
Skillnaden mellan HBase och Cassandra
HBase är en databas som använder Hadoop distribuerade filsystem för lagring. HBase är en viktig del av HDFS och körs ovanpå Hadoop Cluster. HBase är inte en traditionell relationsdatabas, den kräver olika metoder för datamodellering. Cassandra arbetar med datareplikationsmodellen så om det inte finns någon nod är det ingen dataförlust. Cassandra är en distribuerad databas innebär att data kan nås av en klient från valfritt kluster och från vilken nod som helst
1.1) Cassandra:
Det startades av Facebook för det stämmer alltid med applikationskravet. Cassandra startades 2005 och ställdes tillgängligt för allmänheten 2008. Cassandra utvecklades för applikationer som sociala nätverk som Facebook och Twitter.
Cassandra arbetar med "alltid-på" -arkitektur och har en Active-Active-nodmodell så det finns ingen SPoF (Enstaka misslyckande). CQL (Cassandra Query Language) är Cassandras frågespråk men har syntax samma som SQL. Det stöder alla större operativsystem som Linux, Unix, OSX och windows.
Alltid på:
Cassandra är en databas med en distributionsmodell och alla noder är desamma inom klustret. Data replikeras på konfigurerbara noder så vid fel på vissa nr. av noder leder inte till förlust av data.
(Alltid på modell)
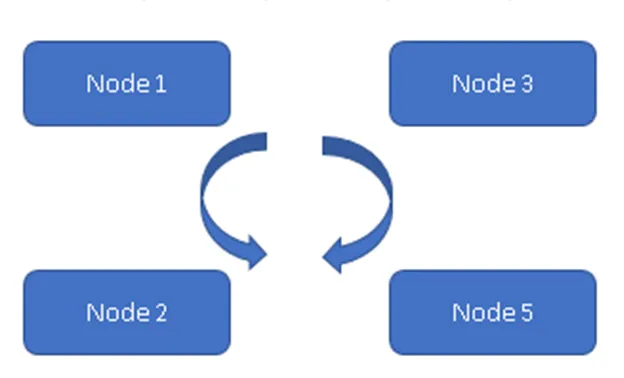
I figur 1 synkroniseras alla de fyra noderna med varandra och replikerar data i klustret. Alla arbetar med Active-Active Model så i fall av nodfel kommer inte att leda till dataförlust. En klient kan läsa informationen från resten av tillgängliga noder / noder.
1.2) HBase:
HBase är en NoSQL-baserad databas och designad för att hantera frågor i stora tabeller med miljarder rader med miljoner kolumner och körs över ett kluster av råvara / normal hårdvara. Det ger dig realtidsfrågefunktioner med hastigheten på en " nyckel- / värdeförvaring " .
HBase baserar faktiskt / arbetar på en fyrdimensionell datamodell.
- Rad-ID / radnyckel
- Kolumnfamilj.
- Nyckelvärdespar.
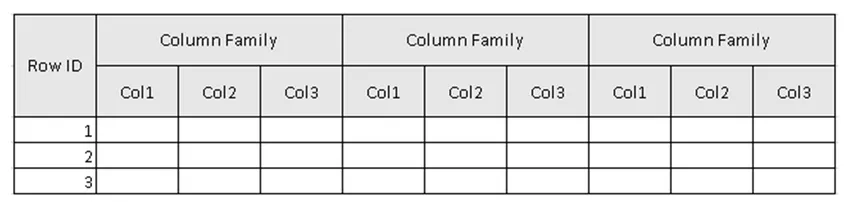
(Figur 2, Exempel schema i tabellen i HBase.)
I figur 2 är tabellen samlingen av kolumnfamiljen & kolumnfamiljen är kolumnsamlingen. Kolumner är samlingen av nyckelvärdespar
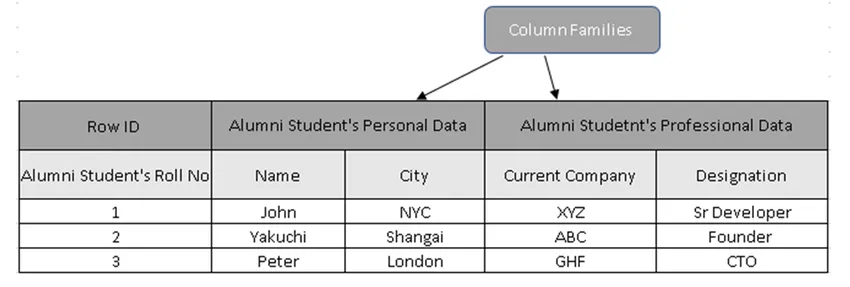
(Figur 3, provtabell i HBase)
I figur 3 är kolumnfamiljer insamlingen av Alumni-studentens data och rad-ID: er (radtangenter) innehåller Student's Roll No.
