

Introduktion till ANOVA i R
Följande artikel ANOVA i R ger en översikt för att jämföra medelvärdet för olika grupper. En analys av variation (ANOVA) är en mycket vanlig teknik som används för att jämföra medelvärdet för olika grupper. ANOVA-modellen används för hypotesundersökning, där vissa antaganden eller parametrar genereras för en population och den statistiska metoden används för att bestämma om hypotesen är sann eller falsk.
Hypotesen härrör från utredarens antagande och tillgängliga information om befolkningen. ANOVA kallas en analys av variation och används för hypotesundersökningar där medel för en variabel i flera oberoende grupper krävs för att mätas.
Till exempel, i ett laboratorium för att studera eller uppfinna en ny medicin för fetma, kommer forskare att jämföra resultatet av experimentell och standardbehandling. I en fetmaundersökning kan värdefulla resultat härledas när den genomsnittliga fetmahastigheten i befolkningen kan jämföras i olika åldersgrupper. I detta fall skulle man vilja observera den genomsnittliga fetmahastigheten bland olika åldersgrupper som ålder (5 till 18), (19, 35) och (36 till 50). ANOVA-metoden används eftersom det finns mer än två grupper som är oberoende. ANOVA-metoden används för att jämföra medelfetma hos de oberoende grupperna. Funktionen aov () används och Syntax är aov (formel, data = dataframe). I den här artikeln kommer vi att lära oss om ANOVA-modellen och vidare diskutera envägs- och tvåvägs ANOVA-modell tillsammans med exempel.
Varför ANOVA?
- Denna teknik används för att besvara hypotesen medan man analyserar flera datagrupper. Det finns flera statistiska tillvägagångssätt, men ANOVA i R tillämpas när jämförelse måste göras på mer än två oberoende grupper, som i vårt tidigare exempel tre olika åldersgrupper.
- ANOVA-tekniken mäter medelvärdena för de oberoende grupperna för att ge forskare resultatet av hypotesen. För att få exakta resultat måste provmedel, provstorlek och standardavvikelse från varje enskild grupp beaktas.
- Det är möjligt att observera medelvärdet individuellt för var och en av de tre grupperna för jämförelse. Detta tillvägagångssätt har emellertid begränsningar och kan visa sig vara felaktigt eftersom dessa tre jämförelser inte beaktar total data och därför kan leda till typ 1-fel. R ger oss funktionen att utföra ANOVA-analysen för att undersöka variation mellan de oberoende datagrupperna. Det finns fem steg för att utföra ANOVA-analysen. I det första steget ordnas data i csv-format och kolumnen genereras för varje variabel. En av kolumnerna skulle vara en beroende variabel och återstående är den oberoende variabeln. I det andra steget läses data i R-studion och namnges på lämpligt sätt. I det tredje steget är en datasats knuten till enskilda variabler och läses av minnet. Slutligen definieras och analyseras ANOVA i R. I avsnitten nedan har jag tillhandahållit ett par fallstudieexempel där ANOVA-tekniker bör användas.
- Sex insekticider testades på 12 fält vardera, och forskarna räknade antalet buggar som återstod i varje fält. Nu måste bönderna veta om insekticiderna gör någon skillnad, och i så fall vilken som de bäst använder. Du besvarar denna fråga genom att använda funktionen aov () för att utföra en ANOVA.
- Femtio patienter fick en av fem kolesterolreducerande läkemedelsbehandlingar (trt). Tre av behandlingsbetingelserna involverade samma läkemedel som administrerades som 20 mg en gång per dag (1 gång) 10 mg två gånger per dag (2 gånger) 5 mg fyra gånger per dag (4 gånger). De två återstående villkoren (läkemedel och läkemedel) representerade konkurrerande läkemedel. Vilken läkemedelsbehandling gav den största kolesterolreduktionen (svar)?
ANOVA enväg
- Envägsmetoden är en av grundläggande ANOVA-tekniker där variansanalys används och medelvärdet för flera befolkningsgrupper jämförs.
- Envägs ANOVA fick sitt namn på grund av tillgängligheten av envägsklassificerad data. I en enkelriktad ANOVA-beroende variabel och en eller flera oberoende variabler kan vara tillgängliga.
- Vi kommer till exempel att utföra ANOVA-tekniken på kolesteroldatasatsen. Datasättet består av två variabler trt (som är behandlingar på 5 olika nivåer) och svarvariabler. Oberoende variabel - grupper av läkemedelsbehandling, beroende variabel - medel för två eller flera grupper ANOVA. Från dessa resultat kan du bekräfta att ta 5 mg doserna 4 gånger om dagen var bättre än att ta en tjugo mg dos en gång om dagen. Drog D har bättre effekter jämfört med det läkemedlet E
Drog D ger bättre resultat om det tas i 20 mg doser jämfört med läkemedel E
Använder kolesteroldatasats i multikompaktpaketetinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
ANOVA F-testet för behandling (trt) är signifikant (p <0, 0001), vilket ger bevis på att de fem behandlingarna
# är inte alla lika effektiva.
sammanfattning (aov_model)
detach (kolesterol)

Funktionen plotmeans () i gplots-paketet kan användas för att producera en graf över gruppmedel och deras konfidensintervall. Detta visar tydligt behandlingsskillnaderinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
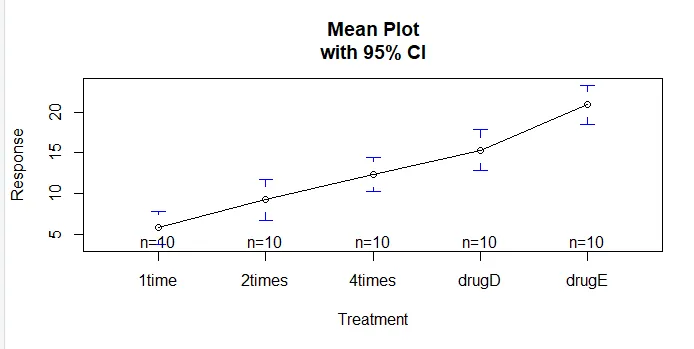
Låt oss undersöka utgången från TukeyHSD () för parvisa skillnader mellan gruppmedel
TukeyHSD (aov_model)
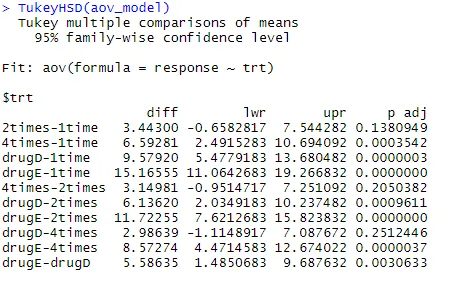
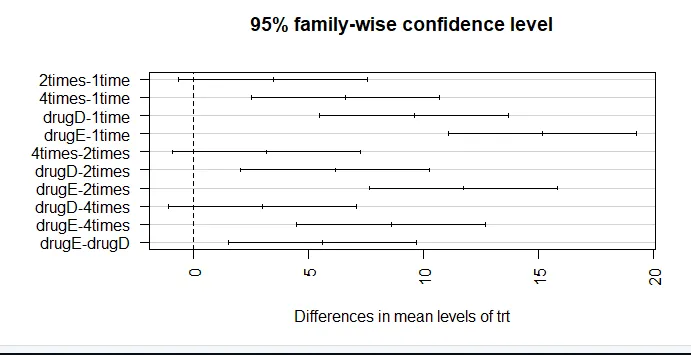
De genomsnittliga kolesterolreduktionerna under 1 gång och två gånger skiljer sig inte signifikant från varandra (p = 0, 138), medan skillnaden mellan 1 gång och 4 gånger är betydligt olika (p <0, 001).
par (mar = c (5, 8, 4, 2)) # ökning av vänstermarginal plot (TukeyHSD (aov_model), las = 2)
Förtroende för resultat beror på i vilken grad dina data uppfyller de antaganden som ligger till grund för de statistiska testerna. I en enkelriktad ANOVA antas den beroende variabeln normalt fördelas och ha lika varians i varje grupp. Du kan använda en QQ-plot för att bedöma biblioteket för normalitetsantaganden (bil).
QQ-plot (lm (svar ~ trt, data = kolesterol), simulera = SANT, huvud = ”QQ-plott”, etiketter = FALSE)
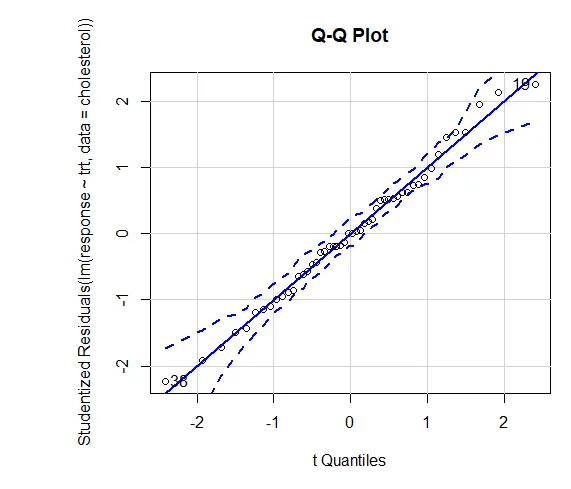
Prickad linje = 95% konfidenshölje, vilket antyder att antagandet om normalitet har uppfyllts ganska bra ANOVA antar att avvikelser är lika mellan grupper eller prover. Bartlett-testet kan användas för att verifiera det antagandet
bartlett.test (svar ~ trt, data = kolesterol). Bartlett's test indikerar att varianserna i de fem grupperna inte skiljer sig signifikant (p = 0, 97).
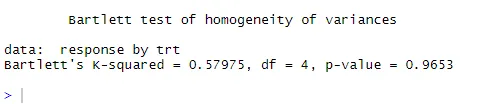
ANOVA är också känslig för outliers-test för outliers med funktionen outlierTest () i bilpaketet. Du kanske inte behöver köra detta paket för att uppdatera ditt bilbibliotek.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
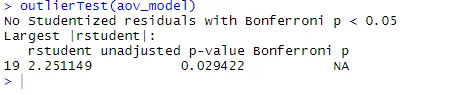
Från utgången kan du se att det inte finns någon indikation på utskott i kolesteroldata (NA uppstår när p> 1). Genom att ta QQ-plotten, Bartlett's test och outlier-testet tillsammans verkar data passa ANOVA-modellen ganska bra.
Tvåvägs Anova
En annan variabel läggs till i tvåvägs ANOVA-testet. När det finns två oberoende variabler, måste vi använda tvåvägs ANOVA snarare än envägs ANOVA-teknik som användes i föregående fall där vi hade en kontinuerlig beroende variabel och mer än en oberoende variabel. För att verifiera tvåvägs ANOVA måste flera antaganden vara uppfyllda.
- Tillgänglighet av oberoende observationer
- Observationer bör normalt distribueras
- Variationerna bör vara lika i observationer
- Outliers bör inte vara närvarande
- Oberoende fel
För att verifiera tvåvägs ANOVA läggs en annan variabel som heter BP till datasatsen. Variabeln anger hastigheten för blodtryck hos patienter. Vi vill verifiera om det finns någon statistisk skillnad mellan BP och dosering som ges till patienterna.
df <- read.csv (“file.csv”)
df
anova_two_way <- aov (svar ~ trt + BP, data = df)
sammanfattning (anova_two_way)
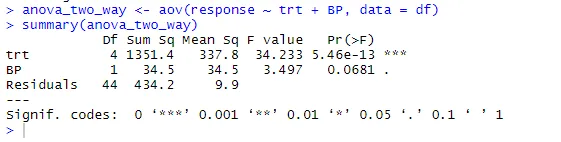
Från utgången kan man dra slutsatsen att både trt och BP skiljer sig statistiskt från 0. Därför kan Null-hypotesen avvisas.
Fördelarna med ANOVA i R
ANOVA-testet bestämmer skillnaden i medelvärde mellan två eller flera oberoende grupper. Denna teknik är mycket användbar för analys av flera artiklar, vilket är viktigt för marknadsanalys. Med ANOVA-testet kan man få nödvändig insikt från data. Till exempel under en produktundersökning där flera information som köpslistor, kundlikningar och ogillar inte samlas in från användarna. ANOVA-testet hjälper oss att jämföra befolkningsgrupper. Gruppen kan antingen vara Man mot Kvinna eller olika åldersgrupper. ANOVA-teknik hjälper till att skilja mellan medelvärdena för olika grupper av befolkningen som verkligen är olika.
Slutsats - ANOVA i R
ANOVA är en av de mest använda metoderna för hypotesundersökning. I den här artikeln har vi genomfört ett ANOVA-test på datauppsättningen bestående av femtio patienter som fick kolesterolreducerande läkemedelsbehandling och har vidare sett hur tvåvägs ANOVA kan utföras när en ytterligare oberoende variabel finns tillgänglig.
Rekommenderade artiklar
Detta är en guide till ANOVA i R. Här diskuterar vi envägs- och tvåvägs Anova-modell tillsammans med exempel och fördelar med ANOVA. Du kan också gå igenom våra andra föreslagna artiklar -
- Regression vs ANOVA
- Vad är SPSS?
- Hur man tolkar resultat med ANOVA-test
- Funktioner i R