

Introduktion till BFS-algoritm
För att få tillgång till och hantera data effektivt kan de lagras och organiseras i ett speciellt format känt som datastrukturen. Det finns många datastrukturer som stack, array, länkad lista, köer, träd och grafer etc. I linjära datastrukturer, såsom stack, array, länkad lista och kö, är uppgifterna organiserade i linjär ordning medan, i icke- linjära datastrukturer som träd och diagram, är data organiserade hierarkiskt inte i en sekvens. Grafen är en icke-linjär datastruktur som har noder och kanter. Noder i diagrammet kan också kallas vertikaler som är begränsade i antal och kanterna är anslutningslinjerna mellan två noder.
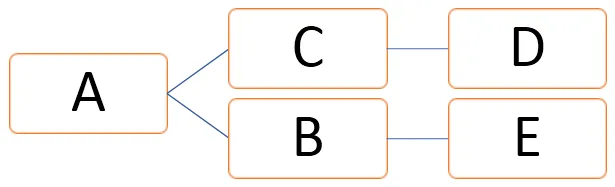
I ovanstående graf kan vertikaler representeras som V = (A, B, C, D, E) och kanter kan definieras som
E = (AB, AC, CD, BE)
Vad är BFS-algoritmen?
Det finns vanligtvis två algoritmer som används för genomgång av en graf. Det är BFS (bredd-första sökning) och DFS (djup första sökning) algoritmer. Traversal of the Graph besöker exakt en gång varje toppunkt eller nod och kant, i en väl definierad ordning. Det är också mycket viktigt att hålla reda på de hörn som de har besökts så att samma toppunkt inte korsas två gånger. I Breath First Search-algoritmen, startar traverseringen från en vald nod eller källnod och traversalen fortsätter genom noderna direkt anslutna till källnoden. I enklare termer bör man i BFS-algoritmen först horisontellt flytta och korsa det aktuella lagret, varefter man flyttade till nästa lager.
Hur fungerar BFS-algoritm?
Låt oss ta exemplet i grafen nedan.
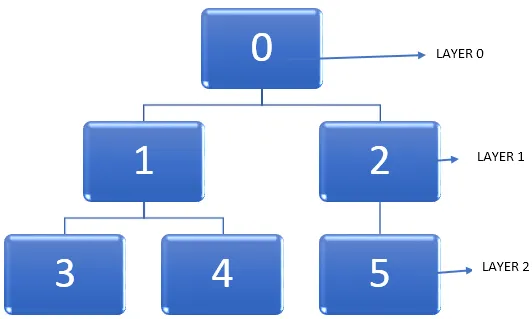
Den viktiga uppgiften är att hitta den kortaste vägen i en graf samtidigt som man korsar noderna. När vi går igenom en graf, går vertex från oupptäckt tillstånd till upptäckt tillstånd och blir slutligen helt upptäckt. Det bör noteras att det är möjligt att fastna någon gång medan du går igenom en graf och en nod kan besöks två gånger. Så vi kan använda en metod för att markera noderna efter att det förändrar tillståndet att upptäckas till att bli helt upptäckt.
I bilden nedan kan vi se att noderna kan markeras i graferna när de blir helt upptäckta genom att markera dem med svart. Vi kan börja vid källnoden och när traversalen fortskrider genom varje nod kan de markeras för att identifieras.
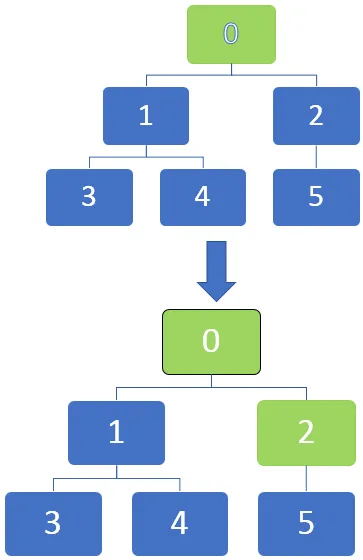
Traversalen startar från ett toppunkt och reser sedan till utgående kanter. När en kant går till ett oupptäckt toppunkt markeras det som upptäckt. Men när en kant går till ett helt upptäckt eller upptäckt topp, ignoreras det.
För en riktad graf, besöks varje kant en gång och för ostyrd graf, besöks den två gånger, dvs en gång när du besöker varje nod. Den algoritm som ska användas bestäms utifrån hur de upptäckta topparna lagras. I BFS-algoritmen används kön där det äldsta toppmaterialet upptäcks först och sedan sprider sig genom skikten från startvinkeln.
Steg utförs för en BFS-algoritm
Följande steg utförs för en BFS-algoritm.
- I en given graf, låt oss börja från ett toppunkt, dvs i diagrammet ovan är det nod 0. Nivån, i vilken denna toppunkt finns, kan betecknas som lager 0.
- Nästa steg är att hitta alla andra vertikaler som är angränsande till utgångshudpunkten, dvs. nod 0 eller omedelbart tillgänglig från den. Då kan vi markera dessa intilliggande toppar för att vara närvarande i lager 1.
- Det är möjligt att komma till samma topppunkt på grund av en slinga i diagrammet. Så vi borde bara resa till de vertikaler som ska finnas i samma lager.
- Därefter markeras moderkoden till det aktuella toppmaterialet som vi befinner oss på. Samma ska utföras för alla vertikaler i lager 1.
- Därefter är nästa steg att hitta alla dessa toppar som är en enda kant bort från alla topparna som finns i lager 1. Dessa nya uppsättningar av toppar kommer att ligga i lager 2.
- Ovanstående process upprepas tills alla noder har korsats.
Exempel:
Låt oss ta exemplet i diagrammet nedan och förstå hur BFS-algoritmen fungerar. I en BFS-algoritm används i allmänhet en kö för att ställa in koderna medan de korsar igenom noderna.
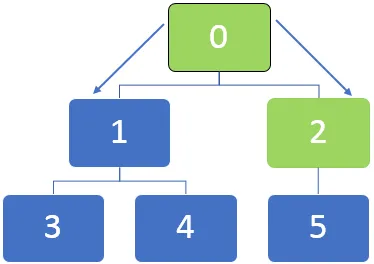
I diagrammet ovan ska först noden 0 besökas och denna nod är i kö till nedanstående kön:

