

Introduktion till datavetenskapstekniker
I dagens värld där data är det nya guldet finns det olika typer av analyser tillgängliga för ett företag att göra. Resultatet av ett datavetenskapligt projekt varierar mycket med typen av tillgängliga data och följaktligen är effekten också en variabel. Eftersom det finns många olika typer av analyser tillgängliga blir det nödvändigt att förstå vad några baslinjetekniker behöver väljas. Det väsentliga målet med datavetenskapstekniker är inte bara att söka efter relevant information utan också upptäcka svaga länkar som tenderar att få modellen att fungera dåligt.
Vad är datavetenskap?
Datavetenskap är ett område som sprider sig över flera discipliner. Den innehåller vetenskapliga metoder, processer, algoritmer och system för att samla kunskap och arbeta på samma sätt. Detta fält inkluderar en mängd olika genrer och är en vanlig plattform för att förena begrepp statistik, dataanalys och maskininlärning. I detta arbetar den teoretiska kunskapen om statistik tillsammans med realtidsdata och tekniker i maskininlärning hand i hand för att få fruktbara resultat för verksamheten. Med hjälp av olika tekniker som används inom datavetenskap kan vi i dagens värld innebära bättre beslut som annars kan missa från det mänskliga ögat och sinnet. Kom ihåg att maskinen aldrig glömmer! För att maximera vinsten i en datadriven värld är magiken i Data Science ett nödvändigt verktyg att ha.
Olika typer av datavetenskapsteknik
I följande paragrafer skulle vi undersöka vanliga datavetenskapstekniker som används i alla andra projekt. Även om datavetenskapstekniken ibland kan vara affärsproblemspecifik och kanske inte faller under kategorierna nedan, är det helt okej att beteckna dem som diverse typer. På en hög nivå delar vi upp teknikerna i Supervised (vi vet målpåverkan) och Unsupervised (Vi vet inte om målvariabeln som vi försöker uppnå). På nästa nivå kan teknikerna delas upp i termer
- Den produktion vi skulle få eller vad är avsikten med affärsproblemet
- Typ av data som används.
Låt oss först titta på segregering baserad på avsikt.
1. Oövervakat lärande
- Anomali upptäckt
I denna typ av teknik identifierar vi alla oväntade händelser i hela datasättet. Eftersom beteendet skiljer sig från det faktiska inträffandet av data är de underliggande antagandena:
- Förekomsten av dessa fall är mycket litet i antal.
- Skillnaden i beteende är betydande.
Anomalialgoritmer förklaras, till exempel Isolationsskogen, som ger en poäng för varje post i ett dataset. Denna algoritm är en trädbaserad modell. Med hjälp av denna typ av detekteringsteknik och dess popularitet används de i olika affärsfall, till exempel webbsidevyer, Churn Rate, Intäkter per klick, etc. I nedanstående graf kan vi förklara hur anomali ser ut.
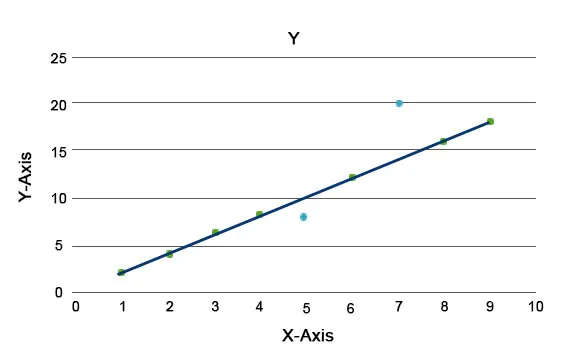
Här representerar de i blått en anomali i datasatsen. De varierar från den vanliga trendlinjen och förekommer mindre.
- Klusteranalys
Genom denna analys är huvuduppgiften att segregera hela datasatsen i grupper så att trenden eller egenskaperna i en gruppdatapunkter är ganska lika varandra. I datavetenskapens terminologi kallar vi dessa för kluster. Till exempel i detaljhandelsverksamheten finns det en plan för att skala verksamheten och det blir absolut nödvändigt att veta hur de nya kunderna skulle bete sig i en ny region baserat på tidigare data vi har. Det blir omöjligt att utforma en strategi för varje individ i en befolkning, men det kommer att vara användbart att bygga befolkningen i kluster så att strategin kommer att vara effektiv i en grupp och är skalbar.
