

Vad är MapReduce Algoritm?
MapReduce Algoritm är huvudsakligen inspirerad av funktionell programmeringsmodell. Det används för att bearbeta och generera big data. Dessa datamängder kan köras samtidigt och distribueras i ett kluster. Ett MapReduce-program består huvudsakligen av kartprocedurer och en reduceringsmetod för att utföra sammanfattningsoperationen som att räkna eller ge några resultat. MapReduce-systemet fungerar på distribuerade servrar som körs parallellt och hanterar all kommunikation mellan olika system. Modellen är en speciell strategi för split-applicera-kombinera strategi som hjälper till i dataanalys. Mappning utförs av Mapper-klassen och minskar uppgiften av Reducer-klassen.
Förstå MapReduce Algoritm
MapReduce Algoritm fungerar huvudsakligen i tre steg:
- Kartfunktion
- Blandningsfunktion
- Minska funktionen
Låt oss diskutera varje funktion och dess ansvar.
1. Kartfunktion
Detta är det första steget i MapReduce-algoritmen. Den tar datauppsättningarna och distribuerar den till mindre deluppgifter. Detta görs vidare i två steg, delning och kartläggning. Uppdelning tar ingångsdatasatsen och delar upp datauppsättningen medan kartläggningen tar dessa underuppsättningar av data och utför den erforderliga åtgärden. Utgången från denna funktion är ett nyckelvärdespar.
2. Blandningsfunktion
Detta är också känt som kombinera-funktion och inkluderar sammanslagning och sortering. Sammanfogning kombinerar alla nyckelvärdespar. Alla dessa har samma nycklar. Sortering tar ingången från sammanslagningssteget och sorterar alla nyckelvärdespar genom att använda tangenterna. Detta steg kommer också att återgå till nyckelvärdespar. Utgången sorteras.
3. Minska funktionen
Detta är det sista steget i denna algoritm. Det tar nyckelvärdsparen från blandningen och minskar driften.
Hur gör MapReduce-algoritmer att arbeta enkelt?
De relationsdatabassystemen har en centraliserad server som hjälper till att lagra och bearbeta data. Dessa var vanligtvis centraliserade system. När flera filer kommer in i bilden är behandlingen tråkig och skapar en flaskhals medan flera filer bearbetas. MapReduce kartlägger uppsättningen av data och konverterar datauppsättningen där all data är uppdelad i tuples och reduceringsuppgiften kommer att ta ut resultatet från detta steg och kombinera dessa data-tupplar i de mindre uppsättningarna. Det fungerar i olika faser och skapar nyckelvärdespar som kan distribueras över olika system.
Vad kan du göra med MapReduce algoritmer?
MapReduce kan användas med en mängd olika applikationer. Det kan användas för distribuerad mönsterbaserad sökning, distribuerad sortering, weblink-grafvändning, statistik för åtkomstlogg på webben. Det kan också hjälpa dig att skapa och arbeta med flera kluster, skrivbordsnät, volontär datormiljöer. Man kan också skapa dynamiska molnmiljöer, mobila miljöer och även högpresterande datormiljöer. Google använde MapReduce som regenererar Google-indexet på webben. Genom att använda det uppdateras de gamla ad hoc-programmen och de har kört olika slags analyser. Den integrerade också live-sökresultaten utan att bygga om hela indexet. Alla in- och utgångar lagras i det distribuerade filsystemet. Den övergående datan lagras på en lokal disk.
Arbeta med MapReduce Algoritm
För att arbeta med MapReduce Algoritm, måste du veta hela processen för hur den fungerar. Uppgifterna som intas går igenom följande steg:
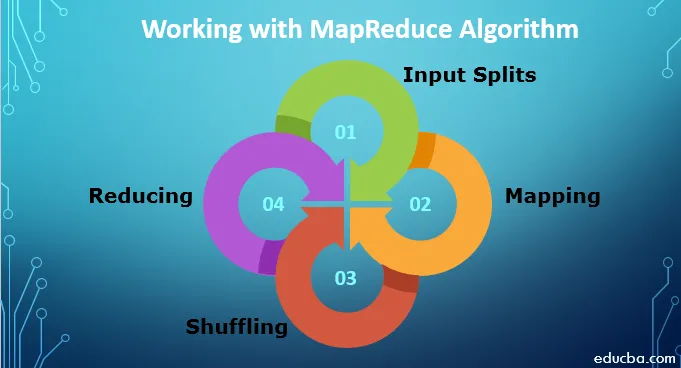
1. Ingångsdelningar: Alla inmatningsdata som kommer till MapReduce-jobbet delas upp i lika stora delar som kallas ingångsdelningar. Det är en del av ingången som kan konsumeras av någon av kartläggarna.
