
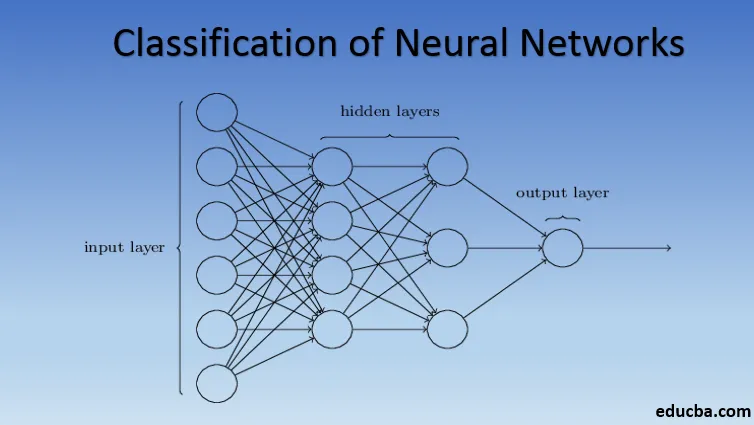
Introduktion till klassificering av neuralt nätverk
Neurala nätverk är det effektivaste sättet (ja, du läser det rätt) för att lösa verkliga problem inom artificiell intelligens. För närvarande är det också ett av de mycket omfattande undersökta områdena inom datavetenskap som en ny form av Neural Network skulle ha utvecklats medan du läser den här artikeln. Det finns hundratals nervnätverk för att lösa problem specifika för olika domäner. Här kommer vi att leda dig genom olika typer av grundläggande neurala nätverk i ökad komplexitet.
Olika typer av grunder för klassificering av nervnätverk
1. Grunt neurala nätverk (samarbetsfiltrering)
Neurala nätverk är gjorda av grupper av Perceptron för att simulera den mänskliga hjärnans nervstruktur. Grunt neurala nätverk har ett doldt lager av perceptronet. Ett av de vanliga exemplen på grunt neurala nätverk är Collaborative Filtering. Det dolda lagret av perceptronen skulle tränas för att representera likheterna mellan enheter för att generera rekommendationer. Rekommendationssystem i Netflix, Amazon, YouTube, etc. använder en version av Collaborative-filtrering för att rekommendera sina produkter enligt användarens intresse.
2. Multilayer Perceptron (Deep Neural Networks)
Neurala nätverk med mer än ett doldt lager kallas Deep Neural Networks. Spoiler varning! Alla följande neurala nätverk är en form av djupa neurala nätverk justerade / förbättrade för att hantera domänspecifika problem. I allmänhet hjälper de oss att uppnå universalitet. Med tanke på tillräckligt antal dolda lager av neuronet kan ett djupt nervnätverk ungefärligt lösa alla komplexa verkliga problem.
Universal Approximation Theorem är kärnan i djupa neurala nätverk för att träna och passa alla modeller. Varje version av det djupa neurala nätverket utvecklas av ett helt anslutet lager av max poolad produkt av matrismultiplikation som är optimerad med backpropagationsalgoritmer. Vi kommer att fortsätta lära oss förbättringarna som resulterar i olika former av djupa neurala nätverk.