I själva verket har radtangenter det unika värdet mot kolumnfamiljedata. Genom att använda radnyckeln kan man extrahera hela detaljerna, orsaker till att kolumnorienterade databaser är mycket snabbare än traditionella databaser.
Apache HBase kan användas för slumpmässig läs / skrivåtkomst och det ger felstöd. Det stöder också replikering och arbete med distributionsdatabasmodell.
Jämförelse mellan head-to-head HBase vs Cassandra (Infographics)
Nedan är de bästa 9 skillnaderna mellan HBase vs Cassandra
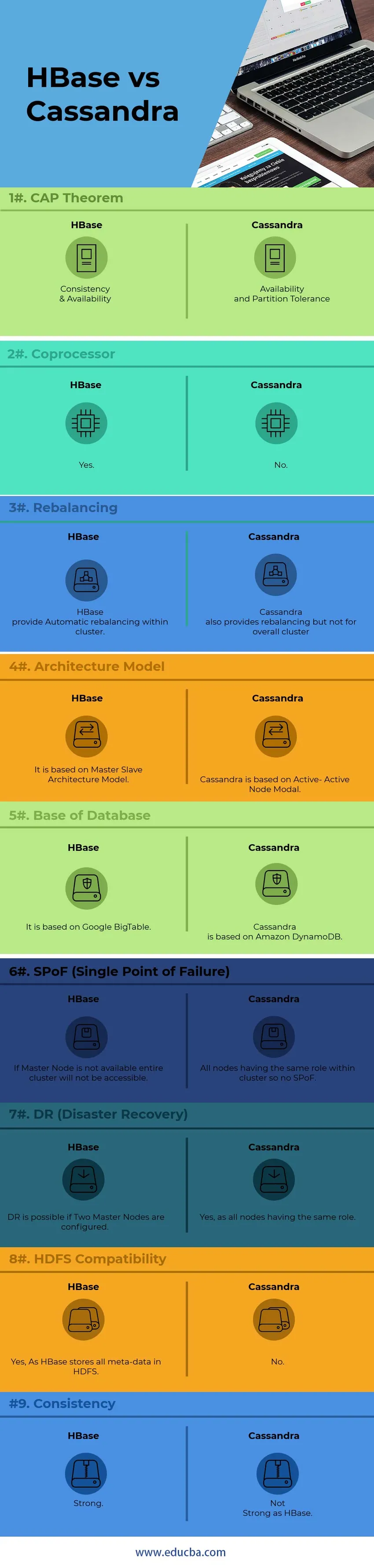 Viktiga skillnader mellan HBase vs Cassandra
Viktiga skillnader mellan HBase vs Cassandra
Nedan finns listor med punkter som beskriver de viktigaste skillnaderna mellan HBase och Cassandra:
1) För intern nodkommunikation använder Cassandra GOSSIP-protokollet medan HBase är baserat på Zookeeper. Tjänster av GOSSIP Protocol är integrerade med Cassandra andra sidan Zookeeper är en helt separat distributionsapplikation.
2) I Cassandra-arkitekturen fungerar alla noder som Active Node medan HBase-arkitekt följer Master-Slave Node-modellen. I Active-Active Node-modellen finns det ingen SPoF (Single Point of Failure). I HBase kommer inte Master-noden att gå ner hela klusteret inte tillgängligt.
3) HBase-stöd Binär trädsökningsmodell medan Cassandra inte stöder B-trädsmodell Utan B-träd kan du inte söka i användarens kolumnfamilj för alla med en årsdag i april medan du kan söka efter alla som bor i Peking med en Jubileum i april.
4) HBase, support C, C ++, Java, Python, Scala skriptspråk medan Cassandra också stöder JavaScript & Ruby.
5) HBase har en funktion som kallas som koprocessorer medan Cassandra inte har en sådan funktion som nu. Koprocessorer tillhandahåller ett bibliotek och en körmiljö för att köra användarkod inom HBase-regionens server och masterprocesser.