2. Kartläggning: När uppgifterna har delats upp i bitar går de genom kartläggningsfasen i kartminskningsprogrammet. Denna delade data överförs till mappningsfunktion som producerar olika utgångsvärden.
3. Blanda: När kartläggningen är klar skickas data till denna fas. Dess uppgift är att sammanfoga de obligatoriska dokumenten från föregående fas.
4. Minska: I denna fas aggregeras utgången från blandningsfasen. I denna fas blandas alla värden samman och sammanförs genom aggregering så att det returnerar ett enda utgångsvärde. Det skapar en sammanfattning av hela datauppsättningen.
Fördelar med MapReduce Algoritm
De applikationer som använder MapReduce har följande fördelar:
- De har försetts med konvergens och bra generaliseringsprestanda.
- Data kan hanteras genom att använda datakrävande applikationer.
- Det ger hög skalbarhet.
- Att räkna alla förekomster av varje ord är enkelt och har en massiv dokumentsamling.
- Ett generiskt verktyg kan användas för att söka i många dataanalyser.
- Det erbjuder lastbalanseringstid i stora kluster.
- Det hjälper också i processen att utvinna sammanhang för användarplats, situationer etc.
- Den kan komma åt stora prover av respondenter snabbt.
Varför ska vi använda MapReduce Algoritm?
MapReduce är en applikation som används för behandling av enorma datasätt. Dessa datasätt kan behandlas parallellt. MapReduce kan potentiellt skapa stora datamängder och ett stort antal noder. Dessa stora datamängder lagras på HDFS vilket gör analysen av data enklare. Det kan behandla alla slags data som strukturerade, ostrukturerade eller semistrukturerade.
Varför behöver vi MapReduce-algoritmen?
MapReduce växer snabbt och hjälper till vid parallell databehandling. Det hjälper till att bestämma priset för produkter och hjälper till att ge de högsta vinsterna. Det hjälper också till att förutsäga och rekommendera analys. Det gör det möjligt för programmerare att köra modeller över olika datamängder och använder avancerade statistiska tekniker och maskininlärningstekniker som hjälper till att förutsäga data. Det filtrerar och skickar ut data till olika noder inom klustret och fungerar enligt mapper- och reduceringsfunktionen.
Hur denna teknik kommer att hjälpa dig i karriärtillväxt?
Hadoop är bland de mest eftertraktade arbetena i dag. Det påskyndar hastigheten och möjligheten som växer mycket snabbt inom detta område. Det kommer att bli en boom ytterligare i detta område. IT-proffsen som arbetar i Java har ett pluspoäng eftersom de är de mest eftertraktade människorna. Dessutom kan utvecklare, dataarkitekter, datalager och BI-proffs ta bort enorma mängder lön genom att lära sig denna teknik.
Slutsats
MapReduce är det grundläggande i Hadoop-ramverket. Genom att lära dig detta kommer du säkert att komma in på dataanalysmarknaden. Du kan lära dig det noggrant och lära känna hur stora uppsättningar av data som bearbetas och hur denna teknik förändrar processen med att bearbeta och lagra data.
Rekommenderade artiklar
Detta är en guide till MapReduce Algoritms. Här diskuterar vi begreppet, förståelse, arbete, behov, fördelar och karriärtillväxt. Du kan också gå igenom våra andra föreslagna artiklar för att lära dig mer -
- MapReduce intervjufrågor
- Vad är MapReduce i Hadoop?
- Hur MapReduce fungerar?
- Vad är MapReduce?
- Skillnader mellan Hadoop vs MapReduce
- Olika operationer relaterade till tuples