempel som vi kan relatera RNN är när vi tittar på en film och i många fall är vi i stånd att förutsäga vad som kommer att hända härnäst men vad om någon just gick med i filmen och han blir ombedd att förutsäga vad kommer att hända nästa? Vad blir hans svar? Han eller hon kommer inte att ha någon aning eftersom de inte är medvetna om de tidigare händelserna i filmen och de har inget minne om det.
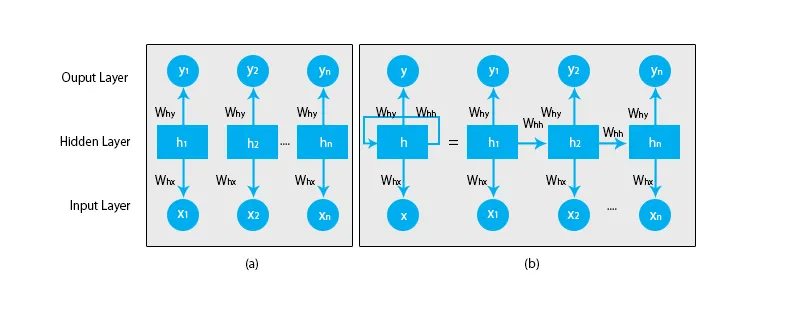
En illustration av en typisk RNN-modell ges nedan:
RNN-modellerna har ett minne som alltid kommer ihåg vad som gjordes i tidigare steg och vad som har beräknats. Samma uppgift utförs på alla ingångar och RNN använder samma parameter för varje ingång. Eftersom det traditionella neurala nätverket har oberoende uppsättningar av input och output, är de mer komplexa än RNN.
Låt oss nu försöka förstå det återkommande nervnätverket med hjälp av ett exempel.
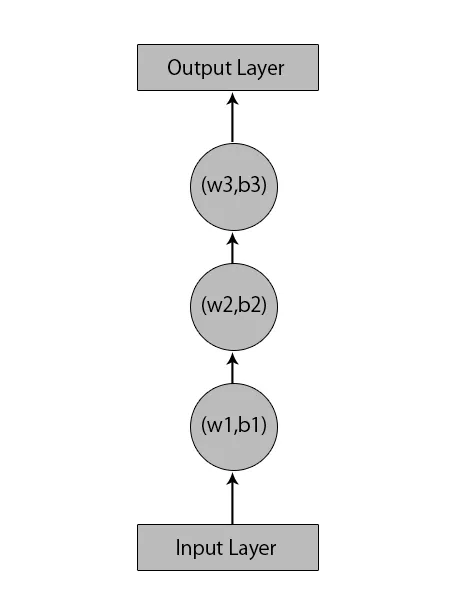
Låt oss säga, vi har ett neuralt nätverk med 1 ingångsskikt, 3 dolda lager och 1 utgångsskikt.
När vi pratar om andra eller traditionella neurala nätverk kommer de att ha sina egna uppsättningar av förspänningar och vikter i sina dolda lager som (w1, b1) för dolda lager 1, (w2, b2) för dolda lager 2 och (w3, b3) ) för det tredje dolda lagret, där: w1, w2 och w3 är vikterna och, b1, b2 och b3 är förspänningarna.
Med tanke på detta kan vi säga att varje lager inte är beroende av något annat och att de inte kommer ihåg något om den föregående inmatningen:
Vad en RNN kommer att göra är följande:
- De oberoende lagren konverteras till det beroende skiktet. Detta görs genom att tillhandahålla samma förspänningar och vikter till alla lager. Detta minskar också antalet parametrar och lager i det återkommande neurala nätverket och det hjälper RNN att memorera den föregående utgången genom att mata ut tidigare utgång som input till det kommande dolda lagret.
- Sammanfattningsvis kan alla dolda skikt sammanfogas till ett enda återkommande skikt så att vikterna och förspänningen är desamma för alla dolda skikten.