Efter att ha besökt noden 0 står den angränsande noden 0, 1 och 2 i kö. Kön kan representeras enligt nedan: 
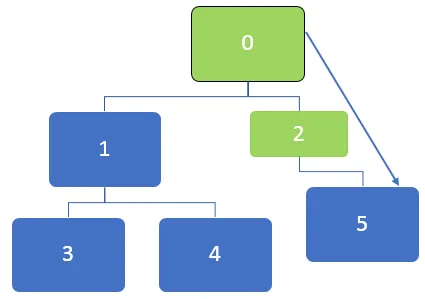
Då besöks den första noden i kön som är 2. Efter att nod 2 har besökts kan kön representeras enligt nedan:

Efter att ha besökt noden 2 kommer 5 att ligga i kö och eftersom det inte finns några osynliga angränsande noder för nod 5, fortfarande är 5 i kö men det kommer inte att besöks två gånger.
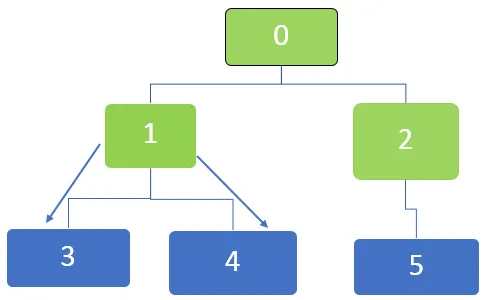
Därefter är den första noden i kön 1 som kommer att besökas. De angränsande noderna 3 och 4 står i kö. Kön representeras enligt nedan

Därefter är den första noden i kön 5, och för den här noden finns det inte fler osynliga angränsande noder. Detsamma gäller för noder 3 och 4 för vilka det inte finns fler osynliga angränsande noder.
Så alla noder passeras och slutligen blir kön tom.

Slutsats
Breddsökningsalgoritm har några stora fördelar att rekommendera den. En av de många applikationerna i BFS-algoritmen är att beräkna den kortaste vägen. Dessutom används det i nätverk för att hitta angränsande noder och kan hittas på sociala nätverkssajter, nätverkssändningar och sopor. Användarna måste förstå kravet och datamönstret för att använda det för bättre prestanda.
Rekommenderade artiklar
Detta har varit en guide till BFS-algoritmen. Här diskuterar vi konceptet, arbetet, stegen och exemplet på prestanda i BFS-algoritm. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- Vad är en girig algoritm?
- Strålspårningsalgoritm
- Digital signaturalgoritm
- Vad är Java Hibernate?
- Digital signaturkryptografi
- BFS VS DFS | Topp 6 skillnader med infografik