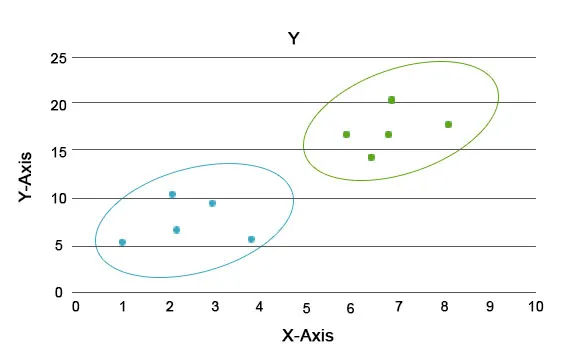
Här är de blå och orange färgerna olika kluster med unika egenskaper inom sig själva.
- Föreningsanalys
Denna analys hjälper oss att bygga intressanta förhållanden mellan objekt i en dataset. Denna analys upptäcker dolda relationer och hjälper till att representera datasatsobjekt i form av associeringsregler eller uppsättningar av täta objekt. Associeringsregeln är uppdelad i två steg:
- Generering av frekvensuppsättningar: I detta genereras en uppsättning där ofta förekommande objekt ställs in tillsammans.
- Regelgenerering: Uppsättningen som byggs ovan passeras genom olika lager av regelbildning för att skapa en dold relation mellan sig. Till exempel kan uppsättningen falla i antingen konceptuella eller implementeringsfrågor eller applikationsproblem. Dessa förgrenas sedan i respektive träd för att bygga associeringsreglerna.
APRIORI är till exempel en algoritm för att bygga associeringsregel.
2. Övervakad inlärning
- Regressionsanalys
I regressionsanalys definierar vi beroende / målvariabeln och de återstående variablerna som oberoende variabler och antar så småningom hur en / mer oberoende variabler påverkar målvariabeln. Regressionen med en oberoende variabel kallas univariat och med mer än en kallas multivariat. Låt oss förstå att du använder univariat och sedan skalar för multivariat.
Till exempel är y målvariabeln och x 1 är den oberoende variabeln. Så från kunskapen om den raka linjen kan vi skriva ekvationen som y = mx 1 + c. Här avgör ”m” hur starkt y påverkas av x 1 . Om “m” är mycket nära noll betyder det att med en förändring i x 1 påverkas y inte starkt. Med ett nummer som är större än 1 blir effekten större och liten förändring i x 1 leder till stor variation i y. På samma sätt som univariate, i multivariate kan skrivas som y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………. Här bestäms effekten av varje oberoende variabel av dess motsvarande “m”.
- Klassificeringsanalys
I likhet med klusteranalys byggs klassificeringsalgoritmer med målvariabeln i form av klasser. Skillnaden mellan kluster och klassificering ligger i det faktum att vi i kluster inte vet vilken grupp datapunkterna faller in, medan vi i klassificeringen vet vilken grupp den tillhör. Och det skiljer sig från regression från perspektivet att antalet grupper ska vara ett fast antal till skillnad från regression, det är kontinuerligt. Det finns ett gäng algoritmer i klassificeringsanalys, till exempel Support Vector Machines, Logistic Regression, Decision Trees, etc.
Slutsats
Sammanfattningsvis förstår vi att varje typ av analys är enorm i sig, men här kan vi ge en liten smak till olika tekniker. I de nästa anteckningarna skulle vi ta var och en av dem separat och gå in på detaljer om olika undertekniker som används i varje förälderteknik.
Rekommenderad artikel
Detta är en guide till datavetenskapstekniker. Här diskuterar vi introduktionen och olika typer av tekniker inom datavetenskap. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Datavetenskapliga verktyg | Topp 12 verktyg
- Data Science algoritmer med typer
- Introduktion till Data Science Karriär
- Data Science vs Data Visualization
- Exempel på multivariat regression
- Skapa beslutsträd med fördelar
- Kort översikt av Data Science Lifecycle