3. Convolutional Neural Network (CNN)
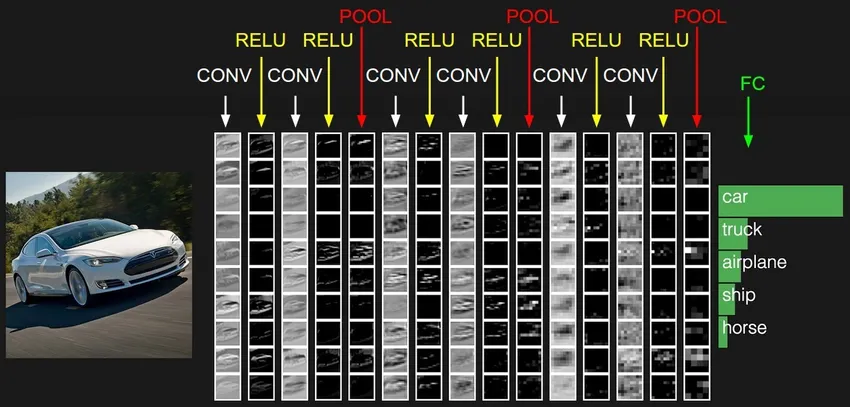
CNN är den mest mogna formen av djupa neurala nätverk för att producera den mest exakta, dvs bättre än mänskliga resultat i datorsyn. CNN: er är gjorda av lager av invändningar som skapas genom att skanna varje bildpixel i ett dataset. När uppgifterna blir ungefärliga lag för lager börjar CNN känna igen mönstren och därigenom känna igen objekten i bilderna. Dessa objekt används i stor utsträckning i olika applikationer för identifiering, klassificering osv. Nya metoder som överföringsinlärning i CNN har lett till betydande förbättringar i modellens felaktighet. Google Translator och Google Lens är de mest kända exemplen på CNN: s.
Tillämpningen av CNN är exponentiell eftersom de till och med används för att lösa problem som i första hand inte är relaterade till datorsyn. En mycket enkel men intuitiv förklaring av CNN finns här.
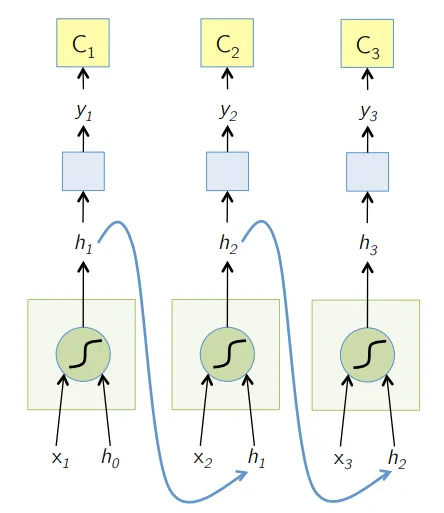
4. Recurrent Neural Network (RNN)
RNN är den senaste formen av djupa nervnätverk för att lösa problem i NLP. Enkelt uttryckt matar RNNs utmatningen från några dolda lager tillbaka till ingångsskiktet för att aggregera och överföra approximationen till nästa iteration (epok) av inputdatat. Det hjälper också modellen att självlära sig och korrigerar förutsägelserna snabbare till en viss utsträckning. Sådana modeller är till stor hjälp för att förstå textens semantik i NLP-operationer. Det finns olika varianter av RNN: er som Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU), etc. I diagrammet nedan matas aktiveringen från h1 och h2 med ingång x2 respektive x3.
5. Lång kortminne (LSTM)
LSTM: er är utformade specifikt för att hantera problemet med försvinnande lutningar med RNN. Försvinnande lutningar händer med stora nervnätverk där lutningsfunktionernas lutningar tenderar att röra sig närmare noll vilket gör att nervnätverk pausar för att lära sig. LSTM löser detta problem genom att förhindra aktiveringsfunktioner inom dess återkommande komponenter och genom att de lagrade värdena inte stängs av. Denna lilla förändring gav stora förbättringar i den slutliga modellen vilket resulterade i att teknikjättar anpassade LSTM till sina lösningar. Över till den "mest enkla självförklarande" illustrationen av LSTM,
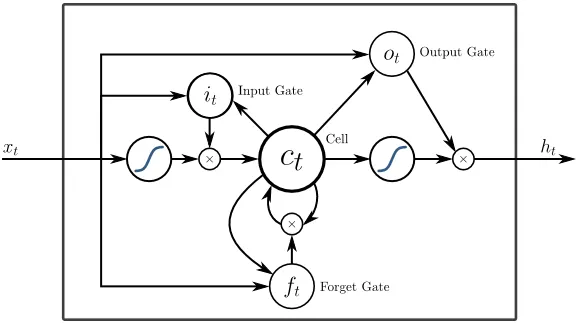
6. Uppmärksamhetsbaserade nätverk
Uppmärksamhetsmodeller tar långsamt även de nya RNN: erna i praktiken. Uppmärksamhetsmodellerna byggs genom att fokusera på en del av en delmängd av informationen de ges och därmed eliminera den överväldigande mängden bakgrundsinformation som inte behövs för den aktuella uppgiften. Uppmärksamhetsmodellerna är byggda med en kombination av mjuk och hård uppmärksamhet och montering genom att bakåt sprida mjuk uppmärksamhet. Flera uppmärksamhetsmodeller staplade hierarkiskt kallas Transformer. Dessa transformatorer är mer effektiva att köra staplarna parallellt så att de ger toppmoderna resultat med jämförelsevis mindre data och tid för utbildning av modellen. En uppmärksamhetsfördelning blir mycket kraftfull när den används med CNN / RNN och kan producera textbeskrivning till en bild enligt följande.