6) HBase är utformad för att stödja datalager medan Cassandra kommer att vara perfekt för applikationer som webb- och mobilapplikationer hela tiden.
7) HBasfrågespråk är ett anpassat språk som måste läras medan Cassandra använder sitt eget utvecklade CQL (Cassandra Query Language) som är SQL-liknande språk
8) Att hantera Cassandra är mycket lättare än HBase. I Cassandra måste en enda Java-process köras per nod medan för HBase krävs fullt fungerande HDFS, flera HBase-processer och ett Zookeeper-system.
9) HBase slutar kontrollsumma och automatisk rebalansering medan Cassandra inte stöder rebalansering av klustret totalt sett.
10) Baserat på ” CAP Theorem” arbetar Cassandra på AP Model medan HBase är CP-modell.
CAP-sats
Denna sats används för distribuerade system. C står för Konsistens, A betyder tillgänglighet & P är partitionstolerans. CAP-teorem förklaras nedan:
C (Konsistens): Konsistens betyder att om någon har skrivit ett värde till en databas, kan andra omedelbart läsa samma värde.
A (Tillgänglighet) : Tillgänglighet betyder att om vissa noder inte är tillgängliga i ditt kluster (Noder Gick ner / inte bor i klustret på grund av vissa problem) kommer det inte att påverka hela klustret och Distribuerat system / databas kommer att vara tillgängligt för åtkomst till data. Klustret kommer att vara tillgängligt för alla slags uppgifter.
P (Partition Tolerance): Partition Tolerance betyder att om ett datacenter går ner fortfarande, som inte bör påverka de uppgifter som finns på noderna, och alla data ska vara tillgängliga när som helst. Det betyder att partitionstolerans möjliggör bättre replikering av data till andra datacenter samt inom klustermiljön.
HBase vs Cassandra jämförelsetabell
| Points | HBase | Cassandra |
| CAP-sats | Konsekvens och tillgänglighet | Tillgänglighet och partitionstolerans |
| processor | Ja | Nej |
| ombalansering | HBase tillhandahåller automatisk rebalansering inom ett kluster. | Cassandra tillhandahåller också rebalansering men inte för det övergripande klustret |
| Arkitekturmodell | Den är baserad på Master-Slave Architecture Model | Cassandra är baserat på Active-Active Node Modal |
| Databasens bas | Det är baserat på Google BigTable | Cassandra är baserat på Amazon DynamoDB |
| SPoF (Single Point of Failure) | Om Master Node inte är tillgänglig kommer hela klustret inte att vara tillgängligt | Alla noder har samma roll inom klustret så ingen SPoF |
| DR (Disaster Recovery) | DR är möjligt om två masternoder är konfigurerade. | Ja, eftersom alla noder har samma roll |
| HDFS-kompatibilitet | Ja, eftersom HBase lagrar all metadata i HDFS | Nej |
| Konsistens | Stark | Inte stark som HBase |
Slutsats - HBase vs Cassandra
Facebook och en annan social nätverkssida skulle föredra HBase (tidigare båda använde Cassandra, hänvisa Facebook-inlägg) på grund av dess tillgänglighet andra sidan bankdomänssektor letar efter säkerhet för alla finansiella transaktioner så de skulle välja Cassandra över HBase.
Cassandra viktiga egenskaper involverar hög tillgänglighet, minimal administration och ingen SPoF (enda punkt av misslyckande) andra sidan HBase är bra för snabbare läsning och skrivning av data med linjär skalbarhet.
Företag som Verizon, Bloomberg, Bank of America och mycket mer använder HBase och Cassandra används av stora sociala nätverkssajter som Twitter, Facebook osv …
Vi kan inte dra slutsatsen vilken som är bäst, HBase och Cassandra båda har sin egen fördel och nackdelar. Faktiska prestanda för både HBase- och Cassandra-databaser kan ses i produktionsmiljön.
Rekommenderade artiklar:
Detta har varit en guide till HBase vs Cassandra, deras betydelse, jämförelse mellan huvud och huvud, viktiga skillnader, jämförelsetabell och slutsats. Du kan också titta på följande artiklar för att lära dig mer -
- Hadoop vs Apache Spark - Intressanta saker du behöver veta
- Hur knäcker Hadoop utvecklarintervju?
- Topp 5 stora datatrender
- 5 utmaningar med Big Data Analytics