Så ett återkommande neuralt nätverk kommer att se ut som nedan:
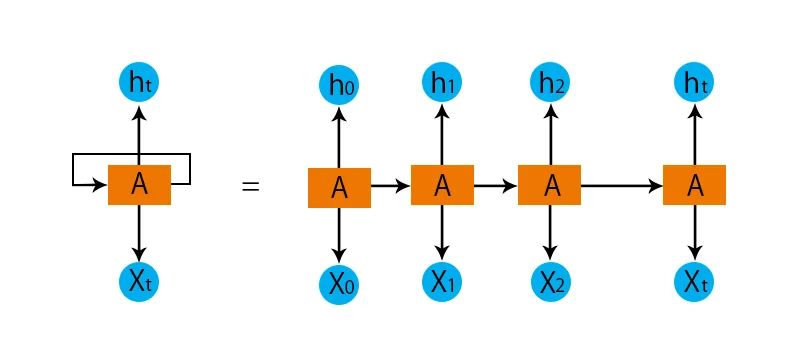
Nu är det dags att ta itu med några av ekvationerna för en RNN-modell.
- För att beräkna det aktuella tillståndet,
h t= f (h t-1, x t ),
Var:
x t är ingångsläget
h t-1 är det tidigare tillståndet,
h t är det aktuella tillståndet.
- För att beräkna aktiveringsfunktionen
h t= tanh (W hh h t-1 +W xh x t ),
Var:
W xh är vikten vid inmatad neuron,
Whh är vikten vid återkommande neuron.
- För beräkning av utgång:
Y t =W hy h t.
Var,
Yt är utgången och,
Vi är vikten vid utgångsskiktet.
Steg för utbildning av ett återkommande neuralt nätverk
- I ingångsskikten skickas den initiala ingången med alla samma vikt och aktiveringsfunktion.
- Med hjälp av den aktuella ingången och den tidigare statusutgången beräknas det aktuella tillståndet.
- Nu kommer det aktuella tillståndet h t att bli h t-1 för det andra steget.
- Detta fortsätter att upprepa för alla steg och för att lösa något särskilt problem kan det gå så många gånger att gå med i informationen från alla tidigare steg.
- Det sista steget beräknas sedan av det aktuella tillståndet för det slutliga tillståndet och alla andra tidigare steg.
- Nu skapas ett fel genom att beräkna skillnaden mellan den faktiska utgången och den utgång som genereras av vår RNN-modell.
- Det sista steget är när processen för backpropagation inträffar där felet backpropagates för att uppdatera vikterna.
Fördelar med återkommande nervnätverk
- RNN kan behandla ingångar av valfri längd.
- En RNN-modell modelleras för att komma ihåg varje information under hela tiden, vilket är till stor hjälp i varje tidsseriesprediktor.
- Även om ingångsstorleken är större ökar inte modellstorleken.
- Vikterna kan delas över tiden.
- RNN kan använda sitt interna minne för att bearbeta den godtyckliga serien av ingångar, vilket inte är fallet med feedforward neurala nätverk.
Nackdelar med återkommande nervnätverk
- Beräkningen är långsam på grund av dess återkommande karaktär.
- Utbildning av RNN-modeller kan vara svårt.
- Om vi använder relu eller tanh som aktiveringsfunktioner blir det mycket svårt att behandla sekvenser som är mycket långa.
- Utsatt för problem som exploderande och försvinnande gradient.
Slutsats
I den här artikeln har vi lärt oss en annan typ av konstgjorda neurala nätverk som kallas Recurrent Neural Network, vi har fokuserat på den huvudsakliga skillnaden som gör att RNN sticker ut från andra typer av neurala nätverk, områden där det kan användas i stor utsträckning, t.ex. i taligenkänning och NLP (Natural Language Processing). Vidare har vi gått bakom arbetet med RNN-modeller och funktioner som används för att bygga en robust RNN-modell.
Rekommenderade artiklar
Detta är en guide till återkommande nervnätverk. Här diskuterar vi introduktionen, hur det fungerar, steg, fördelar och nackdelar med RNN, etc. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -- Vad är nervnätverk?
- Maskininlärningsramar
- Introduktion till artificiell intelligens
- Introduktion till Big Data Analytics
- Implementering av nervnätverk