Tekniska jättar som Google, Facebook etc. anpassar snabbt uppmärksamhetsmodeller för att bygga sina lösningar.
7. Generative Adversarial Network (GAN)
Även om modeller för djup inlärning ger toppmoderna resultat, kan de luras av mycket mer intelligenta mänskliga motsvarigheter genom att lägga till brus till verkliga data. GAN är den senaste utvecklingen inom djup inlärning för att hantera sådana scenarier. GAN använder oövervakad inlärning där djupa neurala nätverk tränas med data genererade av en AI-modell tillsammans med den faktiska datasatsen för att förbättra modellens noggrannhet och effektivitet. Dessa motsatsuppgifter används mest för att lura den diskriminerande modellen för att skapa en optimal modell. Den resulterande modellen tenderar att vara en bättre tillnärmning än vad som kan övervinna sådant buller. Forskningsintresse för GAN har lett till mer sofistikerade implementationer som villkorad GAN (CGAN), Laplacian Pyramid GAN (LAPGAN), Super Resolution GAN (SRGAN), etc.
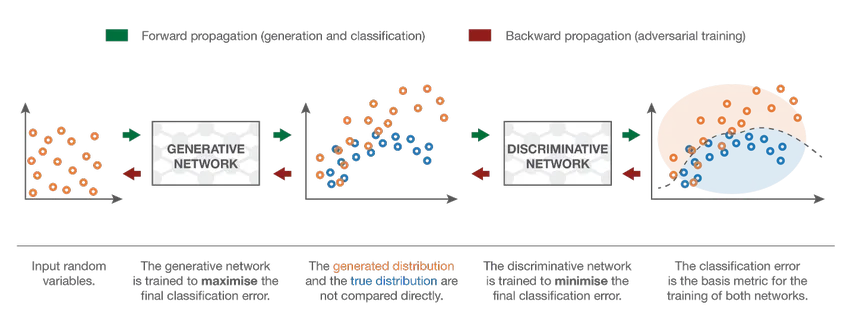
Slutsats - Klassificering av neuralt nätverk
De djupa neurala nätverken har pressat datorns gränser. De är inte bara begränsade till klassificering (CNN, RNN) eller förutsägelser (Collaborative Filtering) utan till och med generering av data (GAN). Dessa data kan variera från den vackra formen av konst till kontroversiella djupa förfalskningar, men de överträffar människor av en uppgift varje dag. Därför bör vi också ta hänsyn till AI-etik och effekter samtidigt som vi arbetar hårt för att bygga en effektiv neural nätverksmodell. Dags för en snygg infographic om neurala nätverk.
