

Vad är Data Mining?
Innan vi förstår, Data Mining Concepts and Techniques kommer vi först att studera data mining. Data mining är en funktion i konverteringen av data till viss kunnig information. Detta hänvisar till processen för att få lite ny information genom att undersöka en stor mängd tillgängliga data. Med olika tekniker och verktyg kan man förutsäga den information som krävs av uppgifterna, bara om proceduren som följs är korrekt. Detta är användbart i olika branscher för att extrahera viss information för framtida analys genom att känna igen vissa mönster i befintliga data i databaser, datalager etc.
Typer av data vid dataanläggning
Följande är de typer av data som data mining kan utföras på:
- Relationsdatabaser
- Datalager
- Avancerade DB och informationsförråd
- Objektorienterade och objektrelaterade databaser
- Transaktions- och rumsliga databaser
- Heterogena och äldre databaser
- Multimedia och streaming databas
- Textdatabaser
- Textbrytning och webbbrytning
Data Mining Process
Nedan är punkterna för dataanvinningsprocess:
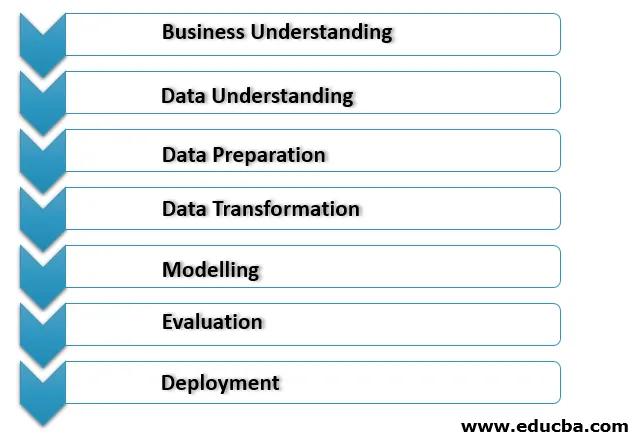
1. Affärsförståelse
Detta är den första fasen i implementeringsprocessen för data mining där alla behov och kundens mål för verksamheten tydligt förstås. Rätta mål för gruvdrift ställs in med hänsyn till det aktuella scenariot i verksamheten och andra faktorer som resurser, antaganden, begränsningar. En korrekt plan för dataintervinning bör vara i detalj och måste uppfylla våra affärs- och datainbrytningsmål.
2. Dataförståelse
Denna fas fungerar som en sanitetskontroll av data som har samlats in från olika resurser för processer för data mining. För det första samlas alla uppgifter från olika källor relaterade till organisationens affärsscenario som kan finnas i olika databaser, platta filer, etc. De insamlade uppgifterna kontrolleras att de matchar korrekt eftersom de inte kan relateras.
Ibland måste också metadata kontrolleras för att minska felen i processerna för data mining. Olika data mining-frågor används för analys av korrekt data och baserat på resultaten kan datakvaliteten kontrolleras. Det hjälper också att analysera om data saknas eller inte.
3. Förberedelse av data
Denna process förbrukar projektets maximala tid. Detta ansikte inkluderar en process som kallas datarengöring för att rengöra de data som har samlats in under dataförståelseprocessen. Datarengöringsprocessen används för att rengöra uppgifterna för att utesluta felaktig bullriga data för data med saknade värden.
4. Datatransformation
I nästa tillstånd utförs datatransformationsoperationer som används för att ändra data för att göra det användbart för implementeringen av data mining. Här transformation såsom aggregering, generaliseringar, normalisering eller attributkonstruktion för att göra data redo för datamodelleringsprocessen.
5. Modellering
Detta är den fasen i datainsamling där rätt teknik används för att bestämma datamönstren. De olika scenariot måste skapas för att kontrollera kvaliteten och giltigheten för denna modell och för att avgöra om de mål som har definierats i affärsförståelseprocessen uppfylls efter implementering av dessa tekniker. Mönstret som har hittats i denna process utvärderas vidare och skickas för distributionen till affärsverksamhetsgruppen så att det kan bidra till att förbättra organisationernas affärspolitik.
6. Utvärdering
I den här fasen görs en korrekt utvärdering av upptäckten av data mining för att ge den en go or no go för implementeringen i affärsprocesserna. En korrekt jämförelse görs med upptäckterna och den befintliga affärsverksamhetsplanen för att korrekt utvärdera förändringen för den information som hittas måste läggas till den nuvarande affärsverksamheten.
7. Distribution
I den här fasen omvandlas den information som har avslutats med hjälp av datalagringsprocesser förståelse för tågförståelse för icke-tekniska intressenter. För denna process skapas en korrekt distributionsplan som inkluderar frakt, underhåll och övervakning av den information som hittas. På detta sätt skapas korrekt projektrapport tillsammans med erfarenheterna och lärdomarna under processen för att överlämna våra upptäckter av data mining till affärsverksamheten.
Därför hjälper denna process att förbättra en organisations affärspolicy.
Teknik för gruvdrift
Nedanstående tekniker och tekniker kan hjälpa till att tillämpa data mining-funktionen på sitt mest effektiva sätt:
1. Spåra mönstren
Att känna igen mönstren i ditt datasæt är en av de grundläggande teknikerna för data mining. Uppgifterna observeras med jämna mellanrum för igenkänning av viss avvikelse. Till exempel kan man se om en viss person reser runt i olika länder då den personen kommer att behöva boka biljetter regelbundet, så att ett speciellt kreditkort kan erbjudas.
2. Klassificering
Det är en av de komplexa teknikerna för data mining där vi måste göra olika urskiljbara kategorier med olika attribut i befintlig data. Dessa kategorier hjälper till att nå olika slutsatser för vår framtida användning. När man till exempel analyserar uppgifterna för trafiken i staden kan områdets trafik klassificeras under låg, medel och tung. Detta hjälper resenärerna att förutsäga trafiken före tiden.
3. Förening
Den här tekniken liknar mönsterspårningstekniken men här är den relaterad till de beroende kopplade variablerna. Det betyder att mönstret för relaterade data hittas som är länkat till befintliga data. Händelserelaterade till den andra händelsen spåras och de specifika mönstren finns i den datan. Till exempel kan filspårningsdata för trafiken i en viss stad man också spåra, de mest besökta platserna i en stad. Detta kan också hjälpa till att spåra kända platser som ska besökas i staden.
4. Upptäckt av tidigare
Denna teknik är relaterad till extraktion av avvikelser i datamönstret. Till exempel ger försäljningen av ett köpcentrum en god vinst under årets 11 månader, men under den senaste månaden sjönk försäljningen så mycket att det leder till förlust. I dessa fall måste vi ta reda på vad som var den faktor som gjorde minskningen av försäljningen så att man kan undvika det nästa gång. Tekniken att hitta en sådan distraktion i det vanliga mönstret är en del av detekteringsmetoden Outlier.
5. Clustering
Denna teknik liknar klassificering, bara skillnaden ligger att den väljer gruppen av data som har vissa likheter placerar dem i en enda grupp. Till exempel klustera olika publik på en biograf utifrån frekvensen som hur ofta de kommer för shower, vilken tidpunkt de kommer för oftast och vilken filmgenre de kommer för.
6. Regression
Denna teknik hjälper till att dra förhållandet mellan de två variablerna som en analys kan bero på. Här försöker vi ta reda på förändringsmönstret i variabeln genom att fixa de andra beroende variablerna. Om vi till exempel behöver ta reda på mönstret i försäljningen av en produkt i ett köpcentrum beroende på dess tillgänglighet, säsong, efterfrågan etc. Detta kan leda till att ägaren fastställer priset för att sälja den.
7. Förutsägelse
Det viktigaste inslaget i data mining är att minska framtida risker och öka organisationens vinst genom att studera de befintliga och historiska mönstren för försäljnings- och kreditrisker. Här hjälper denna typ av teknik oss att ta framtida beslut beroende på mönstret som finns i historiska och nuvarande data och med tanke på marknadsförändringar och risker. Den här tekniken är mest användbar för data mining.
Data Mining Tools
Man behöver inte de senaste teknologierna för att utföra datahantering. Det kan göras med hjälp av de senaste databasesystemen och enkla verktyg som är lätt tillgängliga i alla organisationer. Man kan också skapa sitt eget verktyg när rätt verktyg saknas. Nedan ges det mest populära verktyget i branschen:
1. R-språk
Detta är ett verktyg med öppen källkod som används för statistisk databehandling och grafik. Det här verktyget hjälper till effektiv datahantering och lagringsanläggning och alla funktioner beror på teknikerna nedan:
- Statistisk
- Klassiska statistiska test
- Tidsserie-analys
- Klassificering
- Grafiska tekniker
2. Oracle Data Mining
Detta verktyg är populärt känt som ODM, det är en del av Oracle Advanced Analytics-databasen. Detta verktyg hjälper till att analysera data i datalager och genererar detaljerad insikt som hjälper till vidare att göra förutsägelser. Dessa saker hjälper till att studera kundbeteende, produkter kräver annons och hjälper därmed till att öka försäljningsmöjligheterna.
Utmaningar som står inför implementeringen av Data mine:
- Färdiga experter behövs för att göra komplexa frågor för datainrinning.
- Nuvarande modeller passar kanske inte i den framtida statens databaser. Kanske inte passar framtida tillstånd.
- Svårigheter med att hantera stora databaser.
- Det kan vara nödvändigt att ändra affärsmetoder för att använda information som har upptäckts.
- Heterogena databaser och information som kommer globalt kan resultera i komplex integrerad information.
- Data mining har en förutsättning för att data måste vara olika till sin natur, annars kan resultaten vara felaktiga.
Slutsats-data gruvkoncept och tekniker
- Data mining är ett sätt att spåra tidigare data och göra framtida analyser med hjälp av dem.
- Det är detsamma som att extrahera den information som krävs för analys från tillgångar förra datum som redan finns i databaserna.
- Data mining kan göras på olika typer av databaser som rumslig databas, RDBMS, datalager, flera och gamla databaser, etc.
- Hela gruvprocessen inkluderar affärsförståelse, dataförståelse, förberedelse av data, modellering, utveckling, distribution.
- Olika tekniker för data mining är tillgängliga för att göra data mining fungera på ett effektivt sätt såsom klassificering, regressionsassociation etc. Användningen beror på scenariot.
- De mest effektiva data mining-verktygen är R-språk och Oracle Data.
- Den huvudsakliga nackdelen med dataanläggning som står inför är svårigheterna med att utbilda experter för att använda den analysprogramvaran.
- Det finns olika industrier som använder gruvdrift för sitt analyssyfte, till exempel bank, tillverkning, stormarknader, detaljhandelsleverantörer etc.
Rekommenderade artiklar
Detta är en guide till Data Mining Concepts and Techniques. Här diskuterar vi Miningprocessen, tekniker och verktyg i Data Mining. Du kan också gå igenom våra andra relaterade artiklar för att lära dig mer-
- Fördelar med Data Mining
- Vad är dataanläggning?
- Data Mining Process
- Datavetenskapstekniker
- Clustering in Machine Learning
- Hur man genererar testdata?
- Guide till modeller för dataanläggning