

Skillnaden mellan data mining och maskininlärning
Data mining avser utvinning av kunskap från en stor mängd data. Data mining är processen för att upptäcka olika typer av mönster som ärvs i uppgifterna och som är korrekta, nya och användbara. Data mining är delmängden av affärsanalys, det liknar experimentell forskning. Ursprunget till data mining är databaser, statistik. Maskininlärning innebär en algoritm som automatiskt förbättras genom erfarenheter baserade på data. Maskininlärning är ett sätt att upptäcka en ny algoritm från erfarenheten. Maskininlärning involverar studier av algoritmer som kan extrahera information automatiskt. Maskininlärning använder teknik för utvinning av data och en annan inlärningsalgoritm för att bygga modeller av vad som händer bakom vissa data så att det kan förutsäga framtida resultat.
Låt oss förstå detaljerad gruvdrift och maskininlärning i det här inlägget.
Head to head jämförelse mellan data mining vs maskininlärning (Infographics)
Nedan visas de 10 bästa jämförelserna mellan data mining och maskininlärning
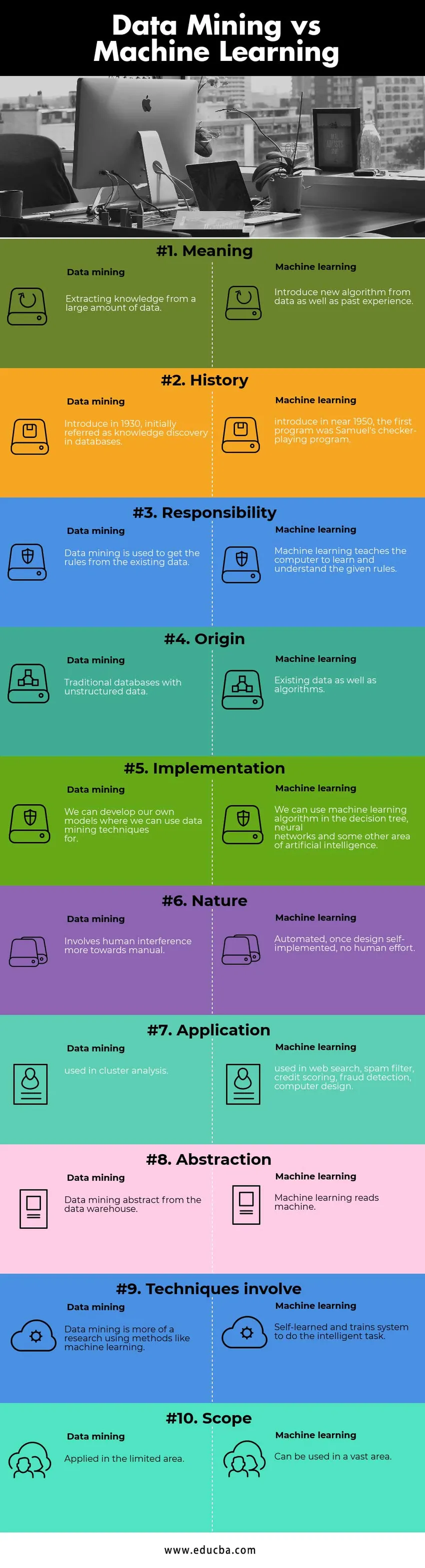 Nyckelskillnaden mellan data mining kontra maskininlärning
Nyckelskillnaden mellan data mining kontra maskininlärning
- För att implementera data mining-tekniker använde den tvåkomponenter, den första är databasen och den andra är maskininlärning. Databasen erbjuder datahanteringstekniker medan maskininlärning erbjuder tekniker för dataanalys. Men för att implementera maskininlärningstekniker använde den algoritmer.
- Data mining använder mer data för att extrahera användbar information och att särskilda data kommer att hjälpa till att förutsäga vissa framtida resultat, till exempel i ett försäljningsföretag som det använder förra årets data för att förutsäga denna försäljning, men maskininlärning kommer inte att lita mycket på data den använder algoritmer, till exempel, OLA, UBER maskininlärningstekniker för att beräkna ETA för åkattraktioner.
- Självlärande kapacitet finns inte i dataanvinningen, den följer reglerna och fördefinieras. Det kommer att ge lösningen för ett visst problem men maskininlärningsalgoritmer är självdefinierade och kan ändra sina regler enligt scenariot, det kommer att ta reda på lösningen för ett visst problem och det löser det på sitt eget sätt.
- Den huvudsakliga och främsta skillnaden mellan data mining och maskininlärning är, utan engagemang för human data mining kan inte fungera men i maskininlärning är mänsklig ansträngning bara involverad den tid då algoritmen definieras efter det att den kommer att avsluta allt med egna medel när det har implementerats för evigt att använda, men detta är inte fallet med data mining.
- Resultatet som produceras av maskininlärning kommer att vara mer exakt jämfört med data mining eftersom maskininlärning är en automatiserad process.
- Data mining använder databasen eller datalagringsservern, data mining-motor och mönsterutvärderingstekniker för att extrahera användbar information medan maskininlärning använder neurala nätverk, prediktiv modell och automatiserade algoritmer för att fatta beslut.
Data mining vs Machine Learning Comparision Table
| grundläggande för jämförelse | Data mining | Maskininlärning |
| Menande | Utvinning av kunskap från en stor mängd data | Introducera ny algoritm från data såväl som tidigare erfarenheter |
| Historia | Introducera 1930, ursprungligen kallad kunskapsupptäckt i databaser | introducera i närheten av 1950, var det första programmet Samuels checker-spelande program |
| Ansvar | Data mining används för att hämta reglerna från befintlig data. | Maskininlärning lär datorn att lära sig och förstå de givna reglerna. |
| Ursprung | Traditionella databaser med ostrukturerad data | Befintliga data såväl som algoritmer. |
| Genomförande | Vi kan utveckla våra egna modeller där vi kan använda teknik för gruvdrift för | Vi kan använda maskininlärningsalgoritm i beslutsträdet, nervnätverk och något annat område av konstgjord intelligens. |
| Natur | Involverar mänskliga interferenser mer manuellt. | Automatiserad, en gång design självimplementerad, ingen mänsklig ansträngning |
| Ansökan | används i klusteranalys | används i webbsökning, spamfilter, kreditpoäng, bedrägeri, datordesign |
| Abstraktion | Data mining-abstrakt från datalageret | Maskininlärning läser maskin |
| Tekniker involverar | Data mining är mer en forskning som använder metoder som maskininlärning | Självlärda och utbildar system för att utföra den intelligenta uppgiften. |
| Omfattning | Tillämpas i det begränsade området | Kan användas i ett stort område. |
Slutsats - Data mining vs Machine learning
I de flesta fall används nu data mining för att förutsäga resultatet från historiska data eller hitta en ny lösning från befintlig data. De flesta av organisationen använder denna teknik för att driva affärsresultaten. Där maskininlärningstekniker växer på det mycket snabbare sättet eftersom det övervinner problemen med vilka data mining-tekniker har. Eftersom maskininlärningsprocessen är mer exakt och mindre fel benägen i jämförelse med datahantering och det är mycket mer kapabelt att fatta sitt eget beslut och lösa problemet. Men för att driva verksamheten fortfarande måste vi ha data mining process eftersom det kommer att definiera problemet för ett visst företag och för att lösa sådana problem kan vi använda maskininlärningstekniker. Med ett ord kan vi säga att för att driva ett företag måste både datalagring och maskininlärningstekniker arbeta hand i hand, en teknik kommer att definiera problemet och andra kommer att ge dig lösningen på det mycket exakta sättet.
Rekommenderad artikel
Detta har varit en guide till datalagring mot maskininlärning, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- 8 viktiga data gruvtekniker för framgångsrikt företag
- 7 Viktiga gruvtekniker för bästa resultat
- 5 Bästa skillnaden mellan Big Data vs Machine Learning
- 5 Den mest användbara skillnaden mellan datavetenskap och maskininlärning