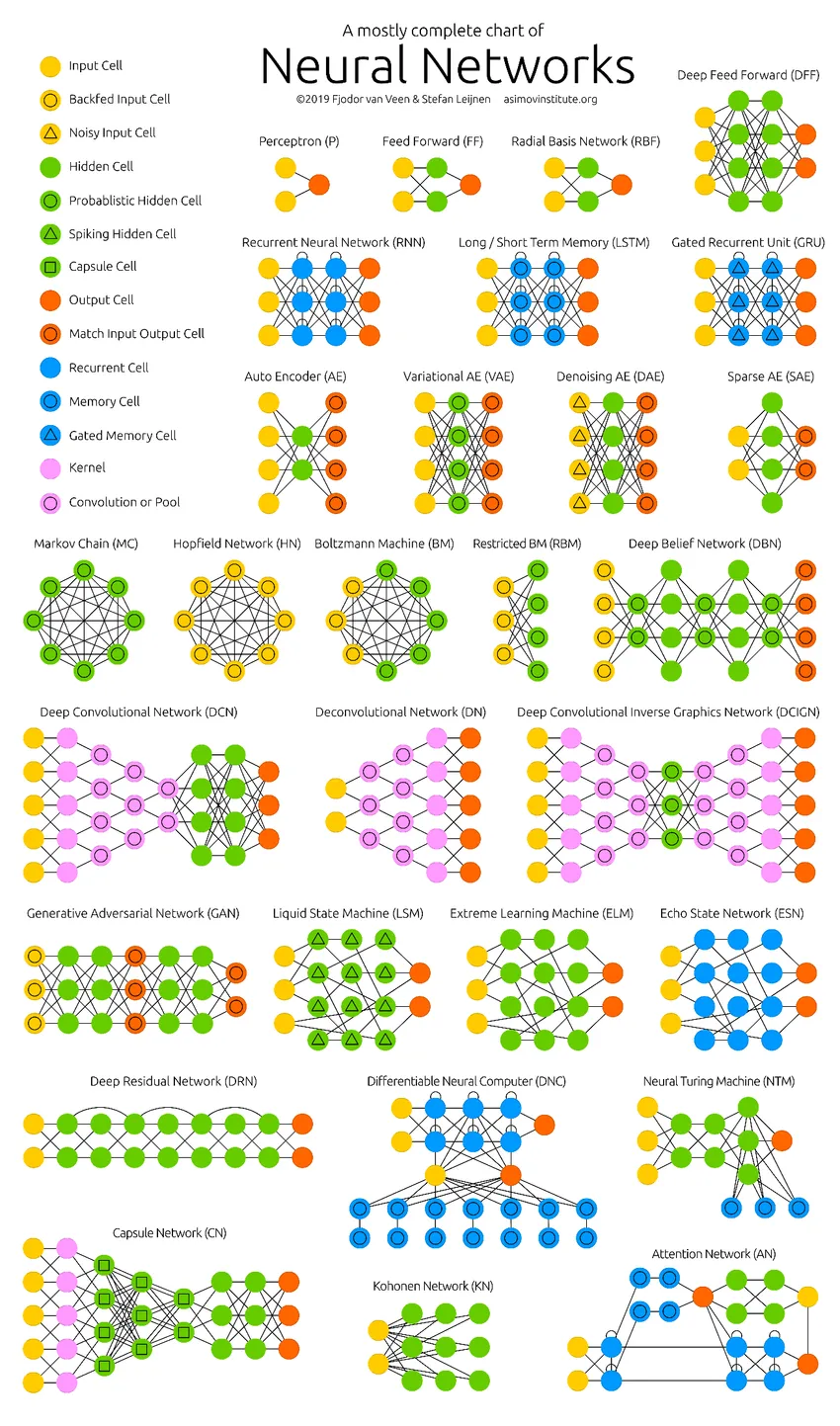
Rekommenderade artiklar
Detta är en guide till klassificering av neuralt nätverk. Här diskuterade vi olika typer av grundläggande neurala nätverk. Du kan också gå igenom våra givna artiklar för att lära dig mer-
- Vad är nervnätverk?
- Neurala nätverksalgoritmer
- Nätverksskanningsverktyg
- Återkommande nervnätverk (RNN)
- Topp 6 jämförelser mellan CNN